3.1 : Relational Database Concepts
|
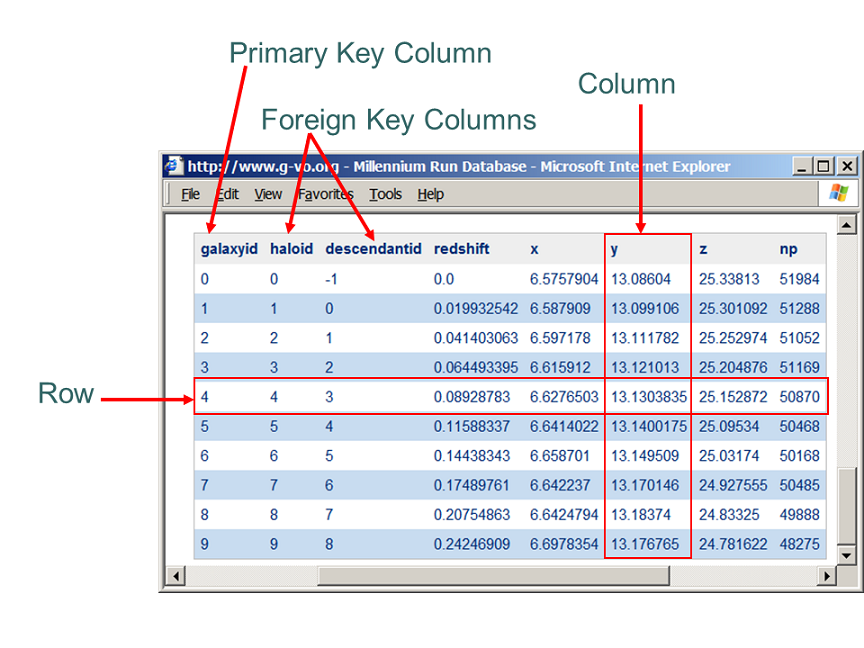
The subject of relational databases and their query language SQL is huge and here we will only give a very short summary. For more information see the references below. Tables and columnsThis web site gives access to multiple 'databases'. Each 'database' contains individual data sets that somehow belong together. In a relational database, such data sets are stored in tables (originally called "relations", hence the name). such as the one illustrated in the following figure.
Data about individual objects/items are stored in rows in the table. The information inside of a row is distributed over columns. These columns are defined at the table level, i.e. all rows in a given table have the same columns, though they need not all have values. Columns have a name and a fixed data type. In the documentation of the tables available through the web site, we list all columns with their data type a description and some other parameters. For an example see the description of the DeLucia2006a table in the millimil database in the public Millennium web site here. The definition of a table in terms of its columns is often called the 'schema' of the table. In the query language SQL described later one can query data from one or more tables. To refer to a table, one must use the name of the table. However the plain name of the table only has meaning in the context of the database that contains it. As the web site gives access to multiple databases one must qualify the name of the table. First one must specify the name of the database. In some cases the database is furthemore subdivided in so called 'schemas', a kind of sub folder, that allows one to have multiple tables of the same name in the same database. So the fully qualified name of the table is [databasename].[schemaname].[tablename]In most databases available through the website all tables are stored in the default schema called 'dbo'. To refer to tables stored in this schema one may leave out the schema name: [databasename..[tablename]For example the Millennium website gives access to a database named 'millimil' with tables such as DeLucia2006a and snapshots. One may refer to these tables as : millimil.dbo.DeLucia2006aor millimil..DeLucia2006aand millimil.dbo.snapshotsor millimil..snapshotsNote that the database is case-insensitive. Primary keysMost tables contain one or more columns that are meant to uniquely identify rows in the table. For each row the value(s) in the column(s) must be unique in the table. One calls this column or set of columns the primary key of the table. In the figure the table has a single primary key column,galaxyId.
Primary keys are important for the discussion of foreign keys below.
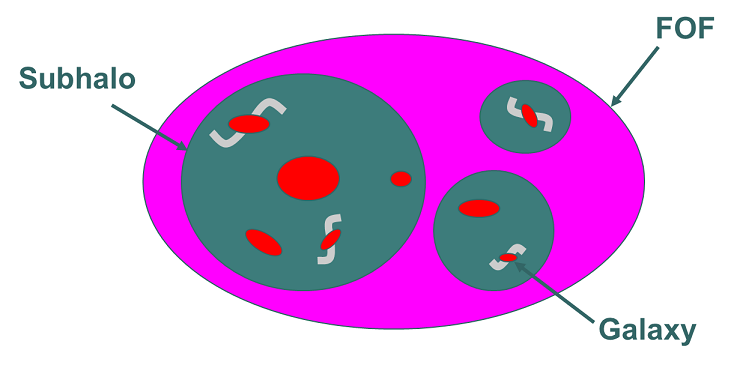
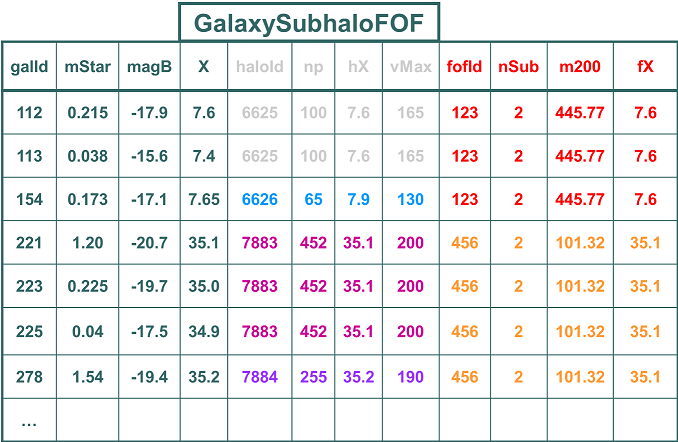
In the design of the Millennium database we apply various special purpose algorithms for assigning values to the different primary keys. Some should facilitate querying for tree structures, others give information on the snapshot an object belongs to. Details about the various algorithms can be found here. Foreign keysThe strength of relational databases lies in the way if facilitates joining information from data sets stored in different tables. Often data sets in differeent tables are related to each other. For example see the following figure that shows FOF groups, which contain (sub)halos, which contain model galaxies.
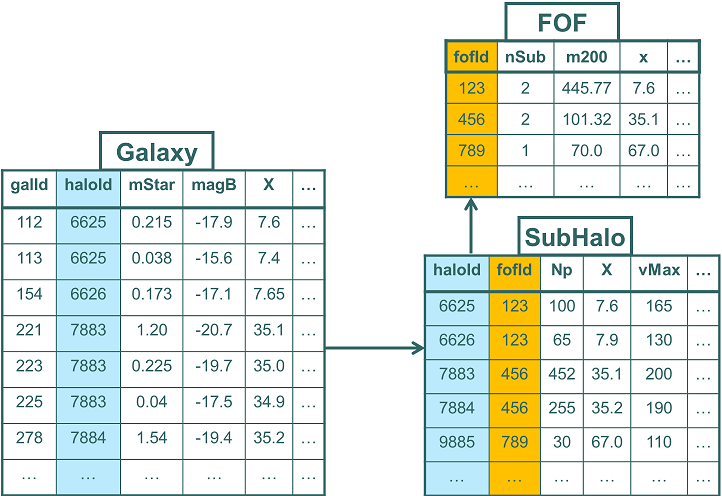
The problem with this is that there is a lot of redundancy. As individual FOF groups can contain multiple subhalos, and individual subhalos can contain multiple galaxies, to store all information in a single table means repeating subhalo information for all galaxies in the same subhalo, and even worse for the FOF group information. Instead when designing the structure of a relational database one generally aims to "normalize" the data model. Here one stores each individual data set in its own table and creates links between the tables representing the relationships. The following figure shows the normalized database design for the redundant table above:
In relational databases these links are referred to as foreign keys. They consist of one or more columns that identify an element in the target table. That element is generally identified through its primary key.
In the example in the figure above, the Galaxy table has a column,
select ...
from Galaxy g
join Subhalo sh
on g.haloId = sh.haloId
or in the alternative notation:
select ... from Galaxy g , Subhalo sh where g.haloId = sh.haloId References
|