3.2.3 : Storing Merger Trees
|
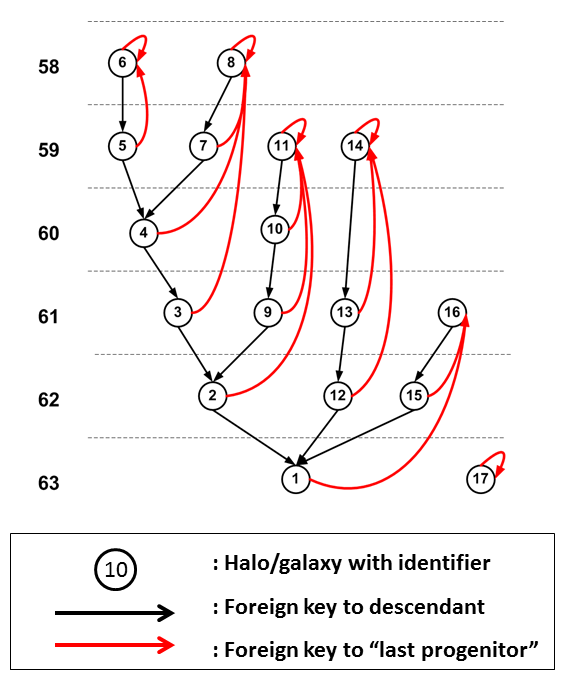
Many of the science questions that were used in the design of thhe database require retrieval of merger histories for dark matter halos and/or galaxies. A straightforward way to store a tree structure such as the merger trees here, where each halo has at most one descendant, is to create a foreign key from each halo to its descendant. Though this is the most explicit way to store the trees as well as the most efficient in terms of space requirements, the problem is that one requires recursive methods to retrieve information about a complete tree. While some database systems have explicit support for recursive queries, for example DB2, it will still be very inefficient, when the trees are deep, to retrieve them using such queries. To support efficient retrieval of complete trees rooted in a halo at the final output time, one might1 add a foreign key to each halo pointing to the final descendant in its tree in addition to the direct descendant. This however does not help us to retrieve trees rooted in halos at other timesteps, which is something we also want to be able to do. And it becomes very expensive to add foreign keys to each descendant at later times for all halos. Instead we have implemented an alternative model which provides very quick retrieval of complete trees, rooted in any halo, using completely standard SQL. The central idea is to store the nodes of a tree in the order they are visited in a depth-first search, starting with the root of a tree and following the descendant edges in opposite direction. The nodes of the tree (halos or galaxies) get unique integer identifiers that give the rank in the resulting sort added to the identifier of the root. This is illustrated in the following figure:
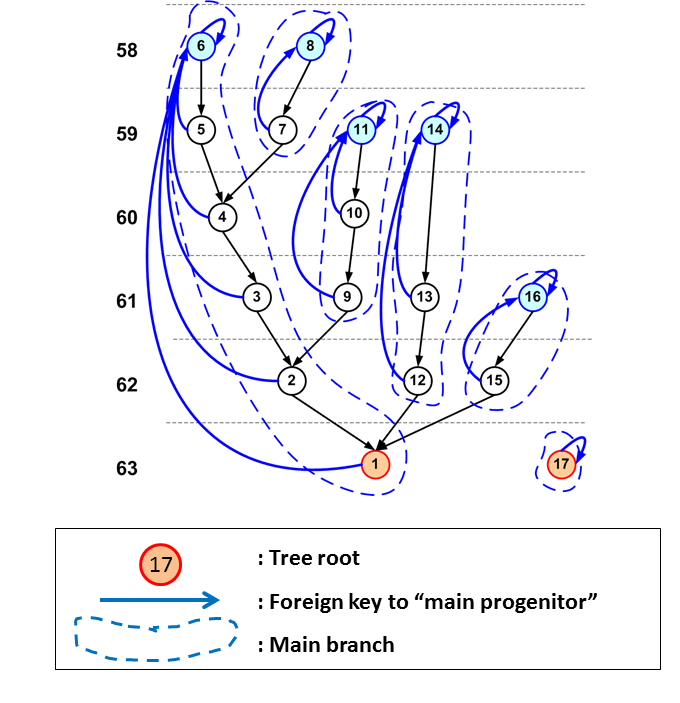
Every halo gets, in addition to the descendant foreign key, a foreign key pointing to the "last progenitor". The last progenitor is that progenitor that comes last in the sort. It is easy to see that this implies that the tree rooted in a certain node contains precisely those nodes with identifier values BETWEEN (in the SQL sense) the identifier of the root and that of the last progenitor. Query H2 on the query web page is an example of such a query: select PROG.* from millimil..MPAHalo PROG , millimil..MPAHalo DES where DES.haloId = 1 and PROG.haloId between DES.haloId and DES.lastprogenitorId To improve the efficiency of these retrievals we define an index on the identifier and order the table on disk acording to this index. This implies that the merger tree rooted in a certain tree node is located on disk directly following the node itself, which ensures very fast retrieval times, requiring only a few consecutive page reads. Especially in the Millennium-II simulation there are merger trees that have millions of nodes. To ask for the complete merger tree rooted in some node may therefore give very large results. Also, one is often not interested in all progenitors, but in "THE progenitor" of a halo/galaxy at an earlier time step. The merger trees extracted from the simulations often provide each object with one special progenitor, referred to as the "main" or "first" progenitor. Often this is the most massive progenitor, but sometimes the assignment is somewhat more complex2. In most merger trees stored in these databases this most important progenitor is indicated by a column named firstProgenitorId. When one follows the main progenitor pointers until the end, one traces the "main branch". The halos on the main branch can be considered as "the progenitor" of a certain halo. In the following figure main branches are outlined by the dashed lines. To find all the halos on a main branch between a halo and the branche's leaf we give each halo a pointer to the leaf on the branch it is on, indicated by the blue arrow in the figure. The column storing this pointer is generally called mainLeafId. It turns out that to find all main progenitors of a given halo, one needs precisely those halos with id between its haloId and its mainLeafId. This works because when assigning the halo identifiers using the depth first ordering described above, we have made sure that we always first follow the pointer to the main progenitor, before recursing to the other progenitors.
This feature is not yet implemented for the millimil merger trees. But with a little rewriting, the following query will give us all the main progenitors of the halo with id=1, including the halo itself: select PROG.* from MPAHaloTrees..MR PROG , MPAHaloTrees..MR DES where DES.haloId = 1 and PROG.haloId between DES.haloId and DES.mainLeafIdAn interesting fact of our tree indexing schema is that one can obtain the mainLeafId for a millimil halo using a query like the following: select des.haloid, min(PROG.lastProgenitorId) as mainLeafId from millimil..MPAHalo PROG , millimil..MPAHalo DES where DES.haloId = 1 and PROG.haloId between DES.haloId and DES.mainLeafId group by des.haloidWe leave it as an exercise to the reader to prove this. Some more details of merger trees can be found in this page. 1 Note that the tables in the MPAHaloTrees database do have a pointer like this, namely the treeRootId.2 See for example DeLucia & Blaizot (2007) for the algorithm that has decided on the main progenitor assignment in MPA HaloTrees. |