
|
0 : Index | |
|
|
1 : Website overview
| (top) (separate page) |
|
This website comes in two flavours, a public and a protected one.
The public web site gives access to all the information about the Millennium database products,
but only gives query access to a small version of this simulation, the so-called milli-Millennium (millimil).
The protected site requires an account. How to acquire such an account see
here.
To gain access to the rest of this documentation follow the buttons or go to the Table of Contents.
|
1.1 : Registration
| (top) (separate page) |
|
To register for an account allowing access to the protected part of the Millennium database
please send an email to j.c.helly at durham.ac.uk.
Please provide us with some information about you, especially about your affiliation and your intended use.
The reasons we protect the main database from public access are various.
First is simply a question of resources.
It is very easy for users, even if experienced ones, to submit queries that use
up all the resources of the database server for a long time. This is especially true for the
main database, which is about 512 times larger than the milli-Millennium database to which the
public site gives access.
For this same reason we have as yet not set up an automated registration mechanism.
On the one hand we want to prevent the other users from frivolous usage by some,
which is why we would like some indication of affiliation.
But we also hope to gain experience with the usage patterns by external users not directed associated to the
Virgo project. This may allow us to tune the database to those potentially very different requests.
|
1.2 : Credits
| (top) (separate page) |
|
You are welcome to use the simulation data in these pages for your own scientific purposes
without further consultation with the Virgo Consortium or the scientists who generated them.
If you do so we would appreciate it if you include a reference to the paper announcing the database:
If you use the data in a publication or proposal, please cite the appropriate paper(s):
If you use galaxy data, then you should in addition cite the papers which describe the specific model underlying these data.
For the MPA models these papers are:
-
De Lucia G. & Blaizot J. 2007 (MNRAS 375, 2; also Croton D. et al. 2006 MNRAS 365, 11)
for the DeLucia2006a and DeLucia2006a_SDSS2MASS tables in both the millimil and MPAGalaxies databases,
-
Bertone, De Lucia and Thomas 2007
(MNRAS 379, 1143)
for the Bertone2007a table in the MPAGalaxies database.
-
Guo etal 2011
(MNRAS 413, 101)
for all the tables in the Guo2010a database.
-
Guo et al. 2013,
(MNRAS 428, 1351)
for all the tables in the Guo2013a database and the MR7, MRscWMAP7 and MRIIscWMAP7 tables in the MPAHalotrees database.
For the Durham model the relevant paper is Bower R. et al. 2007 (MNRAS 370, 645; also Benson A. et al. 2003 ApJ 599, 38 and Cole S. et al. 2000 MNRAS 319, 168).
If you use mock galaxy catalogues in MPAMocks or Henriques2012a, please look at the documentation for the specific datasets
for possible additional credits.
In order to acknowledge GAVO's support in constructing this database
facility, we would appreciate inclusion of the following sentence in
the `Acknowledgements' section of papers which make significant use of
our databases:
"The Millennium Simulation databases used in this paper and the web
application providing online access to them were constructed as part
of the activities of the German Astrophysical Virtual Observatory (GAVO)."
(replace "Millennium" with "Millennium-II" or add "Millennium-II" if appropriate)
The particular structure of the database design which allows efficient querying for merger trees is
described in:
Lemson G. & Springel V. 2006, Astronomical Data Analysis Software and Systems XV,
ASP Conference Series, Vol. 351, 212, C. Gabriel, C. Arviset, D. Ponz and E. Solano, eds.
|
1.3 : Latest news
| (top) (separate page) |
2013-02-26: Upgrade Millennium database hardware and new data sets
The database server was upgraded and new databases have been added to the site.
In particular we have added data sets based on the WMAP7 cosmology. These are described
in Guo et al. 2013, and
contain a new version of the Millennium simulaiton itself, run with WMAP7 parameters and scaling versions of
the existing Millennium and Millennium-II simulations.
We present halo merger trees and galaxy catalogues produced with the MPA semi-analytical code L-Galaxies.
2012-12-21: Slides form Millennium workshop
The workshop was held in Garching in December and slides are available on the
program page.
2012-08-29: 500 publications using Millennium data
In honour of reaching 500 publications
using Millennium related data, we are organising a workshop end of this year.
Please read the workshop announcement here,
which includes information about pre-registration possibilities.
2012-08-09: Migration databases
We have completed the migration of the Millennium databases and the web applications to their new location.
Note that the URL to the Millennium database will NOT change, it still is
http://gavo.mpa-garching.mpg.de/MyMillennium
We will keep a version of the old web site+database available under http://gavo.mpa-garching.mpg.de/MyMillennium_old
Note that your mydb will remain read-only on the old site.
You may wish to compare the two sites, in particular the private databases that you have access to.
We have decided not to migrate all these databases. If you think some are missing on the new site
(but still exist on MyMillennium_old) and you would like to keep accessing these please send me an email.
Also if you think that the contents of your mydb-s has changed please let us know.
We have attempted to copy all the non-empty databases, but recreated the empty ones.
2012-01-17: New databases with lightcones
This afternoon around 4PM (German local time) we will update the Millennium Database and web site.
We will add a new database with the light cone catalogues used in the recent paper by
Henriques et al (astro-ph:1109.3457), built from the semi-analytic model of Guo et al. 2011.
The new database will be named Henriques2012a.
After the update is complete you will see the new database listed under the "Public databases"
section on the left menu bar of the web page. The link leads to the documentation pages for this database.
Note that not all individual tables will be listed in the menu, as there are ~100 of them.
Please let me know if the documentation is not clear.
We have also taken this opportunity to move the web application to a newer server and to rename it back
from MyMillennium3 to MyMillennium. The old address will be usable for a little while longer, but will
redirect you to the new web app. The full address will therefore be:
http://gavo.mpa-garching.mpg.de/MyMillennium
20??-??-??: missing news items
TBD
2011-03-18: New addresses for Millennium databases
Over the coming weekend the central web server of GAVO is being relocated from Munich to Heidelberg.
Also the www.g-vo.org domain is moved.
The old http://www.g-vo.org/MyMillennium3 and http://www.g-vo.org/Millennium addresses will remain valid,
but you will be redirected to the new address
http://gavo.mpa-garching.mpg.de/MyMillennium3 etc,
which you may notice in the address bar of you web browser.
When using wget or TOPCAT you should not notice anything. You could of course directly start using the
gavo.mpa-garching.mpg.de based address iso the www.g-vo.org based one.
20??-??-??: missing news items
TBD
2009-05-01: New release of Millennium website and databases
We have moved the Millennium databases to a new, more secure database server.
At the same time we have slightly updated the web site. We here list the main changes to the system:
-
Millennium-II database
As announced here the FOF groups, subhalo-s and subhalo merger trees from
the Millennium-II simulation are now available in the
MillenniumII database.
-
Change to the comma-separated values format of streaming queries
We have made a change to the CSV format that is returned by the "Query (stream)" button on the web page,
and which also it the data format that will be returned when using
wget.
In the old version of the web site the end of the file was either an error message in case a timeout happened,
or simply the last row of data. The problem with this is that in case the timeout is not captured by the web server,
for example because a connection between the client and the web server times out or breaks, there is no guarantee
that the result is complete.
If a result is completely returned without problems there will be an extra row at the end of the result that reads
#OK
If this line is not there, and also no block of text starting with
#ERROR
this indicates that users can not be assured that the result is complete.
Note that this may cause some problems for client code that was built to deal with the old result type.
In particular the TOPCAT visualisation tool may have to be upgraded.
The TOPCAT programmer has produced a version that handles this correctly, though then it will always give a warning with
the old web sites.
New MyDB-s have been created for all registered users.
They have been notified of ways to retrieve the data from the old web sites.
FAQ
Pages with frequently asked question have been added.
Please feel free to ask us any question that is not yet asked or adequately anseewered there!
2009-03-18: Preparations for Millennium-II Simulation data
A new and complementary simulation to the Millennium Simulation, the
Millennium-II Simulation, has recently been completed. The data will be
added to this site in the next few weeks; much of the documentation for the
Millennium-II has already been added to this site (see the simulation
page on this site or the Millennium-II
homepage for details on the Millennium-II Simulation). Registered database
users will receive an email once the Millennium-II data are available at this site.
2008-04-029: Fix to Delucia2006_sdss2mass table
While investigating the MPAGalxies..DeLucia2006a_SDSS2MASS table
we discovered that the H_2MASS and J_2MASS columns had been
swapped. I.e. the values for H were stored in column J_2MASS and vice versa.
The same was true for the DeLucia2006a_sdss2mass table in the millimil
database.
The 2MASS magnitudes in the Blaizot2006... mock catalogs in the
MPAMocks database are correct.
The mismatch has now been fixed on our side, i.e. J_2MASS copntains J and
H_2MASS contains H.
2007-07-05b: Fixes and updates to the documentation
- On page, the unit of
np is Msun/h, not Msun.
- The page on spatial indexing has been extended with a more complete description
of how to use the spatial "zone" indexes, ix/iy/iz in the various tables.
2007-07-05a: updates to the database
Two new tables were recently added to the
MField database
available to registered users through the MyMillennium website.
These are FOF
and FOFSubHalo.
The former contains the friends-of-friends groups that were the first post-processing
products of the Millennium simulation. The second stores information about all the subhalos
derived form the FOF clusters using the SUBFIND algorithm. From these subhalos
are derived the subhalo merger trees that are stored in the MPAHalotress..MHalo table.
The subhaloID in the latter table points to the subhaloId column in MField..FOFSubhalo
and allows one to join from the MPAHalotress..MHalo to the FOF table through the fofId
in the FOFSubhalo table.
2007-02-05b: Tutorial on Millennium database
Upon request a tutorial presentation has been put on this site. It can be downloaded as a Microsoft power-point from
this link.
2007-02-05a: Mock all-sky SDSS/2MASS catalogues corrected
The Blaizot 2006,
all-sky SDSS & 2MASS catalogues in the MPAMocks database have been updated and corrected
for a mistake in the parameter file used to create them. The
cosmological parameters differed slightly from those used in the Millennium simulation itself (
namely Ωλ/Ωm/h = 0.7/0.3/0.7 instead of 0.75/0.25/0.73).
This latter mistake leads to a significant change in the mocks (mostly in terms of
counts and redshift distribution). Please discard results obtained with the previous versions.
Note also that the unique "ObjID" of galaxies in the new mocks are now assigned in a
random way and can be used to select random sub- samples efficiently (e.g. as with the
"random" field from the table DeLucia2006a).
2007-01-23b: TOPCAT plug-in available
The webpage on TOPCAT now really gives
a link to the plug-in that allows one to use this tool to query the Millennium/GAVO databases.
2007-01-23a: MPAGalaxies and Durham back online
After a problem with the system, the MPAGalaxies and Durham databases were unavailable.
They have been rebuilt from scratch and are available again. The velocities in
the MPAGalxies..DeLucia2006a table have also again been corrected for the problem
identified in 2007-1-12.
2007-1-13b: New mock catalogues in MPAMocks.
We have added new mock catalogues in the MPAmocks database.
This dataset contains 6 all-sky mock catalogues (tables Blaizot_AllSky_RT_x, with x = 1-5 and Blaizot_AllSky_PT_1).
They are all limited at an apparent AB magnitude of 18 in the r filter from SDSS, in an attempt to
reproduce (with some margin) the SDSS spectroscopic selection. The catalogues include apparent magnitudes
in the 8 filters from both SDSS and 2MASS (namely u,g,r,i,z,J,H, and K).
For a further description of this data set and some example queries see
the documentation.
Note, these catalogues have been corrected for the peculiar velocity errors noted in news item 2007-1-12.
This is true both for the line-of-sight velocity and apparend redshift of the observed galaxy,
and for the velocities of the underlying galaxy. However, this correction was performed after the catalogues
were created. This implies that the K-corrections used in determining the apparent luminosities were performed with the old,
wrong values for the line-of-sight velocities. This effect is estimated to be very small, but these catalogues
will be replaced with the rigorously correct luminosities as soon as possible.
2007-1-13a: Problems with peculiar velocities for type 2 galaxies corrected
We have corrected the problems decribed in item 2007-1-12 with the peculiar velocities of the type 2
galaxies in millimil..DeLucia2006a and MPAGalaxies..DeLucia2006a. We have also corrected the line of apparent redshift in
the Kitzbichler pencil beams catalogues in MPAMocks. To this end we needed to add two columns to the table.
More importantly, we did not correct the apparent luminosities. Formally thois would have to be done as well to take into
account the slightly different K-correction. This effect is likely very small and can be ignored.
2007-1-12: Problems with peculiar velocities for type 2 galaxies
An error has been found regarding peculiar velocities for type 2 galaxies in the
MPAGalaxies.DeLucia2006a.
table, and the corresponding table in the millimil database. For these tables, the peculiar velocities
(velX, velY and velZ) for galaxies with type=2 should be multiplied by a factor 1/sqrt(1+redshift) to
get the correct values. This problem also affects the
Kitzbichler catalogues in MPAMocks,
though in a less direct manner (apparent redshifts and (very) slightly different k-corrections).
We will update the affected databases, but will need to bring them offline. We will add a news item when this has been fixed,
until then it will be simple to correct for this in the DeLucia2006a tables in the indicated manner.
We appologise for this error.
2006-10-31: New: mock catalogues in database.
We have created a new database which will contain mock observational galaxy catalogues
created by "virtually observing" the semi-analytical galaxy catalogues.
This database is accessible to users with an account to the
MyMillennium website. The first dataset contains 6 pencil beams based on
MPAGalaxies.DeLucia2006a.
They are the results of work published in
Kitzbichler & White (2006), astro-ph/0609636.
For a further description of this data set and some example queries see
the documentation.
Future mock catalogues will be published in this same database.
2006-10-20: Fixes in the database and web site.
Two errors were fixed in the database and web site.
First, the I and R-band magnitudes in the MPAGalaxies..DeLucia2006a table (available only on the MyMillennium website)
were interchanged. The columns containing the I-band data, were named with R (mag_r, mag_rDust and mag_rBulge),
and vice versa. This was fixed. This problem did not occur in the millimil..DeLucia2006a table.
Second, the documentation for the DeLucia2006a_SDSS2MASS tables in the millimil and MPAGlaxies databases
mistakenly said that they contained Vega magnitudes. They are actually AB magnitudes.
The documentation has been fixed
2006-09-26: SDSS and 2MASS magnitudes for MPAGalaxies.
A new table has been added to the MPAGalaxies database.
This table contains observer frame magnitudes for the SDSS and 2MASS bands.
It must be viewed as an addendum to the main table,
DeLucia2006a.
It can be linked to that table through the galaxyId column.
For the schema of this table see
this link.
A version of this same table for the milli-Millennium simulaiton has been added to the corresponding database.
|
2 : Data sets
| (top) (separate page) |
|
The table on this page lists all the databases and tables available to registered users.
A short description of their contents and links to pages with more detailed information are provided.
| Raw data |
|---|
| Simulation particles |
|---|
| MMSnapshots..MillimilSnapshots
| Particles from millimil simulation |
| Density fields |
|---|
| millimil..MMField |
millimil density field, 323 cells, + smoothing |
| MField..MField |
Millennium density field, 2563 cells, + smoothing |
| Halo catalogues |
|---|
| Friends-of-friends (FOF) groups |
|---|
| millimil..FOF |
millimil FOF groups |
| MField..FOF |
Millennium FOF groups
| | MillenniumII..FOF |
Millennium-II FOF groups
| | SUBFIND subhalos |
|---|
| millimil..fofsubhalo |
links between millimil subhalos and FOF groups, for information about details subhalos see millimil..MPAHalo.
| | MField..fofsubhalo |
Subhalos with pointer to containing FOF groups, for information about details subhalos see millimil..MPAHalo.
| | Halo-particle links |
|---|
| MMSnapshots..MillimilSnapshotIds |
links between particles and FOF groups and Subahlos () |
| Halo merger trees |
|---|
| SUBFIND merger trees |
|---|
| millimil..MPAHalo |
SUBFIND subhalo merger trees from millimil simulation.
| | MPAHaloTrees..MHalo |
SUBFIND subhalo merger trees from Millennium simulation.
| | miniMilII..HaloTree |
SUBFIND subhalo merger trees from mini-Millennium-II simulation.
| | MillenniumII..HaloTree |
SUBFIND subhalo merger trees from Millennium-II simulation.
| | MPAHaloTrees..MR |
SUBFIND subhalo merger trees from Millennium simulation,
updated version of MPAHaloTrees..MHalo |
| MPAHaloTrees..MRII |
SUBFIND subhalo merger trees from Millennium-II simulation,
updated version of MillenniumII..HaloTree |
| MPAHaloTrees..MR7 |
SUBFIND subhalo merger trees from Millennium-WMAP7 simulation |
| MPAHaloTrees..MRscWMAP7 |
SUBFIND subhalo merger trees from Millennium simulation, scaled to WMAP7 cosmology. |
| MPAHaloTrees..MRIIscWMAP7 |
SUBFIND subhalo merger trees from Millennium-II simulation,
scaled to WMAP7 cosmology. |
| Durham (D)Halo merger trees |
|---|
| DHaloTrees..DHalo |
Durham halo merger trees from Millennium simulation. |
| DHaloTrees..DSubHalo |
Link between Durham halo merger trees and SUBFIND subhalos. |
| Semi-analytical galaxy catalogues |
|---|
| MPA model: L-Galaxies |
|---|
| MPAGalaxies..DeLucia2006a |
Galaxy merger trees run with L-Galaxies on millimil halo trees in as described in
DeLucia & Blaizot (2007). |
| MPAGalaxies..DeLucia2006a |
Galaxy merger trees run with L-Galaxies on Millennium halo trees in as described in
DeLucia & Blaizot (2007). |
| MPAGalaxies..Bertone2007a |
Galaxy merger trees run with L-Galaxies on Millennium halo trees in as described in
Bertone etal (2007). |
| Guo2010a..mMR |
Galaxy merger trees run with L-Galaxies on millimil halo trees in as described in
Guo etal (2011). |
| Guo2010a..MR |
Galaxy merger trees run with L-Galaxies on Millennium halo trees in as described in
Guo etal (2011). |
| Guo2010a..MRII |
Galaxy merger trees run with L-Galaxies on Millennium-II halo trees in as described in
Guo etal (2011). |
| Guo2010a..mMRII |
Galaxy merger trees run with L-Galaxies on mini-Millennium-II halo trees in as described in
Guo etal (2011). |
| Guo2013a..MR |
Galaxy merger trees run on original
Millennium halo trees with L-Galaxies version described in
Guo etal (2013). |
| Guo2013a..MRII |
Galaxy merger trees run on original
Millennium-II halo trees with L-Galaxies version described in
Guo etal (2013). |
| Guo2013a..MR |
Galaxy merger trees run on
Millennium-WMAP7 halo trees with L-Galaxies version described in
Guo etal (2013). |
| Guo2013a..MRscWMAP7 |
Galaxy merger trees run on
Millennium halo trees scaled to WMAP7 cosmology with L-Galaxies version described in
Guo etal (2013). |
| Guo2013a..MRIIscWMAP7 |
Galaxy merger trees run on
Millennium-II halo trees scaled to WMAP7 cosmology with L-Galaxies version described in
Guo etal (2013). |
| Durham model: GalForm |
|---|
| DGalaxies..Bower2006a |
Galaxy merger trees run with GalForm on Millennium halo trees in as described in
Bower etal (2007). |
| Light-cone catalogues |
|---|
MPAMocks..Kitzbichler2006a - MPAMocks..Kitzbichler2006f
MPAMocks..Kitzbichler2006a_Johnson - MPAMocks..Kitzbichler2006f_Johnson
MPAMocks..Kitzbichler2006a_SDSS - MPAMocks..Kitzbichler2006f_SDSS
|
1.4ox1.4o Light-cone "mock" catalogues as described in
Kitzbichler & White (2007).
Based on semi-analytics catalogue in MPAGalaxies..DeLucia2006a |
MPAMocks..Blaizot2006_AllSky_PT_1 (periodic)
MPAMocks..Blaizot2006_AllSky_RT_1 - MPAMocks..Blaizot2006_AllSky_RT_5 (random shifts)
|
6 all-sky light-cone catalogues created using the MoMaF algorithm of Jeremy Blaizot described in
Blaizot etal (2005).
Based on semi-analytics catalogue in
MPAGalaxies..DeLucia2006a.
Depth comparable to the spectral sample in SDSS. |
| MPAMocks..Cosmos_012_000 etc |
24 1.4ox1.4o Light-cone "mock" catalogues as described in
Kitzbichler & White (2007).
The semi-analytics catalogue on which these cones are based ar NOT in the database.
These cones have been used by the COSMOS collaboration in various papers. |
| Henriques2012a |
Database with 2x24 1.4ox1.4o pencil beam and 2 all-sky light-cone "mock" catalogues as described in
Henriques etal (2012).
Based on semi-analytics catalogue in Guo2010a..MR.
Catalogues exists for different stellar population synthesis models. |
|
2.1 : Simulations
| (top) (separate page) |
|
This site makes the results of a suite of simulations available to the public.
The first of these is the Millennium Simulation, performed by Volker Springel (MPA)
using a specially customized version of the GADGET-2 simulation code. See
Springel etal (2005).
The second is the Millennium-II Simulation, perfomed by Mike Boylan-Kolchin (MPA)
using Volker Springel's GADGET-3 code. See
Boylan-Kolchin etal (2009).
Both are pure dark matter simulations in a periodic cube using 10,077,696,000 simulation particles.
The main differences between the two are the size of the box (500 Mpc/h for Millennium,
100 Mpc/h for Millennium-II), the force resolution (Plummer-equivalent softening of 5 kpc/h for Millennium,
1 kpc/h for Millennium-II), and the particle mass (8.6 x 108 Msun/h for Millennium,
6.9 x 106 Msun/h for Millennium-II).
A smaller version of the Millennium Run, the milli-Millennium Simulation, is also available on this site.
This simulation used the same cosmology and resolution as the Millennium Simulation but in a 62.5 Mpc/h box with
19,683,000 particles. A smaller version of the Millennium-II, the mini-Millennium-II was run as well.
It had the box size of the Millennium-II, the mass resolution of the Millennium and used the same initial condiftions Forier modes as
Millennium-II.
Peter Thomas has run a WMAP7 version of the Millennium run, which will be referred to as MR7 in much of this web site.
Details of this simulation are described in
Guo etal (2013)
where is is refered to by the name MS-W7.
The linear phases used for the MR7 initial conditions are taken from Panphasia -
the public multi-scale Gaussian white noise field described in
Jenkins 2013.
The phases for the MR7 simulation are published in table 6 of
Jenkins 2013, where the name MW7 is used.
The parameters for the various simulations are listed in the first table below.
Note that we add a "Code" name for each simulation that is used for table names in various places.
For example halo merger trees derived form the simulations and stored in the database
MPAHalotrees uses these shorthand names.
Similarly for galaxy catalogues derived from these in
Guo2013a.
| Code |
Name |
Ωm = Ωdm+Ωb |
Ωb |
ΩΛ |
h = H0/100 km/s/Mpc |
ns |
σ8 |
Np |
mp (Msun/h) |
L (Mpc/h) |
ε (kpc/h)
Plummer-equivalent force softening |
| MR |
Millennium |
0.25 |
0.045 |
0.75 |
0.73 |
1 |
0.9 |
21603 |
8.61 x 108 |
500 |
5 |
| mMR |
milli-Millennium (millimil) |
0.25 |
0.045 |
0.75 |
0.73 |
1 |
0.9 |
2703 |
8.61 x 108 |
62.5 |
5 |
| MRII |
Millennium-II |
0.25 |
0.045 |
0.75 |
0.73 |
1 |
0.9 |
21603 |
6.88 x 106 |
100 |
1 |
| mMRII |
mini-Millennium-II (miniMilII) |
0.25 |
0.045 |
0.75 |
0.73 |
1 |
0.9 |
4323 |
8.61 x 108 |
100 |
5 |
| MR7 |
Millennium-WMAP7 |
0.272 |
0.0455 |
0.728 |
0.704 |
0.967 |
0.81 |
21603 |
9.31 x 108 |
500 |
5 |
The second table contains entries that do not represent real simulations, but are scaled versions of
a real simulation indicated by its code in the "Original simulation" column.
Using the scaling algorithm from
Angulo & White (2010)
one can approximate catalogues as they would have
been obtained had the simulation been run with a different cosmology.
| Code |
Original Simulation |
Ωm |
Ωb |
ΩΛ |
h |
ns |
σ8 |
mp (Msun/h) |
L (Mpc/h) |
| MRscWMAP7 |
MR |
0.272 |
0.0455 |
0.728 |
0.704 |
0.967 |
0.81 |
1.063 x 109 |
521.555 |
| MRIIscWMAP7 |
MRII |
0.272 |
0.0455 |
0.728 |
0.704 |
0.967 |
0.81 |
8.5024 x 106 |
104.3110 |
|
2.2 : Semi Analytical Models
| (top) (separate page) |
|
The galaxy catalogues that are stored in the Millennium database are the products of
two separate, independent semi-analytical algorithms for galaxy formation: L-galaxies at the MPA
and GalFormat the ICC Durham. The pages linked to in the list above summarise these algorithms,
paying particular attention to the
the different definitions of the halo merger trees used as the sekeletoin on which the algorithms work.
These differences are reflected in the distinct data models to store them and special care must be taken to
make comparisons between them as will be discussed elsewhere.
For more details about the semi-analytical galaxy formation algorithms used for the published catalogues
and their results following main references:
For L-Galaxies: Croton2006a
and DeLucia2006b,
For GalForm: Bower2006.
|
2.2.1 : SAM at MPA: L-Galaxies
| (top) (separate page) |
|
The merger tree structure of halos extracted from the raw simulation results,
is used as the skeleton for semi-analytical models (SAMs) of galaxy formation, from
which synthetic galaxy catalogues are constructed. Here the SAGF algorithm is described
in terms of the actual, file-based, simulation products.
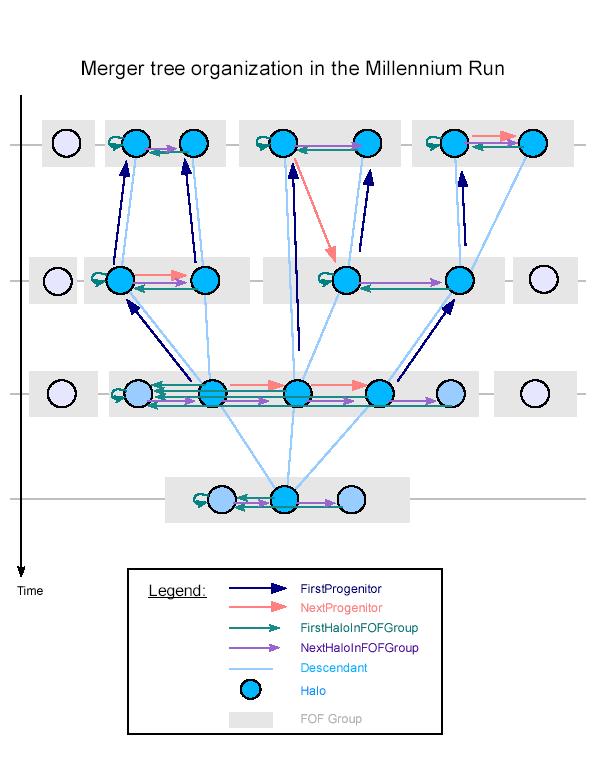
The postprocessing of the Millennium simulation data
proceeds in several stages. The first step is the determination of friends-of-friends
(FOF) groups, which is done by the simulation code itself.
The second step involves running an algorithm that
decomposes each FOF group in a set of gravitationally bound (sub)halos and determines
physical properties for them. These halos are the actual objects that are then used to
construct merging trees.
The merger tree construction itself involves two steps. The first step is a determination
of a descendant halo for each halo. The descendant always lies in the future, in >99.9%
of the cases in the subsequent output, but in certain situations, an output may also be
skipped. The descendant information already uniquely defines the merger tree of the whole
simulation. However, in order to simplify further processing, the merger tree is
reorganized in a further step such that distinct pieces of the tree (corresponding
to merger trees of halos found at the final time) are stored separately, in a form
that makes it convenient to walk these trees. These trees also contain all the physical
properties of the corresponding halos, such that they form the only input required to
run the semi-analytic galaxy formation code on them.
The construction of the galaxies is done by walking the merger tree more or less
in a depth-first fashion by calling the function construct_galaxies() recursively. This
function forms the backbone of the program. It first constructs the galaxies of all the
progentitors of the present halo. These galaxies are then combined
(join_galaxies_of_progenitors())and
evolved forward in time by the function evolve_galaxies(),
such that once the function finishes, we will have obtained the galaxies
for the halo that was passed as an argument. All the details of the modelling of the galaxy
formation process are contained in the two functions join_galaxies_of_progenitors() and
evolve_galaxies(). The walk of the merger tree encapsulated in
construct_galaxies() should
be pretty generic and essentially independent of any detail of the galaxy formation model itself.
Note again that in all of the above, the word "halo" refers to a generalized concept of
`subhalo', i.e. physically a subhalo may represent an embedded substructure within a
larger halo, or a `background halo' that hosts substructures itself. When we follow
subhalos over time it is not important to know these geometrical differences. All that
matters is that each subhalo carries one or several galaxies, and that these galaxies
should be associated with the descendant subhalo at the future output. So subhalos can
be treated all on the same footing, and its perhaps best to think of them as a generic
object, a "halo".
There is however one exception to this. Certain subhalos are given a special meaning,
based on a secondary grouping criterion. This grouping makes reference to the two-stage
group identification that we do: We first decompose the particle set into FOF groups,
and then each FOF group is decomposed into its constituent subhalos. As explained above,
the merger trees are built for the total set of subhalos found in this way, without
making any reference to the FOF groups. However, in the physical modelling of galaxy
formation, we use the FOF information at one place: We assume that only the biggest
subhalo in a FOF group receives fresh cool gas dropping out due to radiative cooling.
This basically means that in our merger tree we somehow need to know which halos belong
to the same FOF-group, so that we can select the biggest one of them as the "main halo"
of the group - this is then the one which will receive the cooling gas.
The above then introduces a complication in the recursive construction of the galaxies.
Because the physical model for the cooling rate of gas (needed when the galaxy population
of a halo is evolved in time) starts out with an inventory of all the baryons in a given
FOF-group, one needs to know the present state of all the galaxies in a given FOF group
to compute this... This means that one cannot simply construct the galaxies just
based on the merger tree of a given subhalo, because for working out the cooling rates,
one may also need information from halos that are only linked to the present tree by a
weaker relation of the form that they are part of some of the FOF halos under consideration.
One therefore needs to ensure that galaxies of all halos in a given FOF group are already
constructed when it comes done to computing the cooling rates.
The above issues are resolved by walking the tree in a slightly more complicated way,
and by temporarily storing all the galaxies that have been constructed for a given
halo in memory.
The recursive walk to construct the galaxies is augmented by the following
additional check. After we call construct_galaxies() for all progenitors of a given
halo, we check whether all the galaxies have already been constructed
for the FOF group. If not, we loop over all the subhalos in the same FOF group and call
construct_galaxies() for them if they have not already been processed. That way,
we are sure that before join_galaxies_of_progenitors() is called for the present
halo, the galaxies for its main halo have already been constructed.
|
2.2.2 : SAM at Durham: The Bower et al Model
| (top) (separate page) |
Halos and Merger Trees
The halo merger trees for the Bower et al model are contained in
the DHalo and DSubhalo tables.
The merger trees are built using the Friends of Friends (b=0.2) groups
output by L-Gadget2 and the subgroups identified by SubFind. In
the description below 'subhalo' means a set of particles grouped
together by SubFind, which looks for gravitationally bound local
density maxima. A 'halo' is a collection of subhalos grouped
together in the following way:
Initially subhalos are grouped into halos by looking at the FoF groups
- a halo just consists of all the subhalos belonging to one FoF
group. Particles in the FoF group which do not belong to any
subhalo are discarded. Note that SubFind identifies the
background mass distribution of the halo as a separate subhalo, so each
halo will normally contain one large subhalo (with most of the
mass of the halo) and a set of smaller "satellite" subhalos.
The Friends of Friends algorithm often links together objects which
should probably be treated as separate halos as far as the merger
trees are concerned. So under certain conditions a subgroup may
be split from its parent halo and considered to be a halo in its
own right. This is done if 1) the subhalo is outside twice the
half mass radius of the parent halo or 2) the subhalo has
retained 75% of the mass it had at the last output time where it
was an independant halo. This second condition is based on the
assumption that a halo which has fallen into a more massive halo
will rapidly be stripped of its outer layers, whereas a halo
which has been artificially linked to another halo will retain
its mass. When a subhalo is split off, any less massive subhalos
within twice its half mass radius are also split off and become
part of the new halo.
The descendant of a subhalo is found by following the most bound
10% of its mass or the 10 most bound particles, whichever is the
greater mass. The descendant is the subhalo which contains the
largest number of these particles. The descendant of a halo is
the halo which contains the descendant of the most massive
subhalo in the halo.
We refer to the halos defined in this way as "DHalo"s to
differentiate them from the halos used in the Munich version of
the merger trees.
WARNING: there is rather conflicting terminology between
the two versions of the merger trees. The bound
groups of particles identified by SubFind are refered to as subhalos
in the Durham version of the merger trees described here, but are
referred to as halos in the Munich version.
Galaxies
The galaxy catalogues are stored in the DGalaxy
table. They were produced by using the GALFORM semi-analytic
code to populate the N-body halos from the Millennium simulation
with galaxies. The galaxy formation model is decsribed in detail in the
Bower et al (2006)
paper. The properties available for each galaxy include position,
velocity, stellar mass and magnitudes in various bands.
Within a single galaxy merger tree, the galaxies in the DGalaxy
table are assigned ID numbers in depth first order so that all
progenitors of a particular galaxy may be easily located. The ID
of the descendant of each galaxy is also provided.
|
2.3 : Links
| (top) (separate page) |
The following links may be useful to the user:
- Virgo project at MPA.
- Virgo UK web site.
- MPA home page.
- GAVO web site.
- GalICS project web site.
A French website offering amongst other services a similar SQL query service on a simulation result as the current webapp.
|
2.4 : References
| (top) (separate page) |
Main reference papers:
-
Millennium Simulation:
V. Springel, S. D. M. White, A. Jenkins, C. S. Frenk, N. Yoshida, L. Gao, J. Navarro, R. Thacker, D. Croton, J. Helly, J. A. Peacock, S. Cole, P. Thomas, H. Couchman, A. Evrard, J. Colberg, F. Pearce (2005)
Simulations of the formation, evolution and clustering of galaxies and quasars
Nature 435, 629
-
Millennium-II Simulation:
M. Boylan-Kolchin, V. Springel, S. D. M. White, A. Jenkins, G. Lemson (2009)
Resolving cosmic structure formation with the Millennium-II Simulation
Mon. Not. R. Astron. Soc. 398, 1150
Other references:
-
Bower, R. G., Benson, A. J., Malbon, R., Helly, J. C., Frenk, C. S.,
Baugh, C. M., Cole, S., Lacey, C. G. (2006),
Breaking the
hierarchy of galaxy formation,
Mon. Not. R. Astron. Soc., 659
-
Croton, D. J., Springel, V., White, S. D. M., De Lucia, G., Frenk,
C. S., Gao, L., Jenkins, A., Kauffmann, G., Navarro, J. F.,
Yoshida, N. (2006b),
Erratum: The many lives of active galactic
nuclei: cooling flows, black holes and the luminosities and colours of
galaxies,
Mon. Not. R. Astron. Soc., 367, 864
-
Croton, D. J., Springel, V., White, S. D. M., De Lucia, G., Frenk,
C. S., Gao, L., Jenkins, A., Kauffmann, G., Navarro, J. F.,
Yoshida, N. (2006a),
The many lives of active galactic nuclei:
cooling flows, black holes and the luminosities and colours of galaxies,
Mon. Not. R. Astron. Soc., 365, 11
-
De Lucia, G., Blaizot, J. (2007),
The hierarchical formation of the
brightest cluster galaxies,
Mon. Not. R. Astron. Soc., 375, 2
-
De Lucia, G., Springel, V., White, S. D. M., Croton, D., Kauffmann,
G. (2006),
The formation history of elliptical galaxies,
Mon. Not. R. Astron. Soc.,
366, 499
-
Springel, V. (2005),
The cosmological simulation code GADGET-2,
Mon. Not. R. Astron. Soc., 364, 1105
-
Springel, V., Frenk, C. S., White, S. D. M. (2006),
The large-scale
structure of the Universe,
Nature, 440, 1137
-
Springel, V., White, S. D. M., Tormen, G., Kauffmann, G. (2001),
Populating a cluster of galaxies - I. Results at z=0,
Mon. Not. R. Astron. Soc., 328, 726
Lists of papers using data from The Millennium Simulation and from The Millennium-II Simulation are also available.
|
3 : Databases
| (top) (separate page) |
|
The complexity of the post processing data products of cosmological simulations like the Millennium Run
lead one to consider relational database for their storage and analysis. In the following sections
we give a summary description of the concepts behind relational databases and in more detail how we
stored the Millennium data products.
|
3.1 : Relational Database Concepts
| (top) (separate page) |
|
The subject of relational databases and their query language SQL is huge and here we will only
give a very short summary. For more information see the references below.
Tables and columns
This web site gives access to multiple 'databases'. Each 'database' contains individual data sets that
somehow belong together. In a relational database, such data sets are stored in tables
(originally called "relations", hence the name).
such as the one illustrated in the following figure.
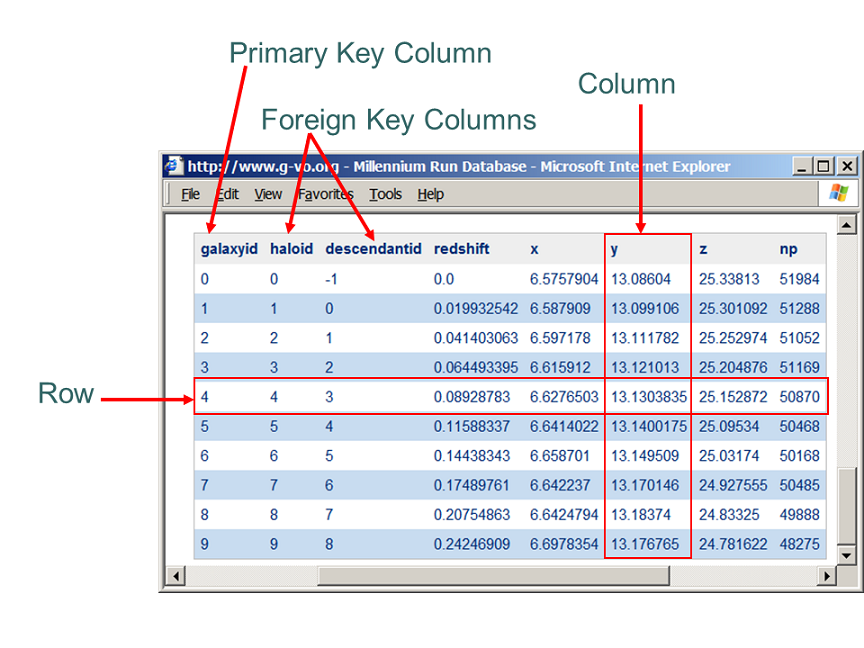
Data about individual objects/items are stored in rows in the table.
The information inside of a row is distributed over columns.
These columns are defined at the table level, i.e. all rows in a given table have the same columns,
though they need not all have values. Columns have a name and a fixed data type.
In the documentation of the tables available through the web site, we list all columns with their data type
a description and some other parameters. For an example see the description of the
DeLucia2006a table in the millimil database in the public Millennium web site
here.
The definition of a table in terms of its columns is often called the 'schema' of the table.
In the query language SQL described later one can query data from one or more tables.
To refer to a table, one must use the name of the table. However the plain name of the table only
has meaning in the context of the database that contains it.
As the web site gives access to multiple databases one must qualify the name of the table.
First one must specify the name of the database. In some cases the database is furthemore subdivided in
so called 'schemas', a kind of sub folder, that allows one to have multiple tables of the
same name in the same database. So the fully qualified name of the table is
[databasename].[schemaname].[tablename]
In most databases available through the website all tables are stored in the default schema called
'dbo'. To refer to tables stored in this schema one may leave out the schema name:
[databasename..[tablename]
For example the Millennium website gives access to a database named 'millimil' with tables such as DeLucia2006a and snapshots.
One may refer to these tables as :
millimil.dbo.DeLucia2006a
or
millimil..DeLucia2006a
and
millimil.dbo.snapshots
or
millimil..snapshots
Note that the database is case-insensitive.
Primary keys
Most tables contain one or more columns that are meant to uniquely identify rows in the table.
For each row the value(s) in the column(s) must be unique in the table. One calls this column or set of columns the
primary key of the table. In the figure the table has a single primary key column, galaxyId.
Primary keys are important for the discussion of foreign keys below.
In the design of the Millennium database we apply various special purpose algorithms for assigning
values to the different primary keys. Some should facilitate querying for tree structures, others
give information on the snapshot an object belongs to. Details about the various algorithms can be
found here.
Foreign keys
The strength of relational databases lies in the way if facilitates joining information from data sets
stored in different tables.
Often data sets in differeent tables are related to each other.
For example see the following figure that shows FOF groups, which contain (sub)halos, which contain model galaxies.
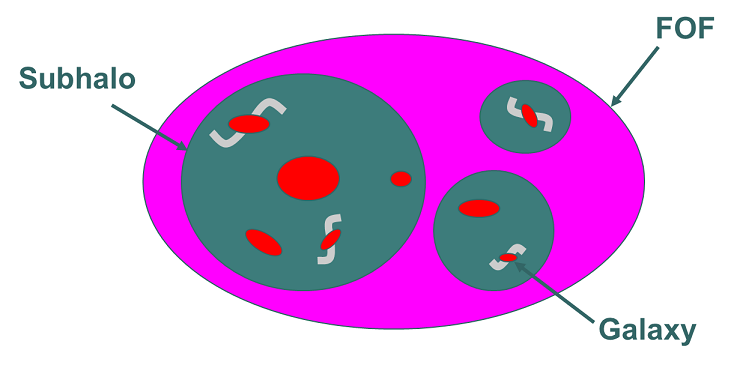
One often wishes to join information from the different datasets together.
For example one may wish to obtain information about galaxies residing in FOFGroups of a certain mass.
One could try to store all of the information in a single large table, as in the following example
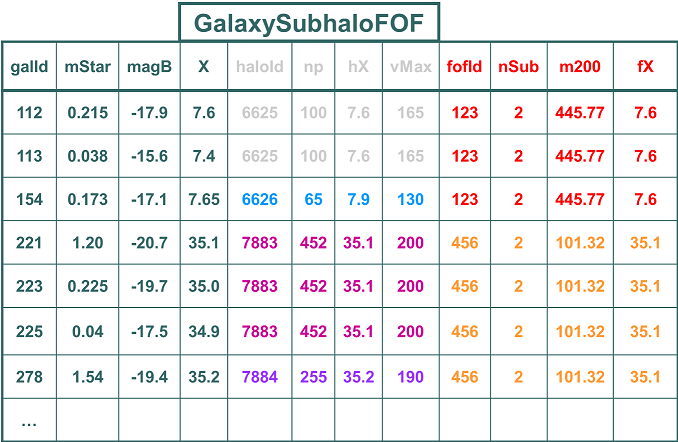
The problem with this is that there is a lot of redundancy.
As individual FOF groups can contain multiple subhalos, and individual subhalos can contain multiple galaxies,
to store all information in a single table means repeating subhalo information for all galaxies in the same subhalo,
and even worse for the FOF group information.
Instead when designing the structure of a relational database one generally aims
to "normalize" the data model. Here one stores each individual data set in its own table and
creates links between the tables representing the relationships. The following figure shows
the normalized database design for the redundant table above:
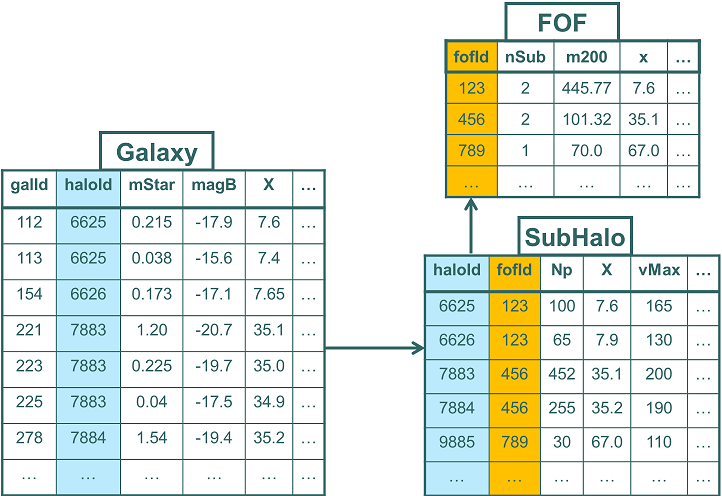
In relational databases these links are referred to as foreign keys.
They consist of one or more columns that identify an element in the target table.
That element is generally identified through its primary key.
In the example in the figure above, the Galaxy table has a column, haloId, that acts
as the foreign key to the SubHalo table. The value in this column should correspond to a value in
the SubHalo's primary key column, also called haloId. In SQL one can now join the two tables for example as follows:
select ...
from Galaxy g
join Subhalo sh
on g.haloId = sh.haloId
or in the alternative notation:
select ...
from Galaxy g
, Subhalo sh
where g.haloId = sh.haloId
References
|
3.1.1 : SQL: An Overview
| (top) (separate page) |
|
For the user, the most important feature of relational databases
is the existence of a high-level
query language called SQL (=Sequential Query Language), sometimes pronounced as "sequel".
Over time we may describe some features of this language, but as there are many excellent
texts online available we rather refer to some of these below.
Overview
an SQL query has roughly the following structure (but see
below):
SELECT [TOP ...] ...
FROM ...
WHERE ...
[GROUP BY ... ]
[ORDER BY ...]
For an exact grammar see for example the BNF of the SQL2003 standard.
That standard is in general exactly what is supported by a particular
database implementation.
In this help page we use the publicly available
Millennium database
for examples. We (try to) use upper case for the SQL keywords, though the
language is case-insensitive.
SELECT
The SELECT determines the form of the result by indicating
precisely which columns are returned, and possibly under what name.
Return all columns
SELECT *
FROM snapshots
Return the named columns
SELECT snapnum, lookbackTime
FROM snapshots
Return the named columns, but rename them
SELECT snapnum as snapshot
, redshift as z
FROM snapshots
FROM
WHERE
GROUP BY
ORDER BY
Common Table Expressions
|
3.1.2 : Performance and Indexes
| (top) (separate page) |
|
It is a goal of databases to run queries efficiently.
But to do so so work is often required, first from the database designer, sometimes also from the user
who can aim to write queries in more optimal ways.
From the designer's point of view it often is necessary to tune databases in a particular way
to assist the database engine in constructing optimal execution plans for a particular query.
The main technique here is the definition of appropriate table indexes.
We describe this very important concept in some more detail on this page.
Note that this is a field that requires quite some more
understanding of database functionality than most first time users will not possess.
Whenever you have questions about badly performing queries, please mail us
the SQL at we will try to improve it if possible.
An index can be seen as a kind of table that contains a subset of the columns of the main table,
ordered in a particular way. Each row in such an index points back to the row in the main table from which it was
extracted. If a query contains a constraint on a subset of columns that is contained in such an index,
the query engine may first find the rows obeying the constraint in the index and then retrieve the required data form
the main table. As the index is ordered one can use fast algorithms to find the requested data, often in "logarithmic time".
This is to be compared to a linear scan over a table of O(1 billion) rows, with total size ~400GB which may take minutes.
The user does not need to use the indexes explicitly in her queries.
The database "knows" of the definition of the indexes and their relation to the table and
will use this knowledge in the compilation of a user query into an execution plan.
It is however often useful to know which indexes exist on a table to write a query
in such a way that indexes can be used. In our databases a typical example is that users should
use the "snapnum" column rather
then the "redshift" column that are often both available in the tables.
Whenever we created indexes that allow more efficient querying for objects at a certain snapshot,
we used the integer snapnum column, rather than the floating-point redshift.
(See the discussion on
this page for some
more details on the relation between the snapnum and redshift columns.)
Indexes are often added to tables while it is up an running, hence a static documentation of them is soon out of date.
On the main web page though there is a button labelled "Show Indexes" that can help one find all indexes for a given table.
Clicking that button will produce the following query in the query window:
use [database-name]
select t.name as table_name
, ind.name as index_name
, col.name as column_name
, ic.index_column_id as column_rank
from sys.indexes ind
, sys.index_columns ic
, sys.columns col
, sys.tables t
where ind.object_id = ic.object_id
and ind.index_id = ic.index_id
and ind.is_primary_key = 0
and ind.is_unique = 0
and ind.is_unique_constraint = 0
and t.is_ms_shipped = 0
and ic.object_id = col.object_id
and ic.column_id = col.column_id
and ind.object_id = t.object_id
order by t.name, ind.name, ic.index_column_id
After substituting the name of a particular database for the [database-name] and clicking
"Query (browser)" button a result will appear like the following example below which shows some indexes
defined on tables in the Guo2010a database.
The table shows first the table on which an index has been defined, then the name of the index.
Then the columns in the index shown in the order in which they have been defined in the index,
sepcified by the column_rank.
This is important. The index is ordered by columns in the order of their definition.
For example the index ix_guo2010a_mr_snapnum_sampling defined on Guo2012a..MR contains columns
(snapnum, fofID, centralMvir, type, stellarmass,...) in this order, which implies that it is ordered first by snapnum, than fofID, then centralMvir and so on.
This helps when a query has a WHERE_cluase that include constraints on on snapnum and fofId.
Now a binary search (for example, DB will use more optimal algorithms) can very quickly find the range of rows
that fulfills the constraint.
But when the query only constrains stellarMass the whole index will still have to scanned before the apporpriate rows are
found. (Though note that the reduced width of the index compared will lead to some improvement compared to scanning the whole table).
It is further important to realize that when a query requests only columns that all appear in the index,
this can lead to a further performance improvement. In this case once the DB engine has found the rows obeying the constraints,
all the required data can be read off from the rows in the index itself.
I.e. it is not necessary to do a lookup in the main table itself.
This so called "bookmark lookup" (please ask Google for more details) can kill the performance improvement
the use of an index, especially if large amounts of rows obey the constraints.
For this purpose many of our indexes contain more columns than could be useful in a sorting algorithm.
For example the centralMvir in the index discussed above, being a floating point value, will
rarely have values shared by many rows. Hence its ordering will not produce intervals of constant values
that can be further ordered by subsequent values such as the stellarMass. However if one wants to obtain the stellarMass
of galaxies in a given snapshot and a given fofGroup, one needs look no further than this index.
A bookmark lookup is not required.
NB the index under discussion is itself not optimal. For it contains both fofId and snapnum.
But a fofID identifies a single friends-of-friends group which is always contained in a single snapnum.
I.e. the snapnum is actually constrained by the fofID.
Hence including the snapnum is only of interest if one has NO constraint on fofId.
| MR | ix_guo2010a_mr_snapnum_sampling | snapnum | 1 |
| MR | ix_guo2010a_mr_snapnum_sampling | fofID | 2 |
| MR | ix_guo2010a_mr_snapnum_sampling | centralMvir | 3 |
| MR | ix_guo2010a_mr_snapnum_sampling | type | 4 |
| MR | ix_guo2010a_mr_snapnum_sampling | stellarMass | 5 |
| MR | ix_guo2010a_mr_snapnum_sampling | bulgeMass | 6 |
| MR | ix_guo2010a_mr_snapnum_sampling | gDust | 7 |
| MR | ix_guo2010a_mr_snapnum_sampling | rDust | 8 |
| MR | ix_mr_descendantid | descendantId | 1 |
| MR | ix_mr_descendantid | galaxyID | 2 |
| MR | ix_mr_descendantid | lastProgenitorId | 3 |
| MR | ix_mr_descendantid | stellarMass | 4 |
| MR | ix_mr_descendantid | type | 5 |
| MR | ix_mr_descendantid | snapnum | 6 |
| MR | ix_mr_fofid_type | fofID | 1 |
| MR | ix_mr_fofid_type | type | 2 |
| MR | ix_mr_haloid_tree | haloID | 1 |
| MR | ix_mr_haloid_tree | type | 2 |
| MR | ix_mr_haloid_tree | galaxyID | 3 |
| MR | ix_mr_haloid_tree | lastProgenitorId | 4 |
|
3.1.3 : Views, functions etc
| (top) (separate page) |
Views, functions and stored procedures
To ease the writing of queries one may add a number of objects to the schema besides tables.
Views are predefined SQL statements that have been bound to the database.
They can be used in ordinary SQL statements everywhere where a table can be used.
Here the fact is used that the result of an SQL query can itself be interpreted as a table.
There are many cases where a particular pattern is used over and over in SQL queries, and
then it makes sense to isolate this pattern as a separate SQL statement and store it as a view.
Similarly it may be useful to define functions and stored procedures on the database.
These are objects that can do calculations or other actions such as updates of the
database.
They may be used in SQL queries as well, but depending on their definition
they can occur anywhere in the statement. They may also be called outside of pure
SQL statements, depending on the interface the database vendor supplies.
Depending on the database also, these may be defined in a language different from SQL,
for example C or Java.
[TBD]
|
3.1.4 : MyDB
| (top) (separate page) |
|
Here we define various concepts that are important when working with a private database
and describe various scenarios how the user might use this in the particular implementation provided by
GAVO and the Virgo consortium.
The MyDB concept
With MyDB we indicate a private database assigned to a registered user, which(s)he can
update. This in contrast to the majority of databases which are read-only.
This concept was first conceived by the SkyServer team of the SDSS collaboration.
Their implementation can be found here.
CAS-jobs is more sophisticated than the current GAVO implementation and we are working on implementing a version
of this on top of the Millennium databases as well. This will be announced on these web pages.
Context
When a user connects to the database server
a single database is selected as the default database. This database we refer to as the context.
The context database in a particular session is indicated with the word "context" appended in parens to the database
name in the left menu on the main query window.
SQL queries do not need to append the name of the context database in front of table names.
When a user has a MyDB assigned, this database will automatically be the context database.
Note that we allow a user write access to multiple database, in a sense providing multiple
MyDBs. This is so that users who wish to collaborate can do so. Only one will be the context database.
Currently it is not possible to change which database is assigned to be the context database.
select ... into ...
The main use of MyDB will be to store results of SQL queries on the server.
The following example SQL shows how this can be done.
One would like to run a a query like
select top 1000 haloid, np, x,y,z
from millimil..mpahalo
where snapnum=63
order by np desc
and store the results in a table called massiveHalos.
There are two ways to do this.
The preferred way is to first create the table. The following is an example statement that will do this.
create table massiveHalos
(
haloid bigint not null,
np integer not null,
x real not null,
y real not null,
z real not null
)
Then run the query as follows
insert into massiveHalos
select top 1000 haloid, np, x,y,z
from millimil..mpahalo
where snapnum=63
order by np desc
Succesive statements like this can be written to insert more rows in this table.
Note that one can even concatenate the two statements and submit them in one execution.
The slight disadvantage of this method is that one needs to write the create table statement.
Instead one can use a shortcut, which is to use
select top 1000 haloid, np, x,y,z
into massiveHalos
from millimil..mpahalo
where snapnum=63
order by np desc
The "into ..." will create the table automatically and fill it with the result.
This will fail if a table with that name already exists.
A disadvantage of this method fo the service is that the statement does not give any information on the result.
For the "insert into ..." statement the database returns the number of rows that was inserted. This does not happen
for the "select ... into ...". This is probably mainly bothersome for our logging of database use, but for
rthat reason we would prefere users to use the first method.
It also performs better, as there is no shared tempdb that is used for temporarily storing the result, which
will lock it for other users for the duration of the transaction.
Views
Users can decide to create database views in their MyDB. The following example illustrates a possible reason:
create view mymmhalo as
select * from millimil..mpahalo
Here a user may decide that (s)he would rather not always write the "millimil.." prefix when querying
the "mpahalo" table in the "millimil" database. Instead this view can be used in queries where otherwise
the full term would be used.
Indexes
In certain cases a user may decide to add an index to a table that was created in the MyDB.
The following is an example of a statement that would do so.
create index ix_mympahalo_haloid on mympahalo(haloId)
Deleting objects
To delete a given table from the user's MyDB use the following statement:
drop table mympahalo
pre>
Similar statements work for views and indexes:
drop view mymmhalo
and
drop index ix_mympahalo_haloid
|
3.2 : Millennium Database Design
| (top) (separate page) |
The links above lead to pages that explain the structure of the Millennium databases in some detail.
The following powerpoint contains a tutorial that was given in Leiden, Jan 19, 2007.
It contains an overview of the data structures for the databases themselves, as well as an introduction to some
of the main SQL concepts, using the Millennium databases as examples.
|
3.2.1 : Science Questions
| (top) (separate page) |
|
In analogy with the procedure followed in the design of the SDSS database (see
http://arxiv.org/abs/cs.DB/0202014 for a description)
we have asked associated theoretical astrophysicists for a set of typical questions they would want to be
able to "ask" of the system. The goal is that the design of the database and the supporting periferal
software should support the translation of these questions into SQL.
The original set of questions is the following:
- Return the galaxies residing in halos of mass between 10^13 and 10^14 solar masses.
- Return the galaxy content at z=3 of the progenitors of a halo identified at z=0
- Return all the galaxies within a sphere of radius 3Mpc around a particular halo
- Return the complete halo merger tree for a halo identified at z=0
- Find positions and velocities for all galaxies at redshift zero
with B-luminosity, colour and bulge-to-disk ratio within given
intervals.
-
Find properties of all galaxies in haloes of mass 10**14 at
redshift 1 which have had a major merger (mass-ratio < 4:1) since
redshift 1.5.
-
Find all the z=3 progenitors of z=0 red ellipticals (i.e. B-V>0.8
B/T > 0.5)
-
Find the descendents at z=1 of all LBG's (i.e. galaxies with SFR>10
Msun/yr) at z=3
-
Make a list of all haloes at z=3 which contain a galaxy of mass
>10**9 Msun which is a progenitor of BCG's in z=0 cluster of
mass >10**14.5
-
Find all z=3 galaxies which have NO z=0 descendent.
-
Return the complete galaxy merging history for a given z=0 galaxy.
-
Find all the z=2 galaxies which were within 1Mpc of a LBG
(i.e. SFR>10Msun/yr) at some previous redshift.
Some of these queries can be answered using basic SQL on a straightforward database schema.
For example, demo queries Halo 1 and Galaxy 1 below
are examples of questions for properties of galaxies or halos such as question 1 and 6.
The more tricky questions are those where the evolution/history of the galaxy or halo formation process is involved
or where spatial relations are required.
To deal with those more complex questions using not overly involved queries, whilst
maintaining acceptable response times we have made some special design choices that will be described in the following two
paragraphs.
|
3.2.2 : Data Models
| (top) (separate page) |

This page is currently under construction.
Not all links may persists.
Please re-visit this page regularly for updates in the coming weeks.
Thank you for your understanding.
The structure of the Millennium database is illustrated in the following diagram
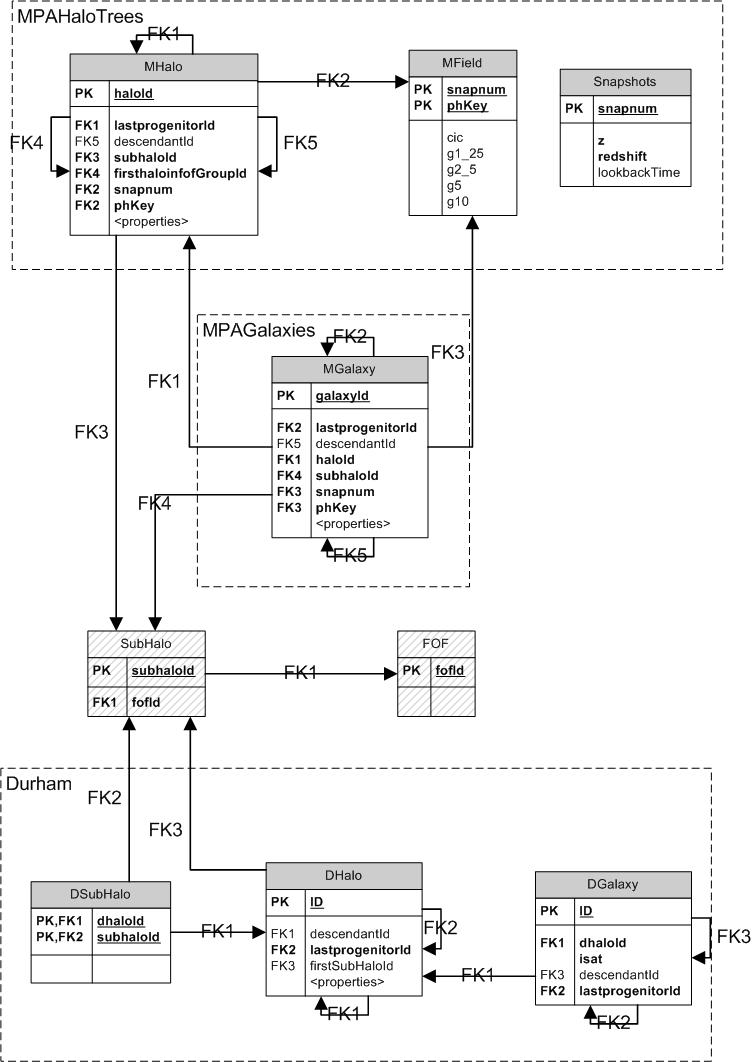
In this figure reactangles stand for tables, directed lines for foreign key relations between tables.
The names next to the foreign keys correspond to the prefix for the columns in the table from which the
foreignk key is pointing. In generel, the target of the foreign key is the primary key of the target table
(indicated by the PK prefix).
The dashed boxes around the various tables indicate which tables exist in which database.
This model has the names corresponding to the full Millennium Run. The same model is reproduced
in the milli-Millennium database, though the MPA tables there have an extra "M" in front of their name.
The tables are not complete, the full database schema can be examined from the left menu bar
in the main query page.
|
3.2.3 : Storing Merger Trees
| (top) (separate page) |
|
Many of the science questions
that were used in the design of thhe database require retrieval of merger histories for dark matter halos and/or galaxies.
A straightforward way to store a tree structure such as the merger trees here, where
each halo has at most one descendant, is to create a foreign key from each halo to
its descendant. Though this is the most explicit way to store the trees as well
as the most efficient in terms of space requirements, the problem is that one requires recursive
methods to retrieve information about a complete tree. While some database systems have explicit
support for recursive queries, for example DB2, it will still be very inefficient, when the
trees are deep, to retrieve them using such queries.
To support efficient retrieval of complete trees rooted in a halo at the final output time, one
might1 add a foreign key to each halo pointing to the final
descendant in its tree in addition to the direct descendant.
This however does not help us to retrieve trees rooted in halos at other timesteps, which is
something we also want to be able to do. And it becomes very expensive to add
foreign keys to each descendant at later times for all halos.
Instead we have implemented an alternative model which provides very quick retrieval of complete trees,
rooted in any halo, using completely standard SQL. The central idea is to store the nodes of a tree
in the order they are visited in a depth-first search, starting with the root of a tree and following the
descendant edges in opposite direction.
The nodes of the tree (halos or galaxies) get unique integer identifiers that give the rank in the
resulting sort added to the identifier of the root. This is illustrated in the following figure:
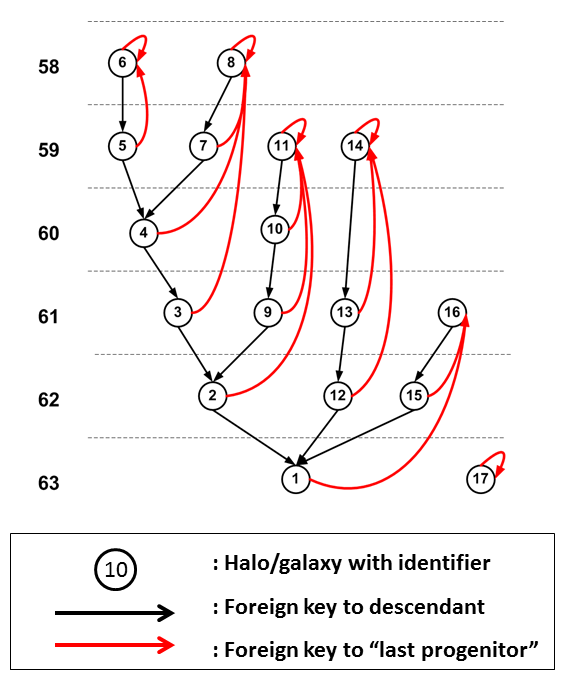
Every halo gets, in addition to the descendant foreign key, a foreign key pointing to the
"last progenitor". The last progenitor is that progenitor that comes last in the sort.
It is easy to see that this implies that the tree rooted in a certain node contains precisely those
nodes with identifier values BETWEEN (in the SQL sense) the identifier of the root and that
of the last progenitor. Query H2 on the query web page is an example of such a query:
select PROG.*
from millimil..MPAHalo PROG
, millimil..MPAHalo DES
where DES.haloId = 1
and PROG.haloId between DES.haloId and DES.lastprogenitorId
To improve the efficiency of these retrievals we define an index on the identifier and
order the table on disk acording to this index. This implies that the merger tree rooted in a
certain tree node is located on disk directly following the node itself, which ensures very
fast retrieval times, requiring only a few consecutive page reads.
Especially in the Millennium-II simulation there are merger trees that have millions of nodes.
To ask for the complete merger tree rooted in some node may therefore give very large results.
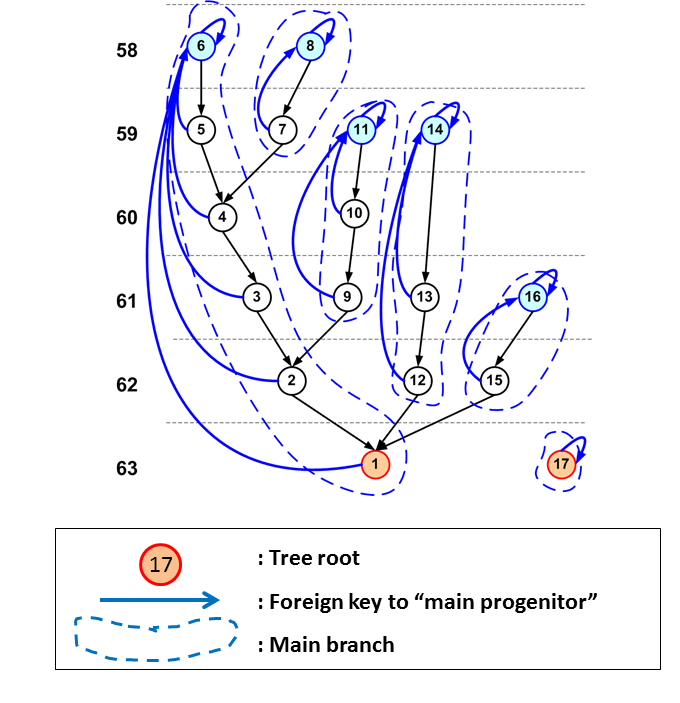
Also, one is often not interested in all progenitors, but in "THE progenitor" of a halo/galaxy at an earlier
time step. The merger trees extracted from the simulations often provide each object with one special progenitor,
referred to as the "main" or "first" progenitor. Often this is the most massive progenitor, but
sometimes the assignment is somewhat more complex2. In most merger trees
stored in these databases this most important progenitor is indicated by a column named firstProgenitorId.
When one follows the main progenitor pointers until the end, one traces the "main branch".
The halos on the main branch can be considered as "the progenitor" of a certain halo.
In the following figure main branches are outlined by the dashed lines. To find all the halos on a main branch between
a halo and the branche's leaf we give each halo a pointer to the leaf on the branch it is on, indicated by the blue arrow in the figure.
The column storing this pointer is generally called mainLeafId.
It turns out that to find all main progenitors of a given halo, one needs precisely those halos with id between
its haloId and its mainLeafId. This works because when assigning the halo identifiers using the depth
first ordering described above, we have made sure that we always first follow the pointer to the main progenitor, before
recursing to the other progenitors.
This feature is not yet implemented for the millimil merger trees.
But with a little rewriting, the following query will give us all the main progenitors of the halo with id=1,
including the halo itself:
select PROG.*
from MPAHaloTrees..MR PROG
, MPAHaloTrees..MR DES
where DES.haloId = 1
and PROG.haloId between DES.haloId and DES.mainLeafId
An interesting fact of our tree indexing schema is that one can obtain the mainLeafId for a millimil halo
using a query like the following:
select des.haloid, min(PROG.lastProgenitorId) as mainLeafId
from millimil..MPAHalo PROG
, millimil..MPAHalo DES
where DES.haloId = 1
and PROG.haloId between DES.haloId and DES.mainLeafId
group by des.haloid
We leave it as an exercise to the reader to prove this.
Some more details of merger trees can be found in this page.
1 Note that the tables in the
MPAHaloTrees database do have a pointer like this, namely the treeRootId.
2 See for example DeLucia & Blaizot (2007) for the algorithm that has decided on
the main progenitor assignment in MPA HaloTrees.
|
3.2.3.1 : More about tree structures in database
| (top) (separate page) |
|
Here we discuss some more features of the table wrt storing merger trees, in particular for halo merger trees.
A feature that may be useful deals with the status of halos as center or satellite in a FOF group.
In the abundance matching approach to predict the distribution of galaxies1, one rank orders halos in mass.
One then selects galaxies randomly from a given empirical galaxy mass function, rank orders those and assigns them
to the halo of corresponding rank. It turns out that when applying this to subhalos, the instantaneous mass of the
halos is not the optimal one to use in the ordering. This is because in the simulations generally satellite
subhalos get stripped of their mass once they enter another FOF group. It is deemed better to use the mass of the
halos just before it became a satellite, or possibly the highest massthe halo ever had.
The process is illustrated in the following figures. Red ellipses indicate FOF groups, red filled circles the central subhalos,
black open circles satellite halos. The green arrows in the first figure point from each subhalo to the last time a subhalo on the main branch
was a central subhalo. For central subhalos this obviously is a pointer to itself. In the tables this is generally stored in a column
lastCentralID. Some properties of this "last central progenitor" such as its vmax or mass are also stored.
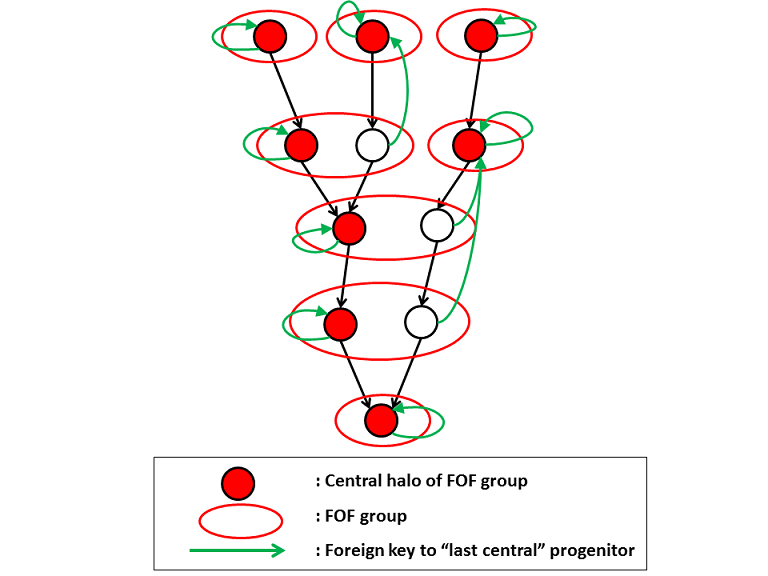
In the second picture (where the size of the circles indicates the mass of the subhalo)
the green arrow points to the most massive central progenito.
This is not necessarily the last time a halo was a central subhalo, maybe mass has been stripped in an earlier fly-by.
Also for this we have added an explicit pointer in the database, named peakMassId.
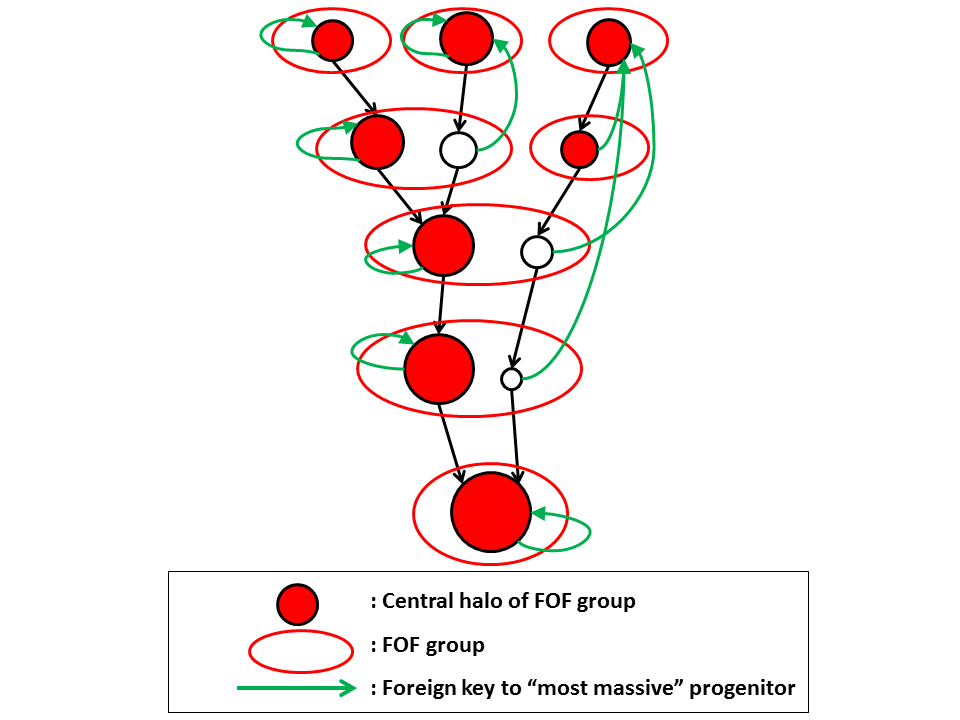
1 See for example Conroy & Wechsler (2006)
|
3.2.4 : Identifiers
| (top) (separate page) |
|
All tables have columns that contains a unique identifier for the objects stored in the table.
For example MPAHaloTrees..MHalo has a haloId column, DGalaxies..Bower2006a has a GalaxyID column and
MillenniumII..FOF a fofId. These columns are also the "primary key" of the tables, which for our database means that
the rows in the tables are sorted on this column's values.
Pointers into the table, or "foreign keys" as they are called in relational database parlance,
in general use the primary key to identify the referenced object.
Thus for example the MillenniumII..SubHalo table has a fofId column that is used to identify
the FOF group stored in the MillenniumII..FOF table that the subhalo belongs to.
For purposes of identification alone we might have used arbitrary algorithms to allocate values to these primary key
columns as long as the resulting values were unique in the table.
However we have added extra structure on most of these column that allow for certain interesting queries to be phrased
in terms of these values alone, which, combined with the ordering of the columns, often can greatly speed up their
execution. The case of the primary key columns on the tables containing merger trees has been described already
elsewhere.
Here we describe this and other algorithms together with ways to use these.
MField
MField..FOF
The value of the fofId column is derived from the snapshot index (snapnum), the index of the
file the FOF group was stored in originally (between 0 and 511), and the rank of the group in that file (starting at 0):
fofId = 1012*snapnum+108*<file-index>+<rank-in-file>
This implies that when requesting all FOF groups with a certain snapnum, say 50, one might use:
select *
from MField..FOF
where fofId between 50e12 and 51e12-1
Because the FOF table is ordered by fofId this requires a single sequential read of the table.
This will in general be much faster than the more obvious
select *
from MField..FOF
where snapnum=50
That query needs an index lookup to find the halos with the given snapnum and then a "bookmark lookup"
to get all the data from the table.
The size of the table, O(15 million) FOF groups per snapshot, means that the former query will likely time out as well though.
To work around this one may use the file-index to ask a number of smaller queries that will step through the complete snapshot in a manner
that is guaranteed not to lead to overlaps and will still be fast.
Using :FILENR and :STEP as a place-holders for literal values one can run
select *
from MField..FOF
where fofId between 50e12+:FILENR*1e8 and 50e12+(:FILENR+:STEP)*1e8-1
When writing a simple script that loops :FILENR from 0-511 in steps of a size (:STEP) that can be found with some experimentation,
this will walk through the table in an efficient manner.
MField..FOFSubHalo
The structure of the subhloId columns is equivalent to that of FOF groups and the same use can be made of these:
subhaloId = 1012*snapnum+108*<file-index>+<rank-in-file>
Note that the subhaloId column in the MillenniumII..Subhalo table has a different form as described below.
MField..MField
The density fields stored in the MField table are identified using 2 columns, snapnum and phKey.
Only the combination is unique! Consequently the combination (snapnum,phKey) on other tables
should be interpreted as a foreign key and both should be used to join these tables to the MField table.
For more information about the use of the phKey as a spatial index see here.
MPAHaloTrees..MHalo
As described here the identifiers
of merger trees are assigned using a depth-first ordering of the subhalos in a merger tree.
The full haloId column is assigned as follows:
haloId = 1012*<file-index>+106*<tree-index>+<depth-first-index>
here file-index takes again values 0-511 and tree-index is the order of the L-galaxies tree in the indicated file.
The file-index can be used when a query is supposed to scan the whole table and will therefore time out.
Similar to the case above a series of queries of the following form can easily be sent in sequence using a simple script:
select *
from MPAHalotrees..MHalo
where haloId between :FILENR*1e12 and (:FILENR+:STEP)*1e12-1
and ...
With :STEP=1 the number of rows that is scanned per query is roughly of the same size as the complete millimil..MPAHalo table.
MPAGalaxies
The galaxyId column in the three tables in this database, DeLucia2006a, DeLucia2006a_SDSS2MASS and Bertone2007a
are all assigned in the same manner as the haloId in the MPAHalotrees..MHalo table:
galaxyId = 1012*<file-index>+106*<tree-index>+<depth-first-index>
DHaloTrees..DHalo
The DHaloID column is structured exactly the same as the MPAHaloTrees..MHalo table:
DHaloID = 1012*<file-index>+106*<tree-index>+<depth-first-index>
DGalaxies..Bower2006a
The structure of the GalaxyID column is similar to, but not identical with that of the MPAGalaxies tables:
GalaxyID = 1014*lt&;file-index> + 108*<tree-index>+<depth-first-index>
The special query examples above should be updated accordingly.
MillenniumII
FOF
The fofId column is similar to the one for MField...FOF, but not identical:
fofId = 1010*snapnum+106*<file-index>+<rank-in-file>
<file-index> now takes values in 0-2047, for the rest the same "tricks" can be used as above.
SubHalo
This table has two identifying columns; subhaloFileId is based on an algorithm similar to the one for MField..FOFSubHalo, but
with adjusted values similar to MillenniumII..FOF:
subhaloFileId = 1010*snapnum+106*<file-index>+<rank-in-file>
The primary key of the SubHalo table is the subHaloId column, and this column should be used in foreign keys and in
optimised queries.
It's structure is based on the fofId of the FOF group the subahlo belongs to, and the rank of the subhalo in that group:
subhaloId = 106 * fofID + <rank in FOF group>
= 1016*snapnum+1012*<file-index>+106<fof-rank-in-file> + <rank-in-FOF-group>
The dependence on fofId means that queries to find all subhalos in a FOF group (e.g. 670020005352)can be most
efficiently written as:
select *
from MillenniumII..SubHalo
where subhaloId between 670020005352*1000000 and (670020005352+1)*1000000-1
HaloTree
Similar to the MPAHaloTrees..MHalo table, but different in details:
haloId = 1015*<file-index>+109*<tree-index>+<depth-first-index>
|
3.2.5 : Spatial Indexes
| (top) (separate page) |
|
A class of queries that are of interest and that are not trivial to treat efficiently with standard
relational database design are those that aim to find objects that are spatially
close to each other.
A typical question is:
Find all halos within a distance of :R> Mpc from a given position (:X,:Y,:Z)
(a parameter in SQL is indicated by a name prefixed with a colon),
This can be trivially translated to SQL as follows:
SELECT *
FROM MPAHaloTrees..MHalo H
WHERE SQRT((H.X-:X)*(H.X-:X)+(H.Y-:Y)*(H.Y-:Y)+(H.Z-:Z)*(H.Z-:Z)) <= :R
The problem with this query is that the database can not make use of standard techniques for performance improvement.
Such techniques generally require a representation of the data in which desired objects are closely located to each other on disk.
Disks are basically 1-dimensional structures, so an ordering in the quantity, or set of quantities, that defines the "nearness"
is generally used. See the duiscussion on indexes elsewhere in this documentation or in the literature
on relational databases.
For spatial structures in 2 dimensions or higher, there is no exact way to accomplish such an ordering.
This implies that without special treatment the database will have to scan through the whole table and evaluate the expression in the WHERE
clause. During this scan the whole table will have to be read from disk and it is this IO part of the query execution which
is really the expensive step and should if possible be minimized.
There are some techniques though that can speed up these queries. These require special data structures tht map better form 3D to
1D. We have incorporated a number of these in the Millennium database and describe these now.
Zone index
This index currently (2007-06-11) offers the best way to perform queries that have a spatial component in the Millennium database.
To show how it works we use a simpler version of the query above, that still suffers from the same problem.
SELECT *
FROM MPAHaloTrees..MHalo H
WHERE SNAPNUM = 63
AND X between 10 and 20
AND Y BETWEEN 20 AND 30
AND Z BETWEEN 220 AND 230
To each object (halo or galaxy) we associate integer valued positional coordinates, obtained from binning the simulation
box by a relatively coarse grid.
We have chosen grid cells of size about 10 h-1 Mpc, 503 cells in the Millennium, 73 in the millimil.
When the size of the grid cell is L, the index columns are defined as
ix=floor(x/L) and similar for y and z.
This implies that all objects with the same values for ix, iy and iz will be in the same cube of size L.
An index is created on these columns which now implies that queries that include these columns explicitly
can in general be executed much more quickly. The index contains the following columns in order.
snapsnum, ix,iy,iz,x,y,z,haloid/galaxyid
The following query illustrates how to write the previous query that will allow this index to be used:
SELECT *
FROM MPAHaloTrees..MHalo H
WHERE SNAPNUM = 63
AND IX = 1
AND IY = 2
AND IZ = 22
Note that if you want to get all the properties for the halos in this region, the index will allow you to find the
halo IDs quickly, but for each of these a separate lookup needs to be performed in the main table.
As these halos will be roughly randomly distributed over the main table, each lookup may require a random read.
This is a relatively slow procedure as the head of the device reading the data form disk must be placed to a new
position each time, which takes of the order of 1 milli second. Depending on the actual number of
halos found quickly in the index lookup, this socalled "bookmark lookup" may still cause the query to time out
before copletion.
In this case one may wish to break up the main query in multiple pieces based on disjunct selections
of the ix/iy/iz columns. Alternativel one may first store only the haloids in a separate table, which
will be fast as all the information is contained in the index itself and no lookup is required.
For example one may store the results in the table MYSUBVOLUME_IDS as in
SELECT *
INTO MYSUBVOLUME_IDS
FROM MPAHaloTrees..MHalo H
WHERE SNAPNUM = 63
AND IX = 1
AND IY = 2
AND IZ = 22
The full information can then be obtained by joining that table to the main table. This will again require bookmark
lookups, but the number of these can be controlled more explicitly, for example by walking through the
table in MyDB in steps of a size that will not cause the timeout.
To be able to do so it is useful to first order the table by haloid:
create clustered index ix_MYSUBVOLUME_IDS on MYSUBVOLUME_IDS(haloID)
Then one can issue the first query:
select h.*
from (
select top 50000 haloid
from MYSUBVOLUME_IDS
order by haloid ) mt
, mpahalotrees..mhalo h
where mt.haloid = h.haloid
This will produce 50000 halos. Retrieve the haloID of the last of these and issue the next query
select h.*
from (
select top 50000 haloid
from MYSUBVOLUME_IDS
where haloid > :LASTHALOID
order by haloid ) mt
, mpahalotrees..mhalo h
where mt.haloid = h.haloid
and repeat this procedure until all the halos have been retrieved.
This can easily be coded in a simple script, see the pages on
wget,
R, and
IDL.
phKey
Most objects in the Millennium databases also have another column indicating their position, phkey .
This column indicates the grid cell the object is in created by a Peano-Hilbert space filling curve.
The Peano-Hilbert curve in particular has the nice property
that points that are nearby on the curve are also nearby in space. For other such curves this is not always true, but often,
An column containing the (discrete) distance along such a curve can therefore provide a reasonable mapping from 1D-<3D,
and when indexed, can be used to implement spatial searches efficiently.
The code for this is too complex to use directly in T-SQL and the functions must be implemented in a more general
programming language. We have created such a library in C# and embedded this in our SQLServer database.
Here we describe how to use the functions and other components of this library in your SQL queries.
For this purpose the simulation volume of the Millennium run has been subdivided in 2563
grid cells and to each cell a value has been assigned corresponding to the step number along such a
curve.
References
For an interesting general discussion of this problem and various approaches solutions see
the PhD
thesis by Volker Markl and references therein.
A very general and comprehensive reference to spatial indexes is the following book.
Hana Samet, 2006, Foundations of Multidimentsional and Metric Data Structures
Morgan Kaufman, ISBN 13:978-0-12-369446-1
|
3.2.6 : Random Sampling
| (top) (separate page) |
|
For many science questions it is strictly speaking not necessary to use the
full Millennium database. And for performance reasons it would often be
preferrable to use a smaller dataset that is in some way a good representation
of the complete set.
The milli-Millennium could be used for these purposes, however the problem with it is
that it misses the long wavelength modes of the initial perturbation field and does therefore
not correspond to a random volume of the same size from the full Millennium.
It's use is mainly in the opportunity it offers to test SQL queries that will work on the
full Millennium database, while giving much faster return times.
To offer an easy option of drawing proper random samples from the Millennium run we have added
a column to some of the datasets which contains an integer random number generated using the
java.lang.Math.random() function. For the Millennium datasets the number ranges between 0 and 1000000,
for the milli-Millennium data between 0 and 1000.
For example, to choose a roughly "1 in 1000" sample of all galaxies at the final snaphot one
may choose to have all galaxies with this random number in the interval [0,1000].
Note that this does not directly offer the an option to have a random sample of a prescribed size,
but as the example below shows it will be not hard to do so either.
Currently (2006-08-01) this column is only added to MPAGalaxies..MGalaxy and millimil..MMGalaxy.
The following queries show how one might use this feature.
The first takes a random sample that returns roughly 1% of all the galaxies from the MPA
Millennium galaxy catalogue at the final snapshot. This should roughly produce 200000 galaxies:
select *
from mpagalaxies..mgalaxy
where snapnum=63
and random between 0 and 10000
By choosing different intervals of the same size different smaples will be chosen.
The following query picks a random sample of exactly 1000 entries:
select top 1000 *
from mpagalaxies..mgalaxy
where snapnum=63
and random between 0 and 100
The selection on random would produce about 2000 galaxies, the top 1000
takes only the first 1000 of these.
This function will be most useful in combination with a
select ... into ... in a MyDB.
|
3.3 : Millennium Databases
| (top) (separate page) |
|
The links above lead to pages giving more details about the databases that have been made available
top the public through this web site.
|
3.3.1 : millimil
| (top) (separate page) |
|
This database is a small version of the full Millennium run results.
It contains versions of all the tables also found in the main database, both the MPA and the Durham results.
|
3.3.1.1 : Snapshots
| (top) (separate page) |
|
This table stores some housekeeping information of the milli-Millennium simulation. In particular, it links
redshifts and lookback times to the integer index of the snapshot. Almost all other tables in the millimil
database have a snapnum column that corresponds to the one in this table.
| column | type | UCD | unit | description |
| snapnum | integer | | | The order of the snapshot, from 0 to 63 (z=0) |
| z | double | | | The redshift in full precision |
| redshift | real | | | The redshift rounded to two decimal places. |
| lookBackTime | float | | 109 years | The lookback time corresponding to the snapshot |
|
3.3.1.2 : MMField
| (top) (separate page) |
|
This table stored the dark matter density field put on a 323 density grid.
It stores both simple count in cells and also the values of the density field smoothed with
a Gaussian kernel of various sizes.
| column | type | UCD | unit | description |
|---|
| snapnum |
int |
time |
|
The snapshot number for this densityfield.
This column corresponds to the snapnum column in
the Snapshots table in this database.
|
| phkey |
int |
|
|
The Peano-Hilbert key for this grid cell.
|
| cic |
float |
phys.density |
|
The counts-in-cell density in the grid cell, normalized by mean density.
I.e. cic*19683000/323 gives the number of particles in each cell.
|
| g1_25 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 1.25 Mpc/h, normalized by mean density.
|
| g2_5 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 2.5 Mpc/h, normalized by mean density.
|
| g5 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 5 Mpc/h, normalized by mean density.
|
| g10 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 10 Mpc/h, normalized by mean density.
|
|
3.3.1.3 : FOF
| (top) (separate page) |
|
The table stores all the friend-of-friends (FOF) groups extracted from the raw output from the milli-Millennium
simulation. These FOF groups form the basis that the SUBFIND algorithm uses to detect the subhalos.
| column | type | UCD | unit | description |
|---|
| fofId |
long |
meta.id;meta.main |
|
The id of this FOF group, unique within the full simulation.
|
| snapNum |
int |
time |
|
The snapshot number where this FOF group was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this halo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this FOF group.
|
| numSubGroups |
int |
meta.number |
|
The number of sub halos found in this FOF group with the SUBFIND algorithm.
These subhalos are stord in the FofSubHalo table in this same database.
|
| firstSubHaloId |
long |
|
meta.id.assoc |
The identifier of the most massive subhalo in this FOF group.
NB This is not equivalent to the fofID in millimil..DeLucia2006a or the firstHaloInFOFGroupId in millimil..MPAHalo! |
| m_Mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the mean density of the simulation.
|
| r_mean200 |
float |
phys.mass |
Mpc/h |
The (comoving) radius within which the FOF group has an overdensity 200 times the mean density of the simulation.
|
| m_Crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the critical density of the simulation.
|
| r_crit200 |
float |
phys.mass |
Mpc/h |
The (comoving) radius within which the FOF group has an overdensity 200 times the critical density of the simulation.
|
| m_tophat200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity corresponding to the value at virialisation in the top-hat collapse model for this cosmology.
|
| r_tophat200 |
float |
phys.mass |
Mpc/h |
The (comoving) radius within which the FOF group has an overdensity corresponding to the value at virialisation in the top-hat collapse model for this cosmology.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the position in comoving coordinates.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this FOF group.
See the text on spatial indexes.
|
| zIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 7 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 7 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 7 bins
See the text on spatial indexes.
|
| random |
integer |
|
|
Random number between 0 and 1000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.1.4 : FofSubHalo
| (top) (separate page) |
|
The table stores all the subhalos identified with the SUBFIND algorithm in the friends-of-friends groups
that are stored in the FOF table in this same database.
| column | type | UCD | unit | description |
|---|
| fofId |
long |
meta.id.assoc |
|
The id of the parent FOF group in which this subhalo is embedded.
|
| subhaloId |
long |
meta.id;meta.main |
|
The identifier of this subhalo, unique within the full simulation.
|
| snapNum |
int |
time |
|
The snapshot number where this halo was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField. |
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
|
3.3.1.5 : MPAHalo
| (top) (separate page) |
|
The table stores all the halos from the milli-Millennium simulation in a representation that allows efficient
querying for merger histories. For description how these merger trees were constructed see
Springel2005a
and DeLucia2006b.
| column | type | UCD | unit | description |
|---|
| haloID |
long |
meta.id;meta.main |
|
The id of this halo, unique within the full simulation.
|
| subHaloID |
long |
meta.id; |
|
The id of the sub-halo corresponding to this halo.
|
| lastProgenitorId |
long |
meta.id.assoc |
|
Indicator of the last progenitor in the halo merger tree rooted in this halo.
All halos with id between haloId and lastProgenitorId form the merger tree rooted in this halo.
Foreign key to MMHalo.haloId.
|
| treeId |
long |
meta.id.parent |
|
The unique id of the galaxy formation "tree" to which this halo belongs.
|
| snapNum |
int |
time |
|
The snapshot number where this halo was identified.
This column corresponds to the snapnum column in
the Snapshots table in this database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this halo belongs.
|
| firstProgenitorId |
long |
meta.id.assoc |
|
The id of the main progenitor of this halo.
Strictly, haloId+1 iff lastProgenitorId > haloId, else -1.
|
| nextProgenitorId |
long |
meta.id.assoc |
|
The ID of the "next progenitor" in a linked list representation of the halo merger trees.
|
| descendantId |
long |
meta.id.assoc |
|
The haloId of the descendant f this halo in the merger tree. -1 if there is no descendant.
|
| firstHaloInFOFgroupId |
long |
meta.id.assoc |
|
Id of the halo at the center of the friend-of-friends group to which this halo belongs.
|
| nextHaloInFOFgroupId |
long |
meta.id.assoc |
|
Id of the "next halo" in the linked list representation of the friend-of-friends grouping.
|
| np |
int |
meta.number |
|
Number of simulation particles in this halo.
|
| m_Mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the halo has an overdensity 200 times the mean density of the simulation.
NB this value is only defined for halos with haloId=firstHaloInFOFgroupId. |
| m_Crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the halo has an overdensity 200 times the critical density of the simulation.
NB this value is only defined for halos with haloId=firstHaloInFOFgroupId. |
| m_TopHat |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the halo has an overdensity corresponding to the value at virialisation in the top-hat
collapse model for this cosmology.
NB this value is only defined for halos with haloId=firstHaloInFOFgroupId. |
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this halo.
See the text on spatial indexes.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the position in comoving coordinates.
|
| zIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 7 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 7 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 7 bins
See the text on spatial indexes.
|
| velX |
float |
phys.veloc |
km/sec |
The X-component of the peculiar velocity.
|
| velY |
float |
phys.veloc |
km/sec |
The Y-component of the peculiar velocity.
|
| velZ |
float |
phys.veloc |
km/sec |
The Z-component of the peculiar velocity.
|
| velDisp |
float |
phys.veloc.dispersion |
km/sec |
he velocity dispersion of the halo.
|
| vMax |
float |
phys.veloc.rotat |
km/sec |
Maximum rotational velocity, calculates as the maximum of the expression sqrt(G M(r)/r) where r runs of the particles in the halo.
|
| spinX |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The X-component of the spin of the halo.
|
| spinY |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Y-component of the spin of the halo.
|
| spinZ |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Z-component of the spin of the halo.
|
| mostBoundID |
long |
meta.id.assoc |
|
The id of the most bound particle of this halo.
|
| fileNr |
int |
meta.file;meta.id |
|
Original file number in which the subhalo was defined.
|
| subhaloIndex |
int |
meta.id.assoc |
|
Index of this subhalo in the file identified by fileNr.
|
| halfmassRadius |
float |
phys.size.radius |
Mpc/h |
Radius containing half of the mass of the halo.
|
| random |
integer |
|
|
Random number between 0 and 1000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.1.6 : DeLucia2006a
| (top) (separate page) |
|
This table contains the result of an L-Galaxies run on the milli-Millennium merger trees with the same
parameters as used in the full Millennium run described in
De Lucia and Blaizot 2006.
Note that galaxies without stars have been assigned the value 99 for all their magnitudes.
| column | type | UCD | unit | description |
|---|
| galaxyID |
long |
meta.id;meta.main |
|
ID of galaxy, unique within simulation and SAM run. |
| lastProgenitorId |
long |
meta.id.assoc |
|
All galaxies with id between this galaxyId and this lastProgenitorId together are the merger tree rooted in this galaxy.
|
| descendantId |
long |
meta.id.assoc |
|
Pointer to the descendant of this galaxy in its merger tree; -1 if there is no descendant
|
| haloID |
long |
meta.id.parent |
|
Unique ID of MPA halo containing this galaxy
|
| subHaloID |
long |
meta.id; |
|
The ID of the sub-halo this galaxy resides in. Identical to the subhaloId of the halo identified by the haloId. |
| fofID |
long |
meta.id; |
|
The id of the sub-halo at the center of the friends-of-friends (FOF) this galaxy resides in.
NB This is not equivalent to the firstSubhaloID column in the FOF table! |
| treeId |
long |
meta.id.parent |
|
unique id of galaxy formation tree containing this galaxy
|
| firstProgenitorId |
long |
meta.id.assoc |
|
Main progenitor of this galaxy. Also the first progenitor in a linked list representation of the merger tree. |
| nextProgenitorId |
long |
meta.id.assoc |
|
Next progenitor of this galaxy in linked list representation of merger tree
|
| type |
int |
src.class |
|
0,1 or 2 indicating whether this galaxy is a central galaxy of its FOF group, central galaxy of a subhalo, or a satellite galaxy. |
| snapnum |
int |
time |
|
The snapshot number where this galaxy was identified.
This column corresponds to the snapnum column in
the Snapshots table in this database.
|
| redshift |
float |
time |
|
redshift of the snapshot where this galaxy resides
|
| centralMvir |
float |
phys.veloc.dispersion |
1010/h Msun |
virial mass of background (FOF) halo containing this galaxy
|
| phkey |
int |
|
|
Peano-Hilbert key, (bits=5), for position in 62.5/h Mpc box
See the text on spatial indexes.
|
| x |
float |
pos.cartesian.x |
1/h Mpc |
The X-coordinate of the position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
1/h) Mpc |
The Y-coordinate of the position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
1/h Mpc |
The Z-coordinate of the position in comoving coordinates.
|
| zIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this galaxy's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 7 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 7 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 7 bins
See the text on spatial indexes.
|
| velX |
float |
phys.veloc |
km/s |
The X-component of the physical peculiar velocity of the galaxy. |
| velY |
float |
phys.veloc |
km/s |
The Y-component of the physical peculiar velocity of the galaxy. |
| velZ |
float |
phys.veloc |
km/s |
The Z-component of the physical peculiar velocity of the galaxy. |
| np |
int |
meta.number |
|
Number of particles in halo the galaxy belongs to.
|
| mvir |
float |
phys.mass |
1010/h Msun |
Virial mass of the subhalo the galaxy is/was the center of.
|
| rvir |
float |
phys.size.radius |
Mpc/h |
Virial radius of the subhalo the galaxy is/was the center of.
|
| vvir |
float |
phys.veloc |
km/s |
Virial velocity of the subhalo the galaxy is/was the center of.
|
| vmax |
float |
phys.veloc.rotat |
km/s |
Maximum rotational velocity of the subhalo of which this galaxy is the center, or the last value for satellite galaxies.
|
| coldGas |
float |
phys.mass |
1010/h Msun |
Mass in cold gas.
|
| stellarMass |
float |
phys.mass |
1010/h Msun |
Mass in stars.
|
| bulgeMass |
float |
phys.mass |
1010/h Msun |
Mass of bulge.
|
| hotGas |
float |
phys.mass |
1010/h Msun |
Mass in hot gas component of this galaxy's subhalo. TBD on type 2 galaxies.
|
| ejectedMass |
float |
phys.mass |
1010/h Msun/h |
The ejected mass component (see de Lucia et al., 2004, MNRAS, Volume 349, 1101-1116).
|
| blackHoleMass |
float |
phys.mass |
1010/h Msun |
Mass of central black hole
|
| metalsColdGas |
float |
phys.mass |
1010/h Msun |
Mass in metals in cold gas.
|
| metalsStellarMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in stars.
|
| metalsBulgeMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in bulge.
|
| metalsHotGas |
float |
phys.mass |
1010/h Msun |
ratio of mass in metals.
|
| metalsEjectedMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in ejected gas.
|
| sfr |
float |
phys.SFR |
Msun/yr |
Star formation rate
|
| sfrBulge |
float |
phys.SFR |
Msun/yr |
Star formation rate in the bulge.
|
| xrayLum |
float |
em.X-Ray |
TBD |
X-Ray luminosity
|
| diskRadius |
float |
phys.size.radius |
Mpc/h |
Disk radius, derived form halo radius ala
Mo, Mao and White (1997) |
| coolingRadius |
float |
phys.size.radius |
Mpc/h |
The radius within which the cooling time scale is shorter than the dynamical timescale
|
| mag_b |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega) of galaxy.
|
| mag_v |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega) of galaxy
|
| mag_r |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega) of galaxy.
|
| mag_i |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega) of galaxy.
|
| mag_k |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega) of galaxy.
|
| mag_bBulge |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega) of bulge
|
| mag_vBulge |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega) of bulge
|
| mag_rBulge |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega) of bulge
|
| mag_iBulge |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega) of bulge
|
| mag_kBulge |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega) of bulge
|
| mag_bDust |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega), dust extinction included
|
| mag_vDust |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega), dust extinction included
|
| mag_rDust |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega), dust extinction included
|
| mag_iDust |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega), dust extinction included
|
| mag_kDust |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega), dust extinction included
|
| massWeightedAge |
float |
|
109 yr |
The age of this galaxy, weighted by mass of their components. |
| random |
integer |
|
|
Random number between 0 and 1000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.1.7 : DeLucia2006a_SDSS2MASS
| (top) (separate page) |
|
This table contains SDSS and 2MASS observer frame magnitudes for the galaxy catalogue in
the DeLucia2006a table in this same database.
| column | type | UCD | unit | description |
|---|
| galaxyID |
long |
meta.id;meta.main |
|
ID of galaxy, unique within simulation and SAM run. This ID is the same as that in the DeLucia2006a table. |
| snapnum |
int |
time |
|
The snapshot number where this galaxy was identified.
This column corresponds to the snapnum column in
the Snapshots table in this database.
|
| u_sdss |
float |
|
|
Absolute observer frame SDSS u magnitude (AB), dust extinction included
|
| g_sdss |
float |
|
|
Absolute observer frame SDSS g magnitude (AB), dust extinction included
|
| r_sdss |
float |
|
|
Absolute observer frame SDSS r magnitude (AB), dust extinction included
|
| i_sdss |
float |
|
|
Absolute observer frame SDSS i magnitude (AB), dust extinction included
|
| z_sdss |
float |
|
|
Absolute observer frame SDSS z magnitude (AB), dust extinction included
|
| J_2mass |
float |
|
|
Absolute observer frame 2MASS J magnitude (AB), dust extinction included
|
| H_2mass |
float |
|
|
Absolute observer frame 2MASS H magnitude (AB), dust extinction included
|
| K_2mass |
float |
|
|
Absolute observer frame 2MASS K magnitude (AB), dust extinction included
|
|
3.3.1.8 : DHalo
| (top) (separate page) |
|
This table contains the catalogue of halos used to construct the
merger trees used in the Bower et al (2006) galaxy formation
model. Each DHalo is a collection of SubFind subhalos grouped together to
make a halo. Note that the objects referred to as subhalos here
(SubFind groups) are equivalent to the objects listed in the MHalo table.
| column | type | UCD | unit | description |
|---|
| ID |
long |
meta.id;meta.main |
|
The ID of this DHalo, unique within the full simulation.
|
| descendantId |
long |
meta.id.assoc |
|
The ID of the descendant of this DHalo in the merger tree.
|
| LastProgenitorId |
long |
meta.id.assoc |
|
Indicator of the last progenitor in the DHalo merger tree
rooted in this DHalo.
All DHalos with id between ID
and LastProgenitorId form the merger tree rooted in this
DHalo. |
| TreeId |
long |
meta.id.parent |
|
The unique id of the DHalo merger tree to which this DHalo belongs.
|
| FirstSubhaloID |
long |
meta.id.assoc |
|
The unique id of the most massive subhalo in this DHalo
|
| np |
int |
meta.number |
|
Number of simulation particles in this DHalo. This is
equal to the total number of particles in the constituent
subhalos of the DHalo.
|
| NSubhalos |
int |
meta.number |
|
Number of subhalos in this DHalo.
|
| SnapNum |
int |
time |
|
The snapshot number where this DHalo was identified.
|
| Redshift |
float |
time |
|
The redshift of the snapshot to which this DHalo belongs.
|
|
3.3.1.9 : DSubHalo
| (top) (separate page) |
|
The DSubhalo table specifies the parent DHalo for each
subhalo. It may be used to determine which subhalos belong to
each DHalo. The subhaloID column corresponds to the subHaloID
column in the MPAHalo and the FOFSubhhalo tables in the millimil database, so additional information
about a subhalo may be obtained by joining to these tables.
| column | type | UCD | unit | description |
|---|
| DHaloID |
long |
meta.id |
|
The ID of the DHalo to which this subhalo belongs
|
| SubhaloID |
long |
meta.id |
|
The unique ID of a subhalo.
|
|
3.3.1.10 : Bower2006a
| (top) (separate page) |
|
This table contains the semi-analytic galaxy catalogues of Bower
et al (2006). All magnitudes include dust extinction and assume
that H0 = 100km/sec/Mpc.
| column | type | UCD | unit | description |
|---|
| GalaxyID |
long |
meta.id;meta.main |
|
Id of galaxy, unique within simulation and semi-analytic run |
| DescendantId |
long |
meta.id.assoc |
|
pointer to the descendant of this galaxy in the merger tree
|
| LastProgenitorId |
long |
meta.id.assoc |
|
All galaxies with IDs between the ID of this galaxy and LastProgenitorId are the merger tree rooted at this galaxy.
|
| Redshift |
float |
time |
|
redshift of the snapshot where this galaxy resides
|
| SnapNum |
int |
time |
|
The snapshot number where this galaxy exists.
|
| FirstProgenitorID |
long |
meta.id.assoc |
|
The ID of the most massive progenitor of the galaxy
|
| EndMainBranchID |
long |
meta.id.assoc |
|
The ID of the galaxy at the end of the main progenitor branch of this galaxy.
|
| phKey |
integer |
|
|
Peano-Hilbert key, (bits=5), for position in 62.5/h Mpc
box. See the text on spatial indexes.
|
| zIndex |
integer |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this galaxy's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 6 bins. See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.y |
|
Zone index along y-direction, based on 6 bins. See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.y |
|
Zone index along z-direction, based on 6 bins. See the text on spatial indexes.
|
| random |
float |
|
|
A random number between 0 and 1000000. See the section on
random sampling.
|
| mag_U |
float |
em.opt.U |
|
Absolute rest frame U band magnitude (Vega) of galaxy.
|
| mag_B |
float |
em.opt.B |
|
Absolute rest frame B band magnitude (Vega) of galaxy.
|
| mag_V |
float |
em.opt.V |
|
Absolute rest frame V band magnitude (Vega) of galaxy.
|
| mag_R |
float |
em.opt.R |
|
Absolute rest frame R band magnitude (Vega) of galaxy.
|
| mag_I |
float |
em.opt.I |
|
Absolute rest frame I band magnitude (Vega) of galaxy.
|
| mag_J |
float |
em.opt.J |
|
Absolute rest frame J band magnitude (Vega) of galaxy.
|
| mag_K |
float |
em.opt.K |
|
Absolute rest frame K band magnitude (Vega) of galaxy.
|
| mag_H |
float |
em.opt.H |
|
Absolute rest frame H band magnitude (Vega) of galaxy.
|
| mag_U_Obs |
float |
em.opt.U |
|
Absolute observer frame U band magnitude (Vega) of galaxy.
|
| mag_B_Obs |
float |
em.opt.B |
|
Absolute observer frame B band magnitude (Vega) of galaxy.
|
| mag_V_Obs |
float |
em.opt.V |
|
Absolute observer frame V band magnitude (Vega) of galaxy.
|
| mag_R_Obs |
float |
em.opt.R |
|
Absolute observer frame R band magnitude (Vega) of galaxy.
|
| mag_I_Obs |
float |
em.opt.I |
|
Absolute observer frame I band magnitude (Vega) of galaxy.
|
| mag_J_Obs |
float |
em.opt.J |
|
Absolute observer frame J band magnitude (Vega) of galaxy.
|
| mag_K_Obs |
float |
em.opt.K |
|
Absolute observer frame K band magnitude (Vega) of galaxy.
|
| mag_H_Obs |
float |
em.opt.H |
|
Absolute observer frame H band magnitude (Vega) of galaxy.
|
| mag_UBulge |
float |
em.opt.U |
|
Absolute rest frame U band magnitude (Vega) of galactic bulge.
|
| mag_BBulge |
float |
em.opt.B |
|
Absolute rest frame B band magnitude (Vega) of galactic bulge.
|
| mag_VBulge |
float |
em.opt.V |
|
Absolute rest frame V band magnitude (Vega) of galactic bulge.
|
| mag_RBulge |
float |
em.opt.R |
|
Absolute rest frame R band magnitude (Vega) of galactic bulge.
|
| mag_IBulge |
float |
em.opt.I |
|
Absolute rest frame I band magnitude (Vega) of galactic bulge.
|
| mag_JBulge |
float |
em.opt.J |
|
Absolute rest frame J band magnitude (Vega) of galactic bulge.
|
| mag_KBulge |
float |
em.opt.K |
|
Absolute rest frame K band magnitude (Vega) of galactic bulge.
|
| mag_HBulge |
float |
em.opt.H |
|
Absolute rest frame H band magnitude (Vega) of galactic bulge.
|
| mag_UBulge_Obs |
float |
em.opt.U |
|
Absolute observer frame U band magnitude (Vega) of galactic bulge.
|
| mag_BBulge_Obs |
float |
em.opt.B |
|
Absolute observer frame B band magnitude (Vega) of galactic bulge.
|
| mag_VBulge_Obs |
float |
em.opt.V |
|
Absolute observer frame V band magnitude (Vega) of galactic bulge.
|
| mag_RBulge_Obs |
float |
em.opt.R |
|
Absolute observer frame R band magnitude (Vega) of galactic bulge.
|
| mag_IBulge_Obs |
float |
em.opt.I |
|
Absolute observer frame I band magnitude (Vega) of galactic bulge.
|
| mag_JBulge_Obs |
float |
em.opt.J |
|
Absolute observer frame J band magnitude (Vega) of galactic bulge.
|
| mag_KBulge_Obs |
float |
em.opt.K |
|
Absolute observer frame K band magnitude (Vega) of galactic bulge.
|
| mag_HBulge_Obs |
float |
em.opt.H |
|
Absolute observer frame H band magnitude (Vega) of galactic bulge.
|
| u_SDSS |
float |
em.opt.u |
|
Absolute rest frame SDSS u band magnitude (Vega) of the galaxy.
|
| g_SDSS |
float |
em.opt.g |
|
Absolute rest frame SDSS g band magnitude (Vega) of the galaxy.
|
| r_SDSS |
float |
em.opt.r |
|
Absolute rest frame SDSS r band magnitude (Vega) of the galaxy.
|
| i_SDSS |
float |
em.opt.i |
|
Absolute rest frame SDSS i band magnitude (Vega) of the galaxy.
|
| z_SDSS |
float |
em.opt.z |
|
Absolute rest frame SDSS z band magnitude (Vega) of the galaxy.
|
| u_SDSS_Obs |
float |
em.opt.u |
|
Absolute observer frame SDSS u band magnitude (Vega) of the galaxy.
|
| g_SDSS_Obs |
float |
em.opt.g |
|
Absolute observer frame SDSS g band magnitude (Vega) of the galaxy.
|
| r_SDSS_Obs |
float |
em.opt.r |
|
Absolute observer frame SDSS r band magnitude (Vega) of the galaxy.
|
| i_SDSS_Obs |
float |
em.opt.i |
|
Absolute observer frame SDSS i band magnitude (Vega) of the galaxy.
|
| z_SDSS_Obs |
float |
em.opt.z |
|
Absolute observer frame SDSS z band magnitude (Vega) of the galaxy.
|
| u_SDSSBulge |
float |
em.opt.u |
|
Absolute rest frame SDSS u band magnitude (Vega) of the galactic bulge.
|
| g_SDSSBulge |
float |
em.opt.g |
|
Absolute rest frame SDSS g band magnitude (Vega) of the galactic bulge.
|
| r_SDSSBulge |
float |
em.opt.r |
|
Absolute rest frame SDSS r band magnitude (Vega) of the galactic bulge.
|
| i_SDSSBulge |
float |
em.opt.i |
|
Absolute rest frame SDSS i band magnitude (Vega) of the galactic bulge.
|
| z_SDSSBulge |
float |
em.opt.z |
|
Absolute rest frame SDSS z band magnitude (Vega) of the galactic bulge.
|
| u_SDSSBulge_Obs |
float |
em.opt.u |
|
Absolute observer frame SDSS u band magnitude (Vega) of the galactic bulge.
|
| g_SDSSBulge_Obs |
float |
em.opt.g |
|
Absolute observer frame SDSS g band magnitude (Vega) of the galactic bulge.
|
| r_SDSSBulge_Obs |
float |
em.opt.r |
|
Absolute observer frame SDSS r band magnitude (Vega) of the galactic bulge.
|
| i_SDSSBulge_Obs |
float |
em.opt.i |
|
Absolute observer frame SDSS i band magnitude (Vega) of the galactic bulge.
|
| z_SDSSBulge_Obs |
float |
em.opt.z |
|
Absolute observer frame SDSS z band magnitude (Vega) of the galactic bulge.
|
| L_Halpha |
float |
|
10^40 h^-2 erg/s |
Total luminosity in the Halpha emission line
|
| LBulge_Halpha |
float |
|
10^40 h^-2 erg/s |
Bulge luminosity in the Halpha emission line
|
| L_OII3727 |
float |
|
10^40 h^-2 erg/s |
Total luminosity in the OII3727 emission line
|
| LBulge_OII3727 |
float |
|
10^40 h^-2 erg/s |
Bulge luminosity in the OII3727 emission line
|
| L_Hbeta |
float |
|
10^40 h^-2 erg/s |
Total luminosity in the Hbeta emission line
|
| LBulge_Hbeta |
float |
|
10^40 h^-2 erg/s |
Bulge luminosity in the Hbeta emission line
|
| rDisk |
float |
phys.size.radius |
1/h Mpc |
Half mass radius of the disk
|
| rBulge |
float |
phys.size.radius |
1/h Mpc |
Half mass radius of the bulge
|
| vDisk |
float |
phys.veloc |
km/s |
Circular velocity of the disk at the half mass radius
|
| vBulge |
float |
phys.veloc |
km/s |
Circular velocity of the bulge at the half mass radius
|
| x |
float |
pos.cartesian.x |
1/h Mpc |
x-component position
|
| y |
float |
pos.cartesian.y |
1/h Mpc |
y-component position
|
| z |
float |
pos.cartesian.z |
1/h Mpc |
z-component position
|
| velx |
float |
phys.veloc |
km/s |
x-component of peculiar velocity
|
| vely |
float |
phys.veloc |
km/s |
y-component of peculiar velocity
|
| velz |
float |
phys.veloc |
km/s |
z-component of peculiar velocity
|
| StellarMass |
float |
phys.mass |
1/h Msun |
The total stellar mass of the galaxy |
| bulgeMass |
float |
phys.mass |
1/h Msun |
The total stellar mass of the galactic bulge |
| coldGas |
float |
phys.mass |
1/h Msun |
mass of cold gas in this galaxy |
| blackHoleMass |
float |
phys.mass |
1/h Msun |
mass of the central black hole in this galaxy |
| ageVdisk |
float |
|
Gyr |
V band luminosity weighted age of the disk |
| ageVbulge |
float |
|
Gyr |
V band luminosity weighted age of the bulge |
| ageV |
float |
|
Gyr |
V band luminosity weighted age of the galaxy |
| metVdisk |
float |
|
Dimensionless mass fraction |
V band luminosity weighted metallicity of the disk |
| metVbulge |
float |
|
Dimensionless mass fraction |
V band luminosity weighted metallicity of the bulge |
| metV |
float |
|
Dimensionless mass fraction |
V band luminosity weighted metallicity of the galaxy |
| mhalo |
float |
phys.mass |
1/h Msun |
mass of the host halo of this galaxy |
| type |
int |
src.class |
|
0 indicates central galaxy of the DHalo, 1 indicates a
satellite galaxy
|
| DHaloID |
long |
meta.id.assoc |
|
The ID of the DHalo this galaxy belongs to.
|
|
3.3.1.11 : Guo2010a
| (top) (separate page) |
|
The table Guo2010a stores the results of running the L-Galaxies code version described in
Guo etal (2010) on the halo merger trees in
the milli-Millennium simulation.
This table is a copy of the table mMR in the database Guo2010a, available for registered users only.
| column | type | UCD | unit | description |
|---|
| galaxyID | bigint | meta.id;meta.main | |
The unique identifier of this galaxy. Built from the topologically sorted merger tree as described in |
| haloID | bigint | meta.id.parent | |
The haloId of the subhalo (in the appropriate halo table) containing this galaxy. |
| firstProgenitorId | bigint | meta.id.assoc | |
Id of the main progenitor of this galaxy. Strictly galaxyId+1 iff lastProgenitorId > galaxyId, else -1 |
| nextProgenitorId | bigint | meta.id.assoc | |
galaxyId of next progenitor of this galaxy in the linked list structure used to facilitate traversing trees in code. |
| lastProgenitorId | bigint | meta.id.assoc | | The galaxyId of the last progenitor of this galaxy in the topological ordering used to assign galaxyId-s as described in TBD |
| fofCentralId | bigint | meta.id.assoc | | The galaxy id of the central galaxy of the FOF group this galaxy is in. |
| treeId | bigint | meta.id.parent | | Unique id of galaxy formation tree containing this galaxy. Note that this treeId does not identify merger trees but thelarger structures defining galaxy formation units.
The following equality holds:
treeId = 1000000*floor(galaxyId/1000000). |
| descendantId | bigint | meta.id.assoc | | galaxyId of the descendant of this galaxy in its merger tree. |
| mainLeafID | bigint | meta.id.assoc | | galaxyId of the leaf on the main branch this galaxy is part of. Obtained by following firstProgenitorId as far as it goes. |
| treeRootID | bigint | meta.id.assoc | | The galaxyId of the galaxy at the root of the merger tree this galaxy is in. Especially useful for speeding up queries for descendants for a given progenitor. See TBD for an example. |
| subHaloID | bigint | meta.id | | Id of the subhalo containing this galaxy,
as given by the column subhaloId in the millimil..FOFSubHalo table.
Alternative to haloId.
|
| fofID | bigint | meta.id.assoc | | The subhaloId (see previous column) of the subhalo at the center of the FOF group containing this galaxy.
|
| phkey | int | | | The Peano-Hilbert index of the cell this galaxy is in, in the 323 grid stored in millimil..MMField. |
| redshift | real | time | | The redshift corresponding to the snapnum (in millimil..Snapshots) for this galaxy. |
| type | int | src.class | | Type indicating whether galaxy is at center of FOF group (type=0), at center of subhalo that is not at center of its FOF gorup (type=1), or is a setellite that has lost its subhalo (type=2). |
| snapnum | int | time | | Snapshot index, from 0-63. |
| centralMvir | real | phys.veloc.dispersion | 1010 Msun/h | [description] |
| x | real | pos.cartesian.x | Mpc/h | X-component of position of galaxy. |
| y | real | pos.cartesian.y | Mpc/h | Y-component of position of galaxy. |
| z | real | pos.cartesian.z | Mpc/h | Z-component of position of galaxy. |
| velX | real | phys.veloc | km/s | The X-component of the physical peculiar velocity of the galaxy. |
| velY | real | phys.veloc | km/s | The Y-component of the physical peculiar velocity of the galaxy. |
| velZ | real | phys.veloc | km/s | The Z-component of the physical peculiar velocity of the galaxy. |
| np | int | meta.number | | Number of particles of the subhalo this galaxy is in. |
| mvir | real | phys.mass | 1010 Msun/h | Virial mass of the FOF group this galaxy was in when last it was a type 0 galaxy.
I.e. current mass for type 0 galaxies, "infall mass" for type 1,2 galaxies. |
| rvir | real | phys.size.radius | Mpc/h | Virial radius of the FOF group this galaxy was in when last it was a type 0 galaxy.
I.e. current Rvir for type 0 galaxies, "infall rvir" for type 1,2 galaxies |
| vvir | real | phys.veloc | km/s | Virial velocity of the subhalo the galaxy is/was the center of.
|
| vmax | real | phys.veloc.rotat | km/s | Maximum rotational velocity of the subhalo of which this galaxy is the center, or the last value for satellite galaxies.
|
| gasSpinX | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| gasSpinY | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| gasSpinZ | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| stellarSpinX | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| stellarSpinY | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| stellarSpinZ | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| infallVmax | real | phys.veloc.rotat | km/s | Maximum rotational velocity of the host halo of this galaxy at infallSnap. |
| infallSnap | int | time | | Most recent (largest) snapnum at which this galaxy's type changed from 0 to 1 or 2 |
| hotRadius | real | phys.size.radius | Mpc/h | Radius out to which hot gas extends: rvir for type 0; 0 for type 2; maximum radius out to which hot gas is not stripped for type 1. |
| oriMergeTime | real | [UCD] | 1339.77 Gyr | Estimated dyniamical friction time when the merger clock is set (in internal units of the code). |
| mergeTime | real | [UCD] | 1339.77 Gyr | Estimated remaining merging time. oriMergeTime - time since the merger clock is set. |
| coldGas | real | phys.mass | 1010 Msun /h | Mass in cold gas disk. |
| stellarMass | real | phys.mass | 1010 Msun /h | Total mass in stars in disk and bulge together. |
| bulgeMass | real | phys.mass | 1010 Msun /h | Mass of stars in bulge. |
| hotGas | real | phys.mass | 1010 Msun /h | Mass in hot gas. |
| ejectedMass | real | phys.mass | 1010 Msun /h | The ejected mass component (see de Lucia et al., 2004, MNRAS, Volume 349, 1101-1116).
|
| blackHoleMass | real | phys.mass | 1010 Msun /h | Mass of central black hole. |
| icmStellarMass | real | phys.mass | 1010 Msun /h | Mass in intra-cluster stars |
| metalsColdGas | real | phys.mass | 1010 Msun /h | Mass in metals in cold gas. |
| metalsStellarMass | real | phys.mass | 1010 Msun /h | Mass in metals in stars. |
| metalsBulgeMass | real | phys.mass | 1010 Msun /h | Mass in metals in stars in bulge. |
| metalsHotGas | real | phys.mass | 1010 Msun /h | Mass in metals in hot gas. |
| metalsEjectedMass | real | phys.mass | 1010 Msun /h | Mass in metals in the ejected mass component. |
| metalsICMStellarMass | real | phys.mass | 1010 Msun /h | Mass in metals in intra-cluster stars |
| sfr | real | phys.SFR | Msun/yr | Star formation rate |
| sfrBulge | real | phys.SFR | Msun/yr | Star formation rate in bulge. |
| xrayLum | real | em.X-Ray | log10(erg/sec) | Log10 of X-Ray luminosity in erg/sec |
| bulgeSize | real | phys.size.radius | Mpc/h | Half mass radius of bulge |
| stellarDiskRadius | real | phys.size.radius | Mpc/h | Size of the stellar disk, 3x the scale length. |
| gasDiskRadius | real | phys.size.radius | Mpc/h | Size of the gas disk, 3x the scale length. |
| disruptionOn | int | | | 0: galaxy merged onto merger center;
1: galaxy was disrupted before merging onto its descendant, matter went into ICM of merger center |
| mergeOn | int | | | 0: merger clock not set yet;
1: type 1 galaxy with baryon mass > halo mass, separate dynamical friction time calculated
2: this galaxy is type 2 and will merge into the merger center in the next snapshot
3: this galaxy is type 1 and will merge into the central galaxy of the main halo in the next snapshot |
| coolingRadius | real | phys.size.radius | Mpc/h | The radius within which the cooling time scale is shorter than the dynamical timescale
|
| u_mag | real | phot.mag;em.opt.U | | Rest frame total absolute magnitudes, SDSS u band. |
| g_mag | real | phot.mag;em.opt.B | | Rest frame total absolute magnitude, SDSS g band. |
| r_mag | real | phot.mag;em.opt.R | | Rest frame total absolute magnitude, SDSS r band. |
| i_mag | real | phot.mag;em.opt.I | | Rest frame total absolute magnitude, SDSS i band. |
| z_mag | real | phot.mag;em.opt | | Rest frame total absolute magnitude, SDSS z band. |
| uBulge | real | phot.mag;em.opt.U | | Rest frame absolute magnitude of bulge, SDSS u band. |
| gBulge | real | phot.mag;em.opt.B | | Rest frame absolute magnitude of bulge, SDSS g band. |
| rBulge | real | phot.mag;em.opt.R | | Rest frame absolute magnitude of bulge, SDSS r band. |
| iBulge | real | phot.mag;em.opt.I | | Rest frame absolute magnitude of bulge, SDSS i band. |
| zBulge | real | phot.mag;em.opt | | Rest frame absolute magnitude of bulge, SDSS z band. |
| uDust | real | phot.mag;em.opt.U | | Rest frame total absolute magnitude, SDSS u band, dust extinction included.
|
| gDust | real | phot.mag;em.opt.B | | Rest frame total absolute magnitude, SDSS g band, dust extinction included. |
| rDust | real | phot.mag;em.opt.R | | Rest frame total absolute magnitude, SDSS r band, dust extinction included. |
| iDust | real | phot.mag;em.opt.I | | Rest frame total absolute magnitude, SDSS i band, dust extinction included. |
| zDust | real | phot.mag;em.opt | | Rest frame total absolute magnitude, SDSS z band, dust extinction included. |
| massweightedAge | real | time.age | 109yr | The age of this galaxy, weighted by mass of its components. |
| uICL | real | phot.mag;em.opt.U | | Rest frame absolute magnitude of ICL, SDSS u band. |
| gICL | real | phot.mag;em.opt.B | | Rest frame absolute magnitude of ICL, SDSS i band |
| rICL | real | phot.mag;em.opt.R | | Rest frame absolute magnitude of ICL, SDSS i band |
| iICL | real | phot.mag;em.opt.I | | Rest frame absolute magnitude of ICL, SDSS i band |
| zICL | real | phot.mag;em.opt | | Rest frame absolute magnitude of ICL, SDSS i band |
|
3.3.2 : Snapshots
| (top) (separate page) |
|
Most tables available through this web site have an integer "snapnum" column.
This column indexes the output snapshots from the different simulations described
here.
Each snapshot corresponds to a different redshift. And though the redshifts are generally also stored in the catalogues,
it is in general MUCH more efficient to base queries for specific snapshots on the snapnum column.
When indexes have been defined for speeding up requests for particular snapshots, almost always the snapnum column
has been used.
The relation between snapnum and redshift varies between simulations, and also between original versions of the
catalogues and their counterparts scaled to different cosmologies.
This database contains the following tables describing these relations:
- MR: snapshots from original Millennium and milli-Millennium simulations.
Equivalent to millimil..Snapshots and MField..Snapshots
- MRII: snapshots from original Millennium-II and mini-Millennium-II simulations.
Equivalent to MillenniumII..Snapshots
- MR7: snapshots from WMAP7-Millennium simulation
- MRscWMAP7: snapshots from Millennium scaled to WMAP7 cosmology. NOTE the last snapshot (63) corresponds to
negative redshift, i.e. is in the future!
Redshift 0 corresponds to snapshot 53.
- MRIIscWMAP7: snapshots from Millennium-II scaled to WMAP7 cosmology. NOTE the last snapshot (67) corresponds to negative redshift, i.e. is in the future!
Redshift 0 corresponds to snapshot 57.
All tables have the same design:
| column | type | UCD | unit | description |
| snapnum | integer | | | The index of the snapshot in the list of outputs orderd by time. |
| a | real | | | The scale factor t the time of this snapshot |
| z | real | | | The redshift in full precision |
| Hz | real | | km/s/Mpc | The Hubble parameter at the time of this snapshot |
| lookBackTime | real | | 109 years | The lookback time corresponding to the snapshot |
To find the relation between redshift and snapnum simply run a query like the following:
select *
from snapshots..MRscWMAP7
|
3.3.3 : MMSnapshots
| (top) (separate page) |
|
This database contains tables with the original dark matter particles from the milli-Millennium simulation.
There is also a table linking the particles to particular FOF groups and/or
sub-halos they belong to.
This database also contains a number of so called User Defined Functions (UDF-s)
that can be used to efficiently create spatial subsets of the particle distribution.
To call a function you should add the "dbo." schema name in front of the function name.
And the databas ename itself should also be included.
-
select *
from mmsnapshots.dbo.mmsnapshotpointsinbox(snapnum,xmin,ymin,zmin,xmax,ymax,zmax)
returns a table with particles [x,y,z,vx,vy,vz,id] in the box given by the xmin..zmax parameters at the given snapnum.
(Of course numerical values should be substituted for the parameters).
This function takes periodicity of the simulation box into account. I.e. the box may cross the boundary of the box.
-
select *
from mmsnapshots.dbo.mmsnapshotpointsinsphere(snapnum,x,y,z,radius)
returns a table with particles [r,x,y,z,vx,vy,vz,id] in the sphere given by the center and radius at the given snapnum.
This function takes periodicity of the simulation box into account. I.e. the sphere may cross the boundary of the box.
The r column gives the distance to the center of the sphere.
|
3.3.3.1 : MillimilSnapshots
| (top) (separate page) |
|
This table contains the dark-matter particles of the milli-Millennium simulation.
Ordered by Snapnum and phKey. This is used in a number of functions that
can query the particles in subvolumes (sphere and boxes) of the simulation volume.
| column | type | UCD | unit | description |
|---|
|
snapnum |
smallint |
|
|
The identifier of the snapshot for the particle. See the
millimil..snapshots table to find the redshift
and other time variables corresponding to this snapnum. |
|
phkey |
int |
|
|
The Peano-Hilbert key corresponding to the position of this particle. Based on a 323 grid. |
|
x |
real |
|
Mpc/h |
|
|
y |
real |
|
Mpc/h |
|
|
z |
real |
|
Mpc/h |
|
|
vx |
real |
|
km/s |
|
|
vy |
real |
|
km/s |
|
|
vz |
real |
|
km/s |
|
|
id |
bigint |
|
|
The unique identifier of this particle. Allows one to trace the particle in different timesteps
and is also the ID used by the MillimilSnapshotIDs table linking the particle to FOF groups and
Subhalos. |
|
3.3.3.2 : MillimilSnapshotIDs
| (top) (separate page) |
|
This table allows one to find the particles belonging to a given FOF group or sub-halo.
| column | type | UCD | unit | description |
|---|
| snapNum |
short |
time |
|
The snapshot number where this particle-to-FOF group(c.q. sub-halo) association is defined.
|
| particleId |
long |
meta.id;meta.main |
|
The id of the particle, unique in this table for a given snapnum. Corresponds to the id column in the
MillimilSnapshots table. |
| fofId |
long |
meta.id;meta.assoc |
|
The id of the FOF group to which this particle belongs.
|
| subhaloId |
long |
meta.id;meta.assoc |
|
The id of the sub-halo to which this particle belongs. May be NULL if the particle does belong to a
FOF group but not to a sub-halo. |
|
3.3.4 : MField
| (top) (separate page) |
|
The MField database stores the dark matter density fluctuation field smoothed with various
smoothing radii (in the MField table) and information about the snapshots of the simulation.
The goal of the MField table is to give a simplistic way to find out information about the environment
of an object. To this end each grid cell is identified by its Penao-Hilbert key. This same key has been assigned to
all objects (halos and galaxies), in that case identifying the cell they reside in. For a given object the
environment is now a simple lookup of the corresponding cell in the density field table.
|
3.3.4.1 : Snapshots
| (top) (separate page) |
This table stores some housekeeping information of the Millennium simulation. In particular, it links
redshifts and lookback times to the integer index of the snapshot. Almost all other tables in the various
Millennium databases have a snapnum column that corresponds to the one in this table.
| column | type | features | description |
| snapnum | integer | NOT NULL | The order of the snapshot, from 0 to 63 (z=0) |
| z | double | NOT NULL | The redshift in full precision |
| redshift | decimal(5,2) | NOT NULL | The redshift to exactly two decimal places. |
| lookBackTime | float | NOT NULL | The lookback time in 109 years |
|
3.3.4.2 : MField
| (top) (separate page) |
This table stored the dark matter density field put on a 2563 density grid.
It stores both simple count in cells and also the values of the density field smoothed with
a Gaussian kernel of various sizes.
| column | type | UCD | unit | description |
|---|
| snapnum |
int |
time |
|
The snapshot number for this field.
This column corresponds to the snapnum column in
the Snapshots table in MField.
|
| phkey |
int |
|
|
The Peano-Hilbert key for this grid cell.
|
| cic |
float |
phys.density |
|
The counts-in-cell density in the grid cell, normalized by mean density.
I.e. cic*10077696000/2563 gives the number of particles in each cell.
|
| g1_25 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 1.25 Mpc/h, normalized by mean density.
|
| g2_5 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 2.5 Mpc/h, normalized by mean density.
|
| g5 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 5 Mpc/h, normalized by mean density.
|
| g10 |
float |
phys.density |
|
The density field smoothed with a Gaussian smoothing and radius 10 Mpc/h, normalized by mean density.
|
|
3.3.4.3 : FOF
| (top) (separate page) |
|
The table stores all the friend-of-friends (FOF) groups extracted from the raw output from Millennium
simulation. These FOF groups form the basis that the SUBFIND algorithm uses to detect the subhalos.
| column | type | UCD | unit | description |
|---|
| fofId |
long |
meta.id;meta.main |
|
The id of this FOF group, unique within the full simulation.
|
| snapNum |
int |
time |
|
The snapshot number where this FOF group was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this halo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this FOF group.
|
| numSubGroups |
int |
meta.number |
|
The number of sub halos found in this FOF group with the SUBFIND algorithm.
These subhalos are stord in the FofSubHalo table in this same database.
|
| firstSubHaloId |
long |
|
meta.id.assoc |
The identifier of the most massive subhalo in this FOF group.
NB This is not equivalent to the fofID in MPAGalxies..DeLucia2006a or the firstHaloInFOFGroupId in MPAHalotrees..MHalo! |
| m_Mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the mean density of the simulation.
|
| r_mean200 |
float |
phys.mass |
Mpc/h |
The (comoving) radius within which the FOF group has an overdensity 200 times the mean density of the simulation.
|
| m_Crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the critical density of the simulation.
|
| r_crit200 |
float |
phys.mass |
Mpc/h |
The (comoving) radius within which the FOF group has an overdensity 200 times the critical density of the simulation.
|
| m_tophat200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity corresponding to the value at virialisation in the top-hat collapse model for this cosmology.
|
| r_tophat200 |
float |
phys.mass |
Mpc/h |
The (comoving) radius within which the FOF group has an overdensity corresponding to the value at virialisation in the top-hat collapse model for this cosmology.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the position in comoving coordinates.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this FOF group.
See the text on spatial indexes.
|
| zIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 50 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 50 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 50 bins
See the text on spatial indexes.
|
| random |
integer |
|
|
Random number between 0 and 1000000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.4.4 : FofSubHalo
| (top) (separate page) |
|
The table stores all the subhalos identified with the SUBFIND algorithm in the friends-of-friends groups
that are stored in the FOF table in this same database.
| column | type | UCD | unit | description |
|---|
| fofId |
long |
meta.id.assoc |
|
The id of the parent FOF group in which this subhalo is embedded.
|
| subhaloId |
long |
meta.id;meta.main |
|
The identifier of this subhalo, unique within the full simulation.
|
| snapNum |
int |
time |
|
The snapshot number where this halo was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField. |
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
|
3.3.4.5 : Spatial
| (top) (separate page) |
|
This table stores coordinates and indexes for cells in the MField table.
It allows one to translate between the Peano-HIlbert index (phkey) of a cell and its discrete cartesian coordinates (ix,iy,iz).
NOTE the (ix,iy,iz) coordinates have values in [-1,256], not in [0,255]!
The motivation for this is that it makes it somewhat easier to deal with periodic boundary conditions when
querying for the neighbours of a cell identified by its phkey:
select s2.phkey
from mfield..spatial s1
, mfield..spatial s2
where s1.phkey=123456
and s1.ix between 0 and 255
and s1.iy between 0 and 255
and s1.iz between 0 and 255
and s2.ix between s1.ix-1 and s1.ix+1
and s2.iy between s1.iy-1 and s1.iy+1
and s2.iz between s1.iz-1 and s1.iz+1
| column | type | UCD | unit | description |
|---|
| ix |
integer |
pos.cart.x |
|
The discrete x coordinate of the cell. Values between -1 and 256.
|
| iy |
integer |
pos.cart.y |
|
The discrete y coordinate of the cell. Values between -1 and 256.
|
| iz |
integer |
pos.cart.z |
|
The discrete z coordinate of the cell. Values between -1 and 256.
|
| phkey |
integer |
|
|
The Peano-Hilbert index of the cell. |
| zindex |
integer |
time |
|
The bit-interleaving index of the cell. |
|
3.3.5 : MPAHaloTrees
| (top) (separate page) |
|
This database contains the results of the merger tree determination ala MPA.
See here for details of this algorithm.
For details about the storage of these trees in the database see
this page.
|
3.3.5.1 : Tables
| (top) (separate page) |
|
The database MPAHalotrees contains various tables storing sub-halo merging trees
in a representation that allows efficient
querying for merger histories. For a description how these merger trees were constructed see
Springel2005a
and DeLucia2006b.
For a description of how the merger trees are stored in these tables to allow efficient querying of
their structure and example queries, see the discussion on
this page.
There are currently 5 tables stored in this database, all of them with the same structure documented in the table below.
The tables MR, MRII, MR7 store the subhalos extracted from the Millennium, Millennium-II and Millennium-WMAP7 simulations.
(See here for the description of the simulations).
The tables MRscWMAP7 and MRIIscWMAP7 contain the merger trees from MR and MRII respectively,
but scaled to WMAP 7 cosmology according to the algorithm presented in
Angulo & White (2010).
Note, before the update to the database from 2013-02-26, the table currently named MR was represented by
a table named MHalo. This table is not exactly the same as the current version, but for backwards compatibility
we make MR available also as MHalo. Similarly, for the time being we left the original version of the Millennium-II merger trees in the
table MillenniumII..HaloTree.
For queries aiming to retrieve halos at a particular snapshot one should use the snapnum column to select
the precise snapshot. That column is always used in table indexes
Note that the relation between the snapnum and redshift values varies between the different tables.
See the tables in the Snapshots database
for tables with the different snaphot lists for the precise relations.
| column | type | UCD | unit | description |
| haloId |
long |
meta.id;meta.main |
|
The primary key of this sub-halo in the merger tree, unique within the full simulation.
See the documentation on merger trees for further
details on the structure of merger trees in the database.
|
| subhaloFileId |
long |
meta.id; |
|
Column identifying the counterpart of this subhalo in the original SUBFIND result files.
For the tables MR and MRscWMAP7 this is a
foreign key identifying
the subhaloId column in the
MField..FOFSubHalo table.
For MRII and MRIIscWMAP7 this is a
foreign key identifying
the subhaloFileId column in the
MillenniumII..SubHalo table.
For MR7 there is as yet no counterpart table in the database for this foreign key.
|
| treeRootId |
long |
meta.id.parent |
|
Foreign key identifying the subhalo
at the root of the merger tree containing this halo. This column is especially useful for improving the performance
of queries that aim to retrieve descendants of known progenitors. Note that this root halo is not necessarily at z=0,
there are some trees in the database that do not extend down to the last snapshot.
See the documentation on merger trees for further
details on querying merger trees.
|
| descendantId |
long |
meta.id.assoc |
|
Foreign key identifying the unique descendant of this subhalo in the merger tree. -1 if there is no descendant.
This is the case for all halos at z=0, and for some halos at earlier times (see treeRootId).
|
| lastProgenitorId |
long |
meta.id.assoc |
|
Foreign key identifying
the last progenitor in the subhalo merger tree rooted in this subhalo.
All subhalos with haloId between haloId and lastProgenitorId from the merger tree rooted in this subhalo.
See the documentation on merger trees for further
details on the structure of merger trees in the database. |
| mainLeafId |
long |
meta.id.assoc |
|
Foreign key identifying
the last progenitor along the main branch in the subhalo merger tree for this subhalo.
All subhalos with haloId between this halo's haloId and mainLeafId make up the main progenitor branch for this subhalo.
See the documentation on merger trees for further
details on the structure of merger trees in the database. |
| firstProgenitorId |
long |
meta.id.assoc |
|
Foreign key identifying the main progenitor of this subhalo.
See this page and
this page for more details on the definition
of this column.
|
| nextProgenitorId |
long |
meta.id.assoc |
|
Foreign key identifying the "next progenitor" in the subhalo merger trees (the "next progenitor" of a subhalo S is
the next most massive subhalo that has the same descendant as subhalo S).
See this page for more details on the definition
of this column.
|
| firstHaloInFOFgroupId |
long |
meta.id.assoc |
|
Foreign key identifying the dominant subhalo of the friend-of-friends group to which this subhalo belongs.
See this page for more details on the definition
of this column.
|
| nextHaloInFOFgroupId |
long |
meta.id.assoc |
|
Foreign key identifying the next most massive halo within the same FOF group.
|
| snapNum |
int |
time |
|
The snapshot number where this subhalo was identified.
This column is a
foreign key to the snapnum column in the
table
in the Snapshots database
with the same name as the current HaloTrees table.
I.e. Snapshots..MR,Snapshots..MRII,Snapshots..MR7, Snapshots..MRscWMAP7 or Snapshots..MRIIscWMAP7
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this subhalo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
| m_crit200 |
float |
phys.mass |
1010 Msun/h |
This column has two different usages depending on whether the current halo is at the center of its FOF group or not.
A halo is a memer of its FOF group iff haloId=firstHaloInFOFgroupId.
In that case this column represents the mass within the radius where the subhalo has an overdensity 200 times the critical density of the simulation.
In case the halos is not a center, i.e. if it is a satellite halo, this column stores the m_crit200 value of the
progenitor subhalo on the main branch that was for the last time at the center of ots FOF group.
For more information about this definition see this page.
In the rare case where there is no main-progenitor that was a center of its FOF group (i.e. if the subhalo was born as satellite halo), the value of this column is set to 0.
|
| m_mean200 |
float |
phys.mass |
1010 Msun/h |
For halos at the center of their FOF group, this column stores the mass
within the radius where the subhalo has an overdensity 200 times the mean density of the simulation.
For satellite halos it stores the m_mean200 value of the last main-progenitor that was a center of its subhalo (see also the description of the m_crit200 column).
If the halo never was a center the value is set to 0.
|
| m_tophat |
float |
phys.mass |
1010 Msun/h |
For halos at the center of their FOF group, this column stores the mass within the radius where the subhalo has an overdensity corresponding to the value at virialisation in the
top-hat collapse model for this cosmology.
For satellite halos it stores the m_tophat value of the last main-progenitor that was a center of its subhalo
(see also the description of the m_crit200 column).
If the halo never was a center the value is set to 0.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the subhalo's position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the subhalo's position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the subhalo's position in comoving coordinates.
|
| phKey |
int |
|
|
The Peano-Hilbert index based on a 2563 grid for the position of this subhalo.
See this page for more information.
For the MR simulation, this column together with the snapnum column is a
foreign key identifying the cell
in the density field in the MField..MField table.
|
| velX |
float |
phys.veloc |
km/sec |
The X-component of the subhalo's peculiar velocity.
|
| velY |
float |
phys.veloc |
km/sec |
The Y-component of the subhalo's peculiar velocity.
|
| velZ |
float |
phys.veloc |
km/sec |
The Z-component of the subhalo's peculiar velocity.
|
| vDisp |
float |
phys.veloc.dispersion |
km/sec |
The 1-D velocity dispersion of the subhalo, computed from all of the subhalo particles.
|
| vMax |
float |
phys.veloc.rotat |
km/sec |
Maximum of the circular velocity curve vCirc, where
vCirc2=G M(< r)/r
The maximum is determined from the expression calculated for each particles in the halo,
i.e. from: maxi(G*(i-1)*mp/ri) |
| vMaxRad |
float |
|
Mpc/h |
The radius at which the circular velocity maximum vMax is attained
|
| spinX |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The X-component of the spin of the subhalo.
|
| spinY |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Y-component of the spin of the subhalo.
|
| spinZ |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Z-component of the spin of the subhalo.
|
| mostBoundID |
long |
meta.id.assoc |
|
The id of the most bound particle of this subhalo.
|
| fileNr |
int |
meta.file;meta.id |
|
Original file number in which the subhalo was defined.
See the documentation on identifiers for its
role in defining the haloId.
|
| subhaloIndex |
int |
meta.id.assoc |
|
Index of this subhalo in the file identified by fileNr.
|
| subhaloFileId |
long |
meta.id; |
|
This column corresponds to the subhaloFileId in the SubHalo table and gives an alternative way of identifying that halo.
This is an older way of identifying that subhalo, it is better to use the subhaloId column instead.
|
| halfmassRadius |
REAL |
phys.size.radius |
Mpc/h |
Radius containing half of the mass of the subhalo.
|
| lastCentralId |
BIGINT |
meta.id; |
|
Foreign key identifying the most recent progenitor subhalo on the main branch that was at the center of its friends-of-friends group.
I.e. if the current subhalo is a center, this value will equal its own haloId.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case this column has the value -1.
The m_crit200, m_mean200, m_tophat columns store the corresponding mass of this identified halo, whether it is
the halo itself or a progenito. |
| lastCentralSnap |
INTEGER |
TBD |
|
The snapnum of the most recent progenitor subhalo on the main branch that was at the center of its friends-of-friends group.
I.e. if the current subhalo is a center, this value will equal its own snapnum.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case the lastCentralId column
has the value -1, and the current column's value is also set at the non-physical value of -1. |
| lastCentralVmax |
REAL |
TBD |
|
The vMax of the most recent progenitor subhalo on the main branch that was at the center of its friends-of-friends group.
I.e. if the current subhalo is a center, this value will equal its own vMax.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case the lastCentralId column
has the value -1, and the current column's value is set to 0. |
| peakMassId |
BIGINT |
meta.id; |
|
Foreign key identifying the progenitor subhalo on the main branch that was a central subhalo of its FOF group and has the largest value of m_crit200.
I.e. if the current subhalo is a center and the most massive of all such halos on the main branch "above"
this halo, this value will equal its own haloId.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case the lastCentralId column
has the value -1, and the current column's value is also set to -1. |
| peakMassSnap |
INTEGER |
TBD |
|
The snapnum of the halo identified by the peakMassId column.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case the lastCentralId column
has the value -1, and the current column's value is also set to -1. |
| peakMassMcrit |
REAL |
TBD |
|
The m_crit200 value of the halo identified by the peakMassId column.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case the lastCentralId column
has the value -1, and the current column's value is set to 0. |
| peakMassVmax |
REAL |
TBD |
|
The vMax value of the halo identified by peakMassId column, i.e. of the most massive progenitor.
IMPORTANT there are rare cases where a subhalo was never at the center of a FOF group, in that case the lastCentralId column
has the value -1, and the current column's value is set to 0. |
| treeId |
BIGINT |
meta.id.parent |
|
The unique identifier of the L-Galaxies galaxy formation "tree" to which this subhalo belongs.
See the page on the MPA trees for a description of these "trees".
The value of this column is related to the haloId. For MR, MR7 and MRscWMAP7 the relation is
treeId=floor(haloid/100000000)
For MRII and MRIIscWMAP7 the relation is
treeId=floor(haloid/1000000000)
|
|
3.3.6 : MPAGalaxies
| (top) (separate page) |
|
This database stores the results of different L-Galaxies semi-analytical galaxy formation runs
on the Millenium simulation's MPA halo merger trees.
|
3.3.6.1 : DeLucia2006a
| (top) (separate page) |
|
This table contains the full result of the L-Galaxies run used in
De Lucia and Blaizot 2006.
Note that galaxies without stars have been assigned the value 99 for all their magnitudes.
| column | type | UCD | unit | description |
|---|
| galaxyID |
long |
meta.id;meta.main |
|
ID of galaxy, unique within simulation and SAM run. |
| lastProgenitorId |
long |
meta.id.assoc |
|
All galaxies with id between this galaxyId and this lastProgenitorId together are the merger tree rooted in this galaxy.
|
| descendantId |
long |
meta.id.assoc |
|
Pointer to the descendant of this galaxy in its merger tree; -1 if there is no descendant
|
| haloID |
long |
meta.id.parent |
|
Unique ID of MPA halo containing this galaxy
|
| subHaloID |
long |
meta.id; |
|
The ID of the sub-halo this galaxy resides in. Identical to the subhaloId of the halo identified by the haloId. |
| fofID |
long |
meta.id; |
|
The id of the sub-halo at the center of the friends-of-friends (FOF) this galaxy resides in.
NB This is not equivalent to the firstSubhaloID column in the MField..FOF table! |
| treeId |
long |
meta.id.parent |
|
unique id of galaxy formation tree containing this galaxy
The following equality holds: treeId = 1000000*floor(galaxyId/1000000).
|
| firstProgenitorId |
long |
meta.id.assoc |
|
Main progenitor of this galaxy. Also the first progenitor in a linked list representation of the merger tree. |
| nextProgenitorId |
long |
meta.id.assoc |
|
Next progenitor of this galaxy in linked list representation of merger tree
|
| type |
int |
src.class |
|
0,1 or 2 indicating whether this galaxy is a central galaxy of its FOF group, central galaxy of a subhalo, or a satellite galaxy. |
| snapnum |
int |
time |
|
The snapshot number where this galaxy was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField.
|
| redshift |
float |
time |
|
redshift of the snapshot where this galaxy resides
|
| centralMvir |
float |
phys.veloc.dispersion |
1010/h Msun |
virial mass of background (FOF) halo containing this galaxy
|
| phkey |
int |
|
|
Peano-Hilbert key, (bits=8), for position in 500/h Mpc box
See the text on spatial indexes.
|
| x |
float |
pos.cartesian.x |
1/h Mpc |
x-component position
|
| y |
float |
pos.cartesian.y |
1/h Mpc |
y-component position
|
| z |
float |
pos.cartesian.z |
1/h Mpc |
z-component position
|
| zCurveIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this galaxy's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 50 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 50 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 50 bins
See the text on spatial indexes.
|
| velX |
float |
phys.veloc |
km/s |
x-component velocity
|
| velY |
float |
phys.veloc |
km/s |
y-component velocity
|
| velZ |
float |
phys.veloc |
km/s |
z-component velocity
|
| np |
int |
meta.number |
|
Number of particles in halo the galaxy belongs to.
|
| mvir |
float |
phys.mass |
1010/h Msun |
Virial mass of the subhalo the galaxy is/was the center of.
|
| rvir |
float |
phys.size.radius |
Mpc/h |
Virial radius of the subhalo the galaxy is/was the center of.
|
| vvir |
float |
phys.veloc |
km/s |
Virial velocity of the subhalo the galaxy is/was the center of.
|
| vmax |
float |
phys.veloc.rotat |
km/s |
Maximum rotational velocity of the subhalo of which this galaxy is the center, or the last value for satellite galaxies.
|
| coldGas |
float |
phys.mass |
1010/h Msun |
Mass in cold gas.
|
| stellarMass |
float |
phys.mass |
1010/h Msun |
Mass in stars.
|
| bulgeMass |
float |
phys.mass |
1010/h Msun |
Mass of bulge.
|
| hotGas |
float |
phys.mass |
1010/h Msun |
Mass in hot gas component of this galaxy's subhalo. TBD on type 2 galaxies.
|
| ejectedMass |
float |
phys.mass |
1010/h Msun/h |
The ejected mass component (see de Lucia et al., 2004, MNRAS, Volume 349, 1101-1116).
|
| blackHoleMass |
float |
phys.mass |
1010/h Msun |
Mass of central black hole
|
| metalsColdGas |
float |
phys.mass |
1010/h Msun |
Mass in metals in cold gas.
|
| metalsStellarMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in stars.
|
| metalsBulgeMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in bulge.
|
| metalsHotGas |
float |
phys.mass |
1010/h Msun |
ratio of mass in metals.
|
| metalsEjectedMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in ejected gas.
|
| sfr |
float |
phys.SFR |
Msun/yr |
Star formation rate
|
| sfrBulge |
float |
phys.SFR |
Msun/yr |
Star formation rate in the bulge.
|
| xrayLum |
float |
em.X-Ray |
TBD |
X-Ray luminosity
|
| diskRadius |
float |
phys.size.radius |
Mpc/h |
Disk radius, derived form halo radius ala
Mo, Mao and White (1997) |
| coolingRadius |
float |
phys.size.radius |
Mpc/h |
The radius within which the cooling time scale is shorter than the dynamical timescale
|
| mag_b |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega) of galaxy.
|
| mag_v |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega) of galaxy
|
| mag_r |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega) of galaxy.
|
| mag_i |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega) of galaxy.
|
| mag_k |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega) of galaxy.
|
| mag_bBulge |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega) of bulge
|
| mag_vBulge |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega) of bulge
|
| mag_rBulge |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega) of bulge
|
| mag_iBulge |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega) of bulge
|
| mag_kBulge |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega) of bulge
|
| mag_bDust |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega), dust extinction included
|
| mag_vDust |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega), dust extinction included
|
| mag_rDust |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega), dust extinction included
|
| mag_iDust |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega), dust extinction included
|
| mag_kDust |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega), dust extinction included
|
| massWeightedAge |
float |
|
109 yr |
The age of this galaxy, weighted by mass of their components. |
| random |
integer |
|
|
Random number between 0 and 1000000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.6.2 : DeLucia2006a_SDSS2MASS
| (top) (separate page) |
|
This table contains SDSS and 2MASS observer frame magnitudes for the galaxy catalogue in
the DeLucia2006a table in this same database.
| column | type | UCD | unit | description |
|---|
| galaxyID |
long |
meta.id;meta.main |
|
ID of galaxy, unique within simulation and SAM run. This ID is the same as that in the DeLucia2006a table. |
| snapnum |
int |
time |
|
The snapshot number where this galaxy was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField.
|
| u_sdss |
float |
|
|
Absolute observer frame SDSS u magnitude (AB), dust extinction included
|
| g_sdss |
float |
|
|
Absolute observer frame SDSS g magnitude (AB), dust extinction included
|
| r_sdss |
float |
|
|
Absolute observer frame SDSS r magnitude (AB), dust extinction included
|
| i_sdss |
float |
|
|
Absolute observer frame SDSS i magnitude (AB), dust extinction included
|
| z_sdss |
float |
|
|
Absolute observer frame SDSS z magnitude (AB), dust extinction included
|
| J_2mass |
float |
|
|
Absolute observer frame 2MASS J magnitude (AB), dust extinction included
|
| H_2mass |
float |
|
|
Absolute observer frame 2MASS H magnitude (AB), dust extinction included
|
| K_2mass |
float |
|
|
Absolute observer frame 2MASS K magnitude (AB), dust extinction included
|
|
3.3.6.3 : Bertone2007a
| (top) (separate page) |
|
This table contains the full result of the L-Galaxies
run used in Bertone, De Lucia and Thomas 2007 (ADS).
Note that galaxies without stars have been assigned the value 99 for
all their magnitudes.
Wind properties are assigned a value of zero when a galaxy is not
blowing a wind (Bubble=0).
| column |
type |
UCD |
unit |
description |
| galaxyID |
long |
meta.id;meta.main |
|
ID of galaxy, unique within simulation and SAM run. |
| lastProgenitorId |
long |
meta.id.assoc |
|
All galaxies with id between this galaxyId and
this lastProgenitorId together are the merger tree rooted in this
galaxy.
|
| descendantId |
long |
meta.id.assoc |
|
Pointer to the descendant of this galaxy in its
merger tree; -1 if there is no descendant
|
| haloID |
long |
meta.id.parent |
|
Unique ID of MPA halo containing this galaxy
|
| subhaloID |
long |
meta.id; |
|
The ID of the sub-halo this galaxy resides in.
Identical to the subhaloId column of the halo identified by the haloId. |
| fofId |
long |
meta.id.assoc |
|
The subhaloId of the sub-halo at the center of the FOF group that this galaxy is contained in.Br>
NB This is not equivalent to the firstSubhaloID column in the MField..FOF table! |
| treeId |
long |
meta.id.assoc |
|
unique id of galaxy formation tree containing this galaxy
The following equality holds: treeId = 1000000*floor(galaxyId/1000000). |
| firstProgenitorId |
long |
meta.id.assoc |
|
Main progenitor of this galaxy. Also the first
progenitor in a linked list representation of the merger tree. |
| nextProgenitorId |
long |
meta.id.assoc |
|
Next progenitor of this galaxy in linked list
representation of merger tree
|
| type |
int |
src.class |
|
0,1 or 2 indicating whether this galaxy is a
central galaxy of its
FOF group, central galaxy of a subhalo, or a satellite galaxy. |
| snapnum |
int |
time |
|
The snapshot number where this galaxy was
identified.
This column corresponds to the snapnum column in
the Snapshots
table in this database.
|
| redshift |
float |
time |
|
redshift of the snapshot where this galaxy resides
|
| centralMvir |
float |
phys.veloc.dispersion |
1010/h Msun |
virial mass of background (FOF) halo containing
this galaxy
|
| phkey |
int |
|
|
Peano-Hilbert key, (bits=5), for position in
62.5/h Mpc box
See the text on spatial
indexes.
|
| x |
float |
pos.cartesian.x |
1/h Mpc |
x-component position
|
| y |
float |
pos.cartesian.y |
1/h Mpc |
y-component position
|
| z |
float |
pos.cartesian.z |
1/h Mpc |
z-component position
|
| zCurveIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this galaxy's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 50 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 50 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 50 bins
See the text on spatial indexes.
|
| velX |
float |
phys.veloc |
km/s |
x-component velocity
|
| velY |
float |
phys.veloc |
km/s |
y-component velocity
|
| velZ |
float |
phys.veloc |
km/s |
z-component velocity
|
| np |
int |
meta.number |
|
Number of particles in halo the galaxy belongs to.
|
| mvir |
float |
phys.mass |
1010/h Msun |
Virial mass of the subhalo the galaxy is/was the
center of.
|
| rvir |
float |
phys.size.radius |
Mpc/h |
Virial radius of the subhalo the galaxy is/was
the center of.
|
| vvir |
float |
phys.veloc |
km/s |
Virial velocity of the subhalo the galaxy is/was
the center of.
|
| vmax |
float |
phys.veloc.rotat |
km/s |
Maximum rotational velocity of the subhalo of
which this galaxy is the center, or the last value for satellite
galaxies.
|
| coldGas |
float |
phys.mass |
1010/h Msun |
Mass in cold gas.
|
| stellarMass |
float |
phys.mass |
1010/h Msun |
Mass in stars.
|
| bulgeMass |
float |
phys.mass |
1010/h Msun |
Mass of bulge.
|
| hotGas |
float |
phys.mass |
1010/h Msun |
Mass in hot gas component of this galaxy's
subhalo. TBD on type 2 galaxies.
|
| ejectedMass |
float |
phys.mass |
1010/h Msun/h |
Mass in a collapsed wind to be reincorporated at
the next timestep
|
| blackHoleMass |
float |
phys.mass |
1010/h Msun |
Mass of central black hole
|
| metalsColdGas |
float |
phys.mass |
1010/h Msun |
Mass in metals in cold gas.
|
| metalsStellarMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in stars.
|
| metalsBulgeMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in bulge.
|
| metalsHotGas |
float |
phys.mass |
1010/h Msun |
ratio of mass in metals.
|
| metalsEjectedMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in a collapsed wind to be
reincorporated at the next timestep |
| metalsblackHoleMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in central black hole.
|
| sfr |
float |
phys.SFR |
Msun/yr |
Star formation rate
|
| sfrBulge |
float |
phys.SFR |
Msun/yr |
Star formation rate in the bulge.
|
| xrayLum |
float |
em.X-Ray |
TBD |
X-Ray luminosity
|
| diskRadius |
float |
phys.size.radius |
Mpc/h |
Disk radius, derived form halo radius ala Mo, Mao and White (1997) |
| coolingRadius |
float |
phys.size.radius |
Mpc/h |
The radius within which the cooling time scale is
shorter than the dynamical timescale
|
| mag_b |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude
(Vega) of galaxy.
|
| mag_v |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude
(Vega) of galaxy
|
| mag_r |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter)
magnitude (Vega) of galaxy.
|
| mag_i |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter)
magnitude (Vega) of galaxy.
|
| mag_k |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter)
magnitude (Vega) of galaxy.
|
| sdss_u |
float |
|
|
Absolute rest frame SDSS u magnitude (AB) |
| sdss_g |
float |
|
|
Absolute rest frame SDSS g magnitude (AB) |
| sdss_r |
float |
|
|
Absolute rest frame SDSS r magnitude (AB) |
| sdss_i |
float |
|
|
Absolute rest frame SDSS i magnitude (AB) |
| sdss_z |
float |
|
|
Absolute rest frame SDSS z magnitude (AB) |
| mag_bBulge |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude
(Vega) of bulge
|
| mag_vBulge |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude
(Vega) of bulge
|
| mag_rBulge |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter)
magnitude (Vega) of bulge
|
| mag_iBulge |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter)
magnitude (Vega) of bulge
|
| mag_kBulge |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter)
magnitude (Vega) of bulge
|
| sdss_uBulge |
float |
|
|
Absolute rest frame SDSS u magnitude (AB) of bulge |
| sdss_gBulge |
float |
|
|
Absolute rest frame SDSS g magnitude (AB) of bulge |
| sdss_rBulge |
float |
|
|
Absolute rest frame SDSS r magnitude (AB) of bulge |
| sdss_iBulge |
float |
|
|
Absolute rest frame SDSS i magnitude (AB) of bulge |
| sdss_zBulge |
float |
|
|
Absolute rest frame SDSS z magnitude (AB) of bulge |
| mag_bDust |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude
(Vega), dust extinction included
|
| mag_vDust |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude
(Vega), dust extinction included
|
| mag_rDust |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter)
magnitude (Vega), dust extinction included
|
| mag_iDust |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter)
magnitude (Vega), dust extinction included
|
| mag_kDust |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter)
magnitude (Vega), dust extinction included
|
| sdss_uDust |
float |
|
|
Absolute rest frame SDSS u magnitude (AB), dust extinction included |
| sdss_gDust |
float |
|
|
Absolute rest frame SDSS g magnitude (AB), dust extinction included |
| sdss_rDust |
float |
|
|
Absolute rest frame SDSS r magnitude (AB), dust extinction included |
| sdss_iDust |
float |
|
|
Absolute rest frame SDSS i magnitude (AB), dust extinction included |
| sdss_zDust |
float |
|
|
Absolute rest frame SDSS z magnitude (AB), dust extinction included |
| massWeightedAge |
float |
|
109 yr |
The age of this galaxy, weighted by mass of their
components. |
| ShellRadius |
float |
phys.size |
Mpc/h
|
Radius of galactic wind.
|
| ShellMass |
float |
phys.mass |
1010/h Msun |
Mass in wind outer shell. See Section 2.2 of
Bertone, De Lucia and Thomas 2007. |
| ShellMetals |
float |
phys.mass |
1010/h Msun |
Mass in metals in wind outer shell.
See Section 2.2 of Bertone, De Lucia and Thomas 2007. |
| WindMass |
float |
phys.mass |
1010/h Msun |
Mass in wind bubble, or cavity.
See Section 2.2 of Bertone, De Lucia and Thomas 2007. |
| WindMetals |
float |
phys.mass |
1010/h Msun |
Mass in metals in wind bubble, or cavity.
See Section 2.2 of Bertone, De Lucia and Thomas 2007.
|
| WindEnergy |
float |
phys.energy |
1010/h Msun km/s |
Wind energy in a pressure-driven wind.
|
| BubbleEnergy |
float |
phys.energy |
1010/h Msun km/s |
Bubble energy in a pressure-driven wind (eq. 1 in
Bertone, De Lucia and Thomas 2007).
|
| BubbleTemp |
float |
phys.temperature |
Kelvin |
Bubble temperature of a pressure-driven wind.
|
| BubbleAge |
float |
phys.time |
s |
Age of a pressure-driven wind.
|
| ShockVelocity |
float |
phys.velocity |
km/s |
Wind speed at shock radius.
|
| MassInIGM |
float |
phys.mass |
1010/h Msun |
Mass deposited in IGM.
|
| MetalsMassInIGM |
float |
phys.mass |
1010/h Msun |
Mass in metals deposited in IGM.
|
| Bubble |
int
|
index
|
|
Index for wind:
Bubble=0 no wind present
Bubble=1 pressure -driven wind
Bubble=2 momentum-driven wind
|
| random |
integer |
|
|
Random number between 0 and 1000000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.7 : DGalaxies
| (top) (separate page) |
|
This database contains galaxy catalogues created in Durham.
|
3.3.7.1 : Bower2006a
| (top) (separate page) |
|
This table contains the semi-analytic galaxy catalogues of Bower
et al (2006). All magnitudes include dust extinction and assume
that H0 = 100km/sec/Mpc.
| column | type | UCD | unit | description |
|---|
| GalaxyID |
long |
meta.id;meta.main |
|
Id of galaxy, unique within simulation and semi-analytic run |
| DescendantId |
long |
meta.id.assoc |
|
pointer to the descendant of this galaxy in the merger tree
|
| LastProgenitorId |
long |
meta.id.assoc |
|
All galaxies with IDs between the ID of this galaxy and LastProgenitorId are the merger tree rooted at this galaxy.
|
| Redshift |
float |
time |
|
redshift of the snapshot where this galaxy resides
|
| SnapNum |
int |
time |
|
The snapshot number where this galaxy exists.
|
| FirstProgenitorID |
long |
meta.id.assoc |
|
The ID of the most massive progenitor of the galaxy
|
| EndMainBranchID |
long |
meta.id.assoc |
|
The ID of the galaxy at the end of the main progenitor branch of this galaxy.
|
| phKey |
integer |
|
|
Peano-Hilbert key, (bits=8), for position in 500/h Mpc
box. See the text on spatial indexes.
|
| zIndex |
integer |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this galaxy's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 50 bins. See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.y |
|
Zone index along y-direction, based on 50 bins. See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.y |
|
Zone index along z-direction, based on 50 bins. See the text on spatial indexes.
|
| random |
float |
|
|
A random number between 0 and 1000000. See the section on
random sampling.
|
| mag_U |
float |
em.opt.U |
|
Absolute rest frame U band magnitude (Vega) of galaxy.
|
| mag_B |
float |
em.opt.B |
|
Absolute rest frame B band magnitude (Vega) of galaxy.
|
| mag_V |
float |
em.opt.V |
|
Absolute rest frame V band magnitude (Vega) of galaxy.
|
| mag_R |
float |
em.opt.R |
|
Absolute rest frame R band magnitude (Vega) of galaxy.
|
| mag_I |
float |
em.opt.I |
|
Absolute rest frame I band magnitude (Vega) of galaxy.
|
| mag_J |
float |
em.opt.J |
|
Absolute rest frame J band magnitude (Vega) of galaxy.
|
| mag_K |
float |
em.opt.K |
|
Absolute rest frame K band magnitude (Vega) of galaxy.
|
| mag_H |
float |
em.opt.H |
|
Absolute rest frame H band magnitude (Vega) of galaxy.
|
| mag_U_Obs |
float |
em.opt.U |
|
Absolute observer frame U band magnitude (Vega) of galaxy.
|
| mag_B_Obs |
float |
em.opt.B |
|
Absolute observer frame B band magnitude (Vega) of galaxy.
|
| mag_V_Obs |
float |
em.opt.V |
|
Absolute observer frame V band magnitude (Vega) of galaxy.
|
| mag_R_Obs |
float |
em.opt.R |
|
Absolute observer frame R band magnitude (Vega) of galaxy.
|
| mag_I_Obs |
float |
em.opt.I |
|
Absolute observer frame I band magnitude (Vega) of galaxy.
|
| mag_J_Obs |
float |
em.opt.J |
|
Absolute observer frame J band magnitude (Vega) of galaxy.
|
| mag_K_Obs |
float |
em.opt.K |
|
Absolute observer frame K band magnitude (Vega) of galaxy.
|
| mag_H_Obs |
float |
em.opt.H |
|
Absolute observer frame H band magnitude (Vega) of galaxy.
|
| mag_UBulge |
float |
em.opt.U |
|
Absolute rest frame U band magnitude (Vega) of galactic bulge.
|
| mag_BBulge |
float |
em.opt.B |
|
Absolute rest frame B band magnitude (Vega) of galactic bulge.
|
| mag_VBulge |
float |
em.opt.V |
|
Absolute rest frame V band magnitude (Vega) of galactic bulge.
|
| mag_RBulge |
float |
em.opt.R |
|
Absolute rest frame R band magnitude (Vega) of galactic bulge.
|
| mag_IBulge |
float |
em.opt.I |
|
Absolute rest frame I band magnitude (Vega) of galactic bulge.
|
| mag_JBulge |
float |
em.opt.J |
|
Absolute rest frame J band magnitude (Vega) of galactic bulge.
|
| mag_KBulge |
float |
em.opt.K |
|
Absolute rest frame K band magnitude (Vega) of galactic bulge.
|
| mag_HBulge |
float |
em.opt.H |
|
Absolute rest frame H band magnitude (Vega) of galactic bulge.
|
| mag_UBulge_Obs |
float |
em.opt.U |
|
Absolute observer frame U band magnitude (Vega) of galactic bulge.
|
| mag_BBulge_Obs |
float |
em.opt.B |
|
Absolute observer frame B band magnitude (Vega) of galactic bulge.
|
| mag_VBulge_Obs |
float |
em.opt.V |
|
Absolute observer frame V band magnitude (Vega) of galactic bulge.
|
| mag_RBulge_Obs |
float |
em.opt.R |
|
Absolute observer frame R band magnitude (Vega) of galactic bulge.
|
| mag_IBulge_Obs |
float |
em.opt.I |
|
Absolute observer frame I band magnitude (Vega) of galactic bulge.
|
| mag_JBulge_Obs |
float |
em.opt.J |
|
Absolute observer frame J band magnitude (Vega) of galactic bulge.
|
| mag_KBulge_Obs |
float |
em.opt.K |
|
Absolute observer frame K band magnitude (Vega) of galactic bulge.
|
| mag_HBulge_Obs |
float |
em.opt.H |
|
Absolute observer frame H band magnitude (Vega) of galactic bulge.
|
| u_SDSS |
float |
em.opt.u |
|
Absolute rest frame SDSS u band magnitude (Vega) of the galaxy.
|
| g_SDSS |
float |
em.opt.g |
|
Absolute rest frame SDSS g band magnitude (Vega) of the galaxy.
|
| r_SDSS |
float |
em.opt.r |
|
Absolute rest frame SDSS r band magnitude (Vega) of the galaxy.
|
| i_SDSS |
float |
em.opt.i |
|
Absolute rest frame SDSS i band magnitude (Vega) of the galaxy.
|
| z_SDSS |
float |
em.opt.z |
|
Absolute rest frame SDSS z band magnitude (Vega) of the galaxy.
|
| u_SDSS_Obs |
float |
em.opt.u |
|
Absolute observer frame SDSS u band magnitude (Vega) of the galaxy.
|
| g_SDSS_Obs |
float |
em.opt.g |
|
Absolute observer frame SDSS g band magnitude (Vega) of the galaxy.
|
| r_SDSS_Obs |
float |
em.opt.r |
|
Absolute observer frame SDSS r band magnitude (Vega) of the galaxy.
|
| i_SDSS_Obs |
float |
em.opt.i |
|
Absolute observer frame SDSS i band magnitude (Vega) of the galaxy.
|
| z_SDSS_Obs |
float |
em.opt.z |
|
Absolute observer frame SDSS z band magnitude (Vega) of the galaxy.
|
| u_SDSSBulge |
float |
em.opt.u |
|
Absolute rest frame SDSS u band magnitude (Vega) of the galactic bulge.
|
| g_SDSSBulge |
float |
em.opt.g |
|
Absolute rest frame SDSS g band magnitude (Vega) of the galactic bulge.
|
| r_SDSSBulge |
float |
em.opt.r |
|
Absolute rest frame SDSS r band magnitude (Vega) of the galactic bulge.
|
| i_SDSSBulge |
float |
em.opt.i |
|
Absolute rest frame SDSS i band magnitude (Vega) of the galactic bulge.
|
| z_SDSSBulge |
float |
em.opt.z |
|
Absolute rest frame SDSS z band magnitude (Vega) of the galactic bulge.
|
| u_SDSSBulge_Obs |
float |
em.opt.u |
|
Absolute observer frame SDSS u band magnitude (Vega) of the galactic bulge.
|
| g_SDSSBulge_Obs |
float |
em.opt.g |
|
Absolute observer frame SDSS g band magnitude (Vega) of the galactic bulge.
|
| r_SDSSBulge_Obs |
float |
em.opt.r |
|
Absolute observer frame SDSS r band magnitude (Vega) of the galactic bulge.
|
| i_SDSSBulge_Obs |
float |
em.opt.i |
|
Absolute observer frame SDSS i band magnitude (Vega) of the galactic bulge.
|
| z_SDSSBulge_Obs |
float |
em.opt.z |
|
Absolute observer frame SDSS z band magnitude (Vega) of the galactic bulge.
|
| L_Halpha |
float |
|
10^40 h^-2 erg/s |
Total luminosity in the Halpha emission line
|
| LBulge_Halpha |
float |
|
10^40 h^-2 erg/s |
Bulge luminosity in the Halpha emission line
|
| L_OII3727 |
float |
|
10^40 h^-2 erg/s |
Total luminosity in the OII3727 emission line
|
| LBulge_OII3727 |
float |
|
10^40 h^-2 erg/s |
Bulge luminosity in the OII3727 emission line
|
| L_Hbeta |
float |
|
10^40 h^-2 erg/s |
Total luminosity in the Hbeta emission line
|
| LBulge_Hbeta |
float |
|
10^40 h^-2 erg/s |
Bulge luminosity in the Hbeta emission line
|
| rDisk |
float |
phys.size.radius |
1/h Mpc |
Half mass radius of the disk
|
| rBulge |
float |
phys.size.radius |
1/h Mpc |
Half mass radius of the bulge
|
| vDisk |
float |
phys.veloc |
km/s |
Circular velocity of the disk at the half mass radius
|
| vBulge |
float |
phys.veloc |
km/s |
Circular velocity of the bulge at the half mass radius
|
| x |
float |
pos.cartesian.x |
1/h Mpc |
x-component position
|
| y |
float |
pos.cartesian.y |
1/h Mpc |
y-component position
|
| z |
float |
pos.cartesian.z |
1/h Mpc |
z-component position
|
| velx |
float |
phys.veloc |
km/s |
x-component of peculiar velocity
|
| vely |
float |
phys.veloc |
km/s |
y-component of peculiar velocity
|
| velz |
float |
phys.veloc |
km/s |
z-component of peculiar velocity
|
| StellarMass |
float |
phys.mass |
1/h Msun |
The total stellar mass of the galaxy |
| bulgeMass |
float |
phys.mass |
1/h Msun |
The total stellar mass of the galactic bulge |
| coldGas |
float |
phys.mass |
1/h Msun |
mass of cold gas in this galaxy |
| blackHoleMass |
float |
phys.mass |
1/h Msun |
mass of the central black hole in this galaxy |
| ageVdisk |
float |
|
Gyr |
V band luminosity weighted age of the disk |
| ageVbulge |
float |
|
Gyr |
V band luminosity weighted age of the bulge |
| ageV |
float |
|
Gyr |
V band luminosity weighted age of the galaxy |
| metVdisk |
float |
|
Dimensionless mass fraction |
V band luminosity weighted metallicity of the disk |
| metVbulge |
float |
|
Dimensionless mass fraction |
V band luminosity weighted metallicity of the bulge |
| metV |
float |
|
Dimensionless mass fraction |
V band luminosity weighted metallicity of the galaxy |
| mhalo |
float |
phys.mass |
1/h Msun |
mass of the host halo of this galaxy |
| type |
int |
src.class |
|
0 indicates central galaxy of the DHalo, 1 indicates a
satellite galaxy
|
| DHaloID |
long |
meta.id.assoc |
|
The ID of the DHalo this galaxy belongs to.
|
|
3.3.8 : DHaloTrees
| (top) (separate page) |
|
This database contains the halo and subhalo catalogues used in the Durham model for galaxy fomation.
|
3.3.8.1 : DHalo
| (top) (separate page) |
|
This table contains the catalogue of halos used to construct the
merger trees used in the Bower et al (2006) galaxy formation
model. Each DHalo is a collection of SubFind subhalos grouped together to
make a halo. Note that the objects referred to as subhalos here
(SubFind groups) are equivalent to the objects listed in the MHalo table.
| column | type | UCD | unit | description |
|---|
| DHaloID |
long |
meta.id;meta.main |
|
The ID of this DHalo, unique within the full simulation.
|
| DescendantId |
long |
meta.id.assoc |
|
The ID of the descendant of this DHalo in the merger tree.
|
| LastProgenitorId |
long |
meta.id.assoc |
|
Indicator of the last progenitor in the DHalo merger tree
rooted in this DHalo.
All DHalos with id between ID
and LastProgenitorId form the merger tree rooted in this
DHalo. |
| TreeId |
long |
meta.id.parent |
|
The unique id of the DHalo merger tree to which this DHalo belongs.
|
| FirstSubhaloID |
long |
meta.id.assoc |
|
The unique id of the most massive subhalo in this DHalo
|
| np |
int |
meta.number |
|
Number of simulation particles in this DHalo. This is
equal to the total number of particles in the constituent
subhalos of the DHalo.
|
| NSubhalos |
int |
meta.number |
|
Number of subhalos in this DHalo.
|
| SnapNum |
int |
time |
|
The snapshot number where this DHalo was identified.
|
| Redshift |
float |
time |
|
The redshift of the snapshot to which this DHalo belongs.
|
| FirstProgenitorID |
long |
meta.id.assoc |
|
The ID of the most massive progenitor of the DHalo
|
| EndMainBranchID |
long |
meta.id.assoc |
|
The ID of the halo at the end of the main progenitor branch of this halo.
|
| phKey |
integer |
|
|
Peano-Hilbert key, (bits=8), for position in 500/h Mpc
box. See the text on spatial indexes.
|
| zIndex |
integer |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this halo's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 50 bins. See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.y |
|
Zone index along y-direction, based on 50 bins. See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.y |
|
Zone index along z-direction, based on 50 bins. See the text on spatial indexes.
|
| random |
float |
|
|
A random number between 0 and 1000000. See the section on
random sampling.
|
|
3.3.8.2 : DSubHalo
| (top) (separate page) |
|
The DSubhalo table specifies the parent DHalo for each
subhalo. It may be used to determine which subhalos belong to
each DHalo. The SubhaloID column corresponds to the subHaloID
column in the MFiels..FOFSubhalo table, and to the subhaloId column in the MPAHalotrees..MHalo table.
So additional information about a subhalo may be obtained by joining to these tables.
| column | type | UCD | unit | description |
|---|
| DHaloID |
long |
meta.id |
|
The ID of the DHalo in the DHaloTrees..DHalo table to which this subhalo belongs
|
| SubhaloID |
long |
meta.id |
|
The unique ID of a subhalo in the MField..FOFSubhalo table.
|
|
3.3.9 : MPAMocks
| (top) (separate page) |
|
This database contains mock galaxy catalogues created by "virtual observations" of the semi-analytical galaxy
catalogues in the various other databases. These (will) range from small pencilbeams to slices to full mock-SDSS
catalogues. The different algorithms used are documented in the links above.
|
3.3.9.1 : Kitzbichler2006abcdef
| (top) (separate page) |
|
This dataset contains six pencil beam mock catalogues of a deep field of 1.4 times 1.4 square degrees.
These catalogues were created from the galaxy catalogue in
MPAGalaxies.DeLucia2006a.
For a description of the "virtual observation" algorithm see
Kitzbichler M. & White S. D. M. 2007.
If you use the data from this dataset, please cite this paper, as well as the relevant papers mentioned in
the general credits page,
Springel V. et al. 2005 Nature 435, 629 and De Lucia G. & Blaizot J. 2006 astro-ph/0606519.
The data set is distributed over two times 6 tables. Containing Johnson magnitudes plus some physical information
and SDSS magnitudes respectively. There are furthermore 6 views defined that merge the observational properties of these
tables together. The following are some example queries:
select floor(redshift_obs/.1)*.1 as z,count(*) as n
from mpamocks..kitzbichler2006a_johnson
where k_j < 22
group by floor(redshift_obs/.1)*.1
order by z
and
select floor(b_j/.1)*.1 as mag_B,count(*) as n
from mpamocks..kitzbichler2006a_johnson
group by floor(b_j/.1)*.1
order by mag_B
|
3.3.9.1.1 : Kitzbichler2006abcdef_Johnson
| (top) (separate page) |
|
The tables named Kitzbichler2006a_Johnson - Kitzbichler2006f_Johnson contain positional information,
some physical properties and various Johnson magniudes for the
Kitzbichler and White (2006) datasets.
All have the following schema:
| name | datatype | unit | UCD | description |
|---|
| objectID | long | | | Unique ID which encodes the cone directions and observer position plus a sequential number within each cone.
|
| galaxyID | long | | | ID which allows to join light-cone table to galaxy table DeLucia2006a.
|
| haloID | long | | | ID which allows to join light-cone table to the MPAhalo table
|
| ra | float | degree | | right ascension
|
| dec | float | degree | | declination
|
| redshift_obs | float | | | apparent redshift
|
| redshift_cosm | float | | | cosmological redshift
|
| dist | float | Mpc/h comoving | | comoving distance
|
| cos_inc | float | | | cosine of inclination angle
|
| SFR | float | M_solar/year | | star formation rate averaged over one snapshot time
|
| M_stellar | float | 1010 M_solar/h | | stellar mass
|
| M_B_stellar | float | 1010 M_solar/h | | stellar mass in the bulge
|
| M_Z_stellar | float | 1010 M_solar/h | | stellar mass in metals
|
| B_J_nodust | float | | | Observer frame apparent (AB) magnitude in Johnson B filter (no dust)
|
| V_J_nodust | float | | | Observer frame apparent (AB) magnitude in Johnson V filter (no dust)
|
| R_J_nodust | float | | | Observer frame apparent (AB) magnitude in Johnson R filter (no dust)
|
| I_J_nodust | float | | | Observer frame apparent (AB) magnitude in Johnson I filter (no dust)
|
| K_J_nodust | float | | | Observer frame apparent (AB) magnitude in Johnson K filter (no dust)
|
| B_J | float | | | Observer frame apparent (AB) magnitude in Johnson B filter (with dust)
|
| V_J | float | | | Observer frame apparent (AB) magnitude in Johnson V filter (with dust)
|
| R_J | float | | | Observer frame apparent (AB) magnitude in Johnson R filter (with dust)
|
| I_J | float | | | Observer frame apparent (AB) magnitude in Johnson I filter (with dust)
|
| K_J | float | | | Observer frame apparent (AB) magnitude in Johnson K filter (with dust)
|
| B_RF_J_nodust | float | | | Rest-frame absolute (AB) magnitude in Johnson B filter (no dust)
|
| V_RF_J_nodust | float | | | Rest-frame absolute (AB) magnitude in Johnson V filter (no dust)
|
| R_RF_J_nodust | float | | | Rest-frame absolute (AB) magnitude in Johnson R filter (no dust)
|
| I_RF_J_nodust | float | | | Rest-frame absolute (AB) magnitude in Johnson I filter (no dust)
|
| K_RF_J_nodust | float | | | Rest-frame absolute (AB) magnitude in Johnson K filter (no dust)
|
| B_RF_J | float | | | Rest-frame absolute (AB) magnitude in Johnson B filter (with dust)
|
| V_RF_J | float | | | Rest-frame absolute (AB) magnitude in Johnson V filter (with dust)
|
| R_RF_J | float | | | Rest-frame absolute (AB) magnitude in Johnson R filter (with dust)
|
| I_RF_J | float | | | Rest-frame absolute (AB) magnitude in Johnson I filter (with dust)
|
| K_RF_J | float | | | Rest-frame absolute (AB) magnitude in Johnson K filter (with dust)
|
| type | float | | | The type of this galaxy as defined in the
Delucia2006a table.
|
| redshift | float | | | The redshift corresponding to the output snapshot of this galaxy
in the Delucia2006a table.
|
|
3.3.9.1.2 : Kitzbichler2006abcdef_SDSS
| (top) (separate page) |
|
The tables named Kitzbichler2006a_SDSS - Kitzbichler2006f_SDSS contain SDSS magniudes for the
Kitzbichler and White (2006) datasets.
These tables complement the corresponding
tables with Johnson magnitudes (Kitzbichler2006a_Johnson - Kitzbichler2006f_Johnson) in this same database.
They are linked to these by the common objectId column.
All have the following schema:
| name | datatype | unit | UCD | description |
|---|
| objectID | long | | | Unique ID which encodes the cone directions and observer
position plus a sequential number within each cone. Links this table to the corresponding Kitzbichler2006?_Johnson table.
|
| g_SDSS_nodust | float | | | Observer frame apparent (AB) magnitude in SDSS g filter (no dust)
|
| r_SDSS_nodust | float | | | Observer frame apparent (AB) magnitude in SDSS r filter (no dust)
|
| i_SDSS_nodust | float | | | Observer frame apparent (AB) magnitude in SDSS i filter (no dust)
|
| z_SDSS_nodust | float | | | Observer frame apparent (AB) magnitude in SDSS z filter (no dust)
|
| g_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS g filter (with dust)
|
| r_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS r filter (with dust)
|
| i_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS i filter (with dust)
|
| z_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS z filter (with dust)
|
| g_RF_SDSS_nodust | float | | | Rest-frame absolute (AB) magnitude in SDSS g filter (no dust)
|
| r_RF_SDSS_nodust | float | | | Rest-frame absolute (AB) magnitude in SDSS r filter (no dust)
|
| i_RF_SDSS_nodust | float | | | Rest-frame absolute (AB) magnitude in SDSS i filter (no dust)
|
| z_RF_SDSS_nodust | float | | | Rest-frame absolute (AB) magnitude in SDSS z filter (no dust)
|
| g_RF_SDSS | float | | | Rest-frame absolute (AB) magnitude in SDSS g filter (with dust)
|
| r_RF_SDSS | float | | | Rest-frame absolute (AB) magnitude in SDSS r filter (with dust)
|
| i_RF_SDSS | float | | | Rest-frame absolute (AB) magnitude in SDSS i filter (with dust)
|
| z_RF_SDSS | float | | | Rest-frame absolute (AB) magnitude in SDSS z filter (with dust)
|
|
3.3.9.1.3 : Kitzbichler2006abcdef_Obs
| (top) (separate page) |
|
These six views named Kitzbichler2006a_Obs - Kitzbichler2006f_Obs
combine the observables from the
Kitzbichler & White (2006)
Johnson
and
SDSS tables.
The sql creating these views was
create view Kitzbichler2006a_Obs as
select j.objectId, j.galaxyId, j.ra,j.dec, j.redshift_obs,j.cos_inc
, j.M_B_stellar/j.M_stellar as bulge2total
, j.B_J,j.V_J,j.R_J,j.I_J,j.K_J,s.g_SDSS,s.r_SDSS,s.i_SDSS,s.z_SDSS
from MPAMocks..Kitzbichler2006a_Johnson j
, MPAMocks..Kitzbichler2006a_SDSS s
where j.objectId = s.objectId
and similar for the other views.
All have the following schema:
| name | datatype | unit | UCD | description |
|---|
| objectID | long | | | Unique ID which encodes the cone directions and observer position plus a sequential number within each cone.
|
| galaxyID | long | | | ID which allows to join light-cone table to galaxy table DeLucia2006a.
|
| ra | float | degree | | right ascension
|
| dec | float | degree | | declination
|
| redshift_obs | float | | | apparent redshift
|
| cos_inc | float | | | cosine of inclination angle
|
| bulge2tot | float | | | bulge/total stellar mass ratio
|
| B_J | float | | | Observer frame apparent (AB) magnitude in Johnson B filter (with dust)
|
| V_J | float | | | Observer frame apparent (AB) magnitude in Johnson V filter (with dust)
|
| R_J | float | | | Observer frame apparent (AB) magnitude in Johnson R filter (with dust)
|
| I_J | float | | | Observer frame apparent (AB) magnitude in Johnson I filter (with dust)
|
| K_J | float | | | Observer frame apparent (AB) magnitude in Johnson K filter (with dust)
|
| g_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS g filter (with dust)
|
| r_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS r filter (with dust)
|
| i_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS i filter (with dust)
|
| z_SDSS | float | | | Observer frame apparent (AB) magnitude in SDSS z filter (with dust)
|
|
3.3.9.2 : Blaizot2006_AllSky
| (top) (separate page) |
|
This dataset contains 6 all-sky mock catalogues (tables Blaizot_AllSky_RT_x, with x = 1-5 and Blaizot_AllSky_PT_1).
They are all limited at an apparent AB magnitude of 18 in the r filter from SDSS, in an attempt to
reproduce (with some margin) the SDSS spectroscopic selection. The catalogues include apparent magnitudes
in the 8 filters from both SDSS and 2MASS (namely u,g,r,i,z,J,H, and K).
These light-cones were made using the MoMaF code (see Blaizot et al.
2005, MNRAS 360, 159) and the semi-analytic model presented in De Lucia & Blaizot 2006 (astro-ph/0606519),
the results of which are stored in the MPAGalaxies..DeLucia2006a table.
Light-cones 'Blaizot_AllSky_RT_1' to 'Blaizot_AllSky_RT_5' use the random tiling technique described in Blaizot et al. (2005),
and each of these mock catalogues was generated with a different seed for the random number generator.
In practice, the main effect of this here is that the "observer" sits in different parts of the
simulation volume for each light-cone, thus allowing estimates of cosmic variance in the very local universe.
The light-cone 'Blaizot_AllSky_PT_1' preserves the periodicity of the density field (i.e. it does not use *random* tiling).
The price to pay is that replications do introduce spatial correlations on very large scales.
The gain is that the density field is indeed almost continuous across the whole light-cone volume.
The tables contain not only the "observable" information for the mock catalogues, but also all the attributes(columns)
of the underlying galaxy obtained from DeLucia2006a. This information could in principle be obtained using a join on
the galaxyId column, however for large subsets this can easily cause a degradation in query speed to beyond the
current timeout limits. Hence we have added this information for you already.
Credits : on top of the normal credits for using the Millennium database
(see here),
please also refer to the MoMaF paper (Blaizot et al. 2005, MNRAS 360,
159) if you use these mock catalogues for publication.
Example queries :
redshift distribution
select floor(cosmo_redshift*500)/500 as z
, count(*) as n
from mpamocks..blaizot2006_allsky_rt_1
group by floor(cosmo_redshift*500)/500
order by z
mass distribution of a random subsample
select floor(log10(stellarmass)*10)/10 as lmstar
, count(*) as n
from mpamocks..Blaizot2006_AllSky_RT_1
group by floor(log10(stellarmass)*10)/10
order by lmstar
All the tables in this set have the following structure:
| name | datatype | unit | UCD | description |
|---|
| ObjID | long | | | Unique ID of a galaxy in the light-cone.
|
| xpos | float | Mpc/h comoving | | cartesian coordinate x (along the central line of sight)
|
| ypos | float | Mpc/h comoving | | cartesian coordinate y (perpendicular to the central line of sight)
|
| zpos | float | Mpc/h comoving | | cartesian coordinate z (perpendicular to the central line of sight)
|
| ra | float | degree | | right ascension
|
| dec | float | degree | | declination
|
| app_redshift | float | | | apparent redshift
|
| cosmo_redshift | float | | | cosmological redshift
|
| vlos | float | km/s | | line-of-sight velocity
|
| SDSS_u | float | | | apparent (AB) magnitude in filter SDSS_u
|
| SDSS_g | float | | | apparent (AB) magnitude in filter SDSS_g
|
| SDSS_r | float | | | apparent (AB) magnitude in filter SDSS_r
|
| SDSS_i | float | | | apparent (AB) magnitude in filter SDSS_i
|
| SDSS_z | float | | | apparent (AB) magnitude in filter SDSS_z
|
| TWOMASS_H | float | | | apparent (AB) magnitude in filter 2MASS_H
|
| TWOMASS_J | float | | | apparent (AB) magnitude in filter 2MASS_J
|
| TWOMASS_K | float | | | apparent (AB) magnitude in filter 2MASS_K
|
| cx | double | null | pos.cart.x | |
| cy | double | null | pos.cart.y | |
| cz | double | null | pos.cart.z | |
| htmId | long | null | null | |
| galaxyID |
long |
meta.id;meta.main |
|
ID of galaxy, unique within simulation and SAM run. |
| lastProgenitorId |
long |
meta.id.assoc |
|
All galaxies with id between this galaxyId and this lastProgenitorId together are the merger tree rooted in this galaxy.
|
| descendantId |
long |
meta.id.assoc |
|
Pointer to the descendant of this galaxy in its merger tree; -1 if there is no descendant
|
| haloID |
long |
meta.id.parent |
|
Unique ID of MPA halo containing this galaxy
|
| subHaloID |
long |
meta.id; |
|
The ID of the sub-halo this galaxy resides in. Identical to the subhaloId of the halo identified by the haloId. |
| fofID |
long |
meta.id; |
|
The id of the sub-halo at the center of the friends-of-friends (FOF) this galaxy resides in.
|
| treeId |
long |
meta.id.parent |
|
unique id of galaxy formation tree containing this galaxy
|
| firstProgenitorId |
long |
meta.id.assoc |
|
Main progenitor of this galaxy. Also the first progenitor in a linked list representation of the merger tree. |
| nextProgenitorId |
long |
meta.id.assoc |
|
Next progenitor of this galaxy in linked list representation of merger tree
|
| type |
int |
src.class |
|
0,1 or 2 indicating whether this galaxy is a central galaxy of its FOF group, central galaxy of a subhalo, or a satellite galaxy. |
| snapnum |
int |
time |
|
The snapshot number where this galaxy was identified.
This column corresponds to the snapnum column in
the Snapshots table in MField.
|
| redshift |
float |
time |
|
redshift of the snapshot where this galaxy resides
|
| centralMvir |
float |
phys.veloc.dispersion |
1010/h Msun |
virial mass of background (FOF) halo containing this galaxy
|
| phkey |
int |
|
|
Peano-Hilbert key, (bits=8), for position in 500/h Mpc box
See the text on spatial indexes.
|
| x |
float |
pos.cartesian.x |
1/h Mpc |
x-component position
|
| y |
float |
pos.cartesian.y |
1/h) Mpc |
y-component position
|
| z |
float |
pos.cartesian.z |
1/h Mpc |
z-component position
|
| zIndex |
long |
|
|
The "bit-interleaved" or "Z-curve" index, corresponding to this galaxy's position. Same resolution as phKey.
See the text on spatial indexes.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 50 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 50 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 50 bins
See the text on spatial indexes.
|
| velX |
float |
phys.veloc |
km/s |
x-component velocity
|
| velY |
float |
phys.veloc |
km/s |
y-component velocity
|
| velZ |
float |
phys.veloc |
km/s |
z-component velocity
|
| np |
int |
meta.number |
|
Number of particles in halo the galaxy belongs to.
|
| mvir |
float |
phys.mass |
1010/h Msun |
Virial mass of the subhalo the galaxy is/was the center of.
|
| rvir |
float |
phys.size.radius |
Mpc/h |
Virial radius of the subhalo the galaxy is/was the center of.
|
| vvir |
float |
phys.veloc |
km/s |
Virial velocity of the subhalo the galaxy is/was the center of.
|
| vmax |
float |
phys.veloc.rotat |
km/s |
Maximum rotational velocity of the subhalo of which this galaxy is the center, or the last value for satellite galaxies.
|
| coldGas |
float |
phys.mass |
1010/h Msun |
Mass in cold gas.
|
| stellarMass |
float |
phys.mass |
1010/h Msun |
Mass in stars.
|
| bulgeMass |
float |
phys.mass |
1010/h Msun |
Mass of bulge.
|
| hotGas |
float |
phys.mass |
1010/h Msun |
Mass in hot gas component of this galaxy's subhalo. TBD on type 2 galaxies.
|
| ejectedMass |
float |
phys.mass |
1010/h Msun/h |
The ejected mass component (see de Lucia et al., 2004, MNRAS, Volume 349, 1101-1116).
|
| blackHoleMass |
float |
phys.mass |
1010/h Msun |
Mass of central black hole
|
| metalsColdGas |
float |
phys.mass |
1010/h Msun |
Mass in metals in cold gas.
|
| metalsStellarMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in stars.
|
| metalsBulgeMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in bulge.
|
| metalsHotGas |
float |
phys.mass |
1010/h Msun |
ratio of mass in metals.
|
| metalsEjectedMass |
float |
phys.mass |
1010/h Msun |
Mass in metals in ejected gas.
|
| sfr |
float |
phys.SFR |
Msun/yr |
Star formation rate
|
| sfrBulge |
float |
phys.SFR |
Msun/yr |
Star formation rate in the bulge.
|
| xrayLum |
float |
em.X-Ray |
TBD |
X-Ray luminosity
|
| diskRadius |
float |
phys.size.radius |
Mpc/h |
Disk radius, derived form halo radius ala
Mo, Mao and White (1997) |
| coolingRadius |
float |
phys.size.radius |
Mpc/h |
The radius within which the cooling time scale is shorter than the dynamical timescale
|
| mag_b |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega) of galaxy.
|
| mag_v |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega) of galaxy
|
| mag_r |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega) of galaxy.
|
| mag_i |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega) of galaxy.
|
| mag_k |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega) of galaxy.
|
| mag_bBulge |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega) of bulge
|
| mag_vBulge |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega) of bulge
|
| mag_rBulge |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega) of bulge
|
| mag_iBulge |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega) of bulge
|
| mag_kBulge |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega) of bulge
|
| mag_bDust |
float |
em.opt.B |
|
Absolute rest frame B (Buser B3 filter) magnitude (Vega), dust extinction included
|
| mag_vDust |
float |
em.opt.V |
|
Absolute rest frame V (Buser V filter) magnitude (Vega), dust extinction included
|
| mag_rDust |
float |
em.opt.R |
|
Absolute rest frame R (Johnson R filter) magnitude (Vega), dust extinction included
|
| mag_iDust |
float |
em.opt.I |
|
Absolute rest frame I (Johnson I filter) magnitude (Vega), dust extinction included
|
| mag_kDust |
float |
em.opt |
|
Absolute rest frame K (Johnson K filter) magnitude (Vega), dust extinction included
|
| massWeightedAge |
float |
|
109/h yr |
The age of this galaxy, weighted by mass of their components. |
| random |
integer |
|
|
Random number between 0 and 1000000 (using java.lang.Math.random()).
See the page on random sampling.
|
|
3.3.9.3 : COSMOS Cones
| (top) (separate page) |
COSMOS pencil beam mock catalogues
This dataset contains 24 pencil beam mock catalogues of a deep field of 1.4 times 1.4 square degrees created by
Manfred Kitzbichler for the COSMOS collaboration.
These catalogues were created from a galaxy catalogue similar but not identical to the
MPAGalaxies..DeLucia2006a. galaxy catalogue.
Whereas the same parameters were used for the galaxy formation algorithm , the halo merger trees were different.
See DeLucia & Blaizot 2007 for a description of the different merger tree definitions.
For this reason no links are provided to the main galaxy catalogues.
But since these catalogues have been quite widely used we felt it of interest to publish them in the database.
Some of the papers using these catalogues are:
For a description of the virtual observation algorithm see
Kitzbichler M. & White S. D. M. (2007).
If you use the data from this dataset, please cite this paper, as well as the relevant papers mentioned in
the general credits page.
The data set is distributed over 24 tables, named COSMOS_012_000, COSMOS_012_001, ..., COSMOS_012_111
and versions with 120 and 201 iso 012. See also the menu bar on the query page.
These represent 8 different directions of the basis cone and 3 different origins.
They contain Johnson magnitudes plus some physical information.
All tables have the following form:
| name | datatype | unit | UCD | description |
|---|
| objectId | int | | | Unique identifier for this galaxy. |
| ra | real | degree | pos.eq.ra | Right Ascencion of galaxy. |
| dec | real | degree | pos.eq.dec | Declination of galaxy. |
| z_obs | real | | | Observed redshift, i.e. includes peculiar velocity redshift. |
| z | real | | | Redshift based on comoving distance only. |
| d | real | Mpc/h | | Comoving distance |
| treeId | bigint | | | ignore |
| fofgal | bigint | | | ignore |
| snapnum | int | time | | Snapshot original galaxy resided in. |
| type | int | src.class | | Type of galaxy (see corresponding column in
MPAGalaxies..DeLucia2006a) |
| mvir | real | phys.mass | 1010 Msun/h | Virial mass. |
| rvir | real | phys.size.radius | Mpc/h | Virial radius |
| vvir | real | phys.veloc.dispersion | km/s | Virial velocity |
| vmax | real | phys.veloc.rotation | km/s | Maximum rotational velocity of galaxy. |
| coldGas | real | phys.mass | 1010 Msun/h | Mass in cold gas |
| stellarMass | real | phys.mass | 1010 Msun/h | Mass in stars |
| bulgeMass | real | phys.mass | 1010 Msun/h | Mass in stars in bulge |
| hotGas | real | phys.mass | 1010 Msun/h | Mass in hot gas |
| metalsColdGas | real | phys.mass | 1010 Msun/h | Mass in metals in cold gass |
| metalsStellarMass | real | phys.mass | 1010 Msun/h | Mass in metals in stars |
| metalsBulgeMass | real | phys.mass | 1010 Msun/h | Mass in metals in stars in bulge |
| metalsHotGas | real | phys.mass | 1010 Msun/h | Mass in metals in hot gas |
| blackHoleMass | real | phys.mass | 1010 Msun/h | Mass of central black hole |
| sfr | real | phys.SFR | Msun/yr | Star formation rate |
| diskRadius | real | phys.size.radius | Mpc/h | Radius of stellar disk. |
| cosInc | real | | | Cosine of inclination of galaxy. |
| mag_b | real | phot.mag;em.opt.B | | Apparent Subaru B magnitude |
| mag_v | real | phot.mag;em.opt.V | | Apparent Johnson V magnitude |
| mag_r | real | phot.mag;em.opt.R | | Apparent Johnson R magnitude |
| mag_i | real | phot.mag;em.opt.I | | Apparent Johnson I magnitude |
| mag_k | real | phot.mag;em.opt.K | | Apparent Flamingos K magnitude |
| mag_bDust | real | phot.mag;em.opt.B | | Apparent Subaru B magnitude, dust extinction included |
| mag_vDust | real | phot.mag;em.opt.V | | Apparent Johnson V magnitude, dust extinction included |
| mag_rDust | real | phot.mag;em.opt.R | | Apparent Johnson R magnitude, dust extinction included |
| mag_iDust | real | phot.mag;em.opt.I | | Apparent Johnson I magnitude, dust extinction included |
| mag_kDust | real | phot.mag;em.opt.K | | Apparent Flamingos K magnitude, dust extinction included |
| mag_bRest | real | phot.mag;em.opt.B | | Absolute Subaru B rest magnitude |
| mag_iRest | real | phot.mag;em.opt.I | | Absolute Johnson I rest magnitude |
| mag_kRest | real | phot.mag;em.opt.K | | Absolute Flamingos K rest magnitude |
| mag_bDustRest | real | phot.mag;em.opt.B | | Absolute Subaru B rest magnitude, dust extinction included |
| mag_iDustRest | real | phot.mag;em.opt.I | | Absolute Johnson I rest magnitude, dust extinction included |
| mag_kDustRest | real | phot.mag;em.opt.K | | Absolute Flamingos K rest magnitude, dust extinction included |
|
3.3.10 : MillenniumII
| (top) (separate page) |
|
The links above lead to documentation about the tables currently available from the
Millennium-II Simulation database that has been publicly released through this web site.
|
3.3.10.1 : Snapshots
| (top) (separate page) |
This table links the expansion factor, redshift, Hubble constant, and lookback
time to the integer index of the snapshot (0-67) from the Millennium-II
Simulation. Almost all other tables in
the various Millennium-II databases have a snapnum column that corresponds to the
one in this table.
| column | type | features | description |
| snapnum | integer | NOT NULL | The order of the
snapshot, from 0 (z=127) to 67 (z=0) |
| a | real | NOT
NULL | The expansion factor at this snapshot |
| z | real | NOT
NULL | The redshift at this snapshot |
| Hz | real | NOT NULL | The Hubble constant at
this snapshot, in km/s/Mpc |
| lookBackTime | real | NOT NULL | The lookback time
at this snapshot,
in 109 years |
|
3.3.10.2 : FOF
| (top) (separate page) |
|
The table stores all the friend-of-friends (FOF) groups extracted from the raw output from the Millennium-II Simulation.
These FOF groups form the basis that the SUBFIND algorithm uses to detect the subhalos.
For further description, see Boylan-Kolchin et al. 2009.
| column | type | UCD | unit | description |
| fofId |
long |
meta.id; |
|
The id of this FOF group.
|
| snapNum |
int |
time |
|
The snapshot number where this FOF group was identified.
This column corresponds to the snapnum column in
the Snapshots table in the Millennium-II database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this FOF group belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this FOF group.
|
| mass |
float |
phys.mass |
1010 Msun/h |
The mass of the halo, calculated as np times the mass per particle.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of this FOF group's position in comoving coordinates (1).
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of this FOF group's position in comoving coordinates (1).
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of this FOF group's position in comoving coordinates (1).
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 20 bins (2)
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 20 bins (2)
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 20 bins (2)
See the text on spatial indexes.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this halo.
|
| cmx |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of this FOF group's center of mass in comoving coordinates.
|
| cmy |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of this FOF group's center of mass in comoving coordinates.
|
| cmz |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of this FOF group's center of mass in comoving coordinates.
|
| cvx |
float |
phys.veloc |
km/sec |
The X-component of the peculiar center-of-mass velocity of this FOF group.
|
| cvy |
float |
phys.veloc |
km/sec |
The Y-component of the peculiar center-of-mass velocity of this FOF group.
|
| cvz |
float |
phys.veloc |
km/sec |
The Z-component of the peculiar center-of-mass velocity of this FOF group.
|
| m_crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the critical density of the simulation.
|
| r_crit200 |
float |
phys.radius |
Mpc/h |
The radius within which the FOF group has an overdensity 200 times the critical density of the simulation.
|
| m_mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the mean density of the simulation.
|
| r_mean200 |
float |
phys.radius |
Mpc/h |
The radius within which the FOF group has an overdensity 200 times the mean density of the simulation.
|
| m_tophat |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity corresponding to the value at virialization in the
top-hat collapse model for this cosmology.
|
| r_tophat |
float |
phys.radius |
Mpc/h |
The radius within which the FOF group has an overdensity corresponding to the value at virialization in the
top-hat collapse model for this cosmology.
|
| numSubs |
integer |
|
|
Number of subhalos in this FOF halo. Note that the dominant subhalo counts as a subhalo.
|
| firstSubhaloId |
|
|
|
subhaloId of the dominant subhalo within this FOF group (-1 if numSubs=0, i.e. if there are no bound substructures in the FOF group). |
Notes:
(1) The (x, y, z) coordinates of FOF groups are determined as the minimum of the gravitational potential for the dominant subhalo.
If there is no bound subhalo associated with a FOF group, then the coordinates (x, y, z) are set to the center-of-mass coordinates (cmx, cmy, cmz)
(2) The zone index for each FOF group is based on its (x, y, z) coordinates.
|
3.3.10.3 : SubHalo
| (top) (separate page) |
|
The table stores all the subhalos identified with the SUBFIND algorithm in the friends-of-friends groups
identified within the Millennium-II Simulation
of the FOF groups themselves are stored in the
FOF table.
| column | type | UCD | unit | description |
| subHaloId |
long |
meta.id; |
|
The id of this subhalo based on its rank within its parent FOF halo.
|
| fofId |
long |
meta.id; |
|
The id of FOF group this subhalo belongs to.
|
subHaloFileId |
long |
meta.id; |
|
Alternative id of this subhalo based on its rank within the SUBFIND result file.
|
| snapNum |
int |
time |
|
The snapshot number where this subhalo was identified.
This column corresponds to the snapnum column in
the Snapshots table in the Millennium-II database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this subhalo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
| mass |
real |
|
1010 Msun/h |
Mass of this subhalo, given by the product of the number of particles and the mass per particle.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the position, determined by the particle with the minimum gravitational potential, in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the position, determined by the particle with the minimum gravitational potential, in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the position, determined by the particle with the minimum gravitational potential, in comoving coordinates.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 20 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 20 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 20 bins
See the text on spatial indexes.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this subhalo.
|
| velX |
float |
phys.veloc |
km/sec |
The X-component of the peculiar velocity.
|
| velY |
float |
phys.veloc |
km/sec |
The Y-component of the peculiar velocity.
|
| velZ |
float |
phys.veloc |
km/sec |
The Z-component of the peculiar velocity.
|
| cmx |
float |
|
Mpc/h |
The X-coordinate of the subhalo's center of mass, in comoving coordinates.
|
| cmy |
float |
|
Mpc/h |
The Y-coordinate of the subhalo's center of mass, in comoving coordinates.
|
| cmz |
float |
|
Mpc/h |
The Z-coordinate of the subhalo's center of mass, in comoving coordinates.
|
| spinX |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The X-component of the spin of the subhalo.
|
| spinY |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Y-component of the spin of the subhalo.
|
| spinZ |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Z-component of the spin of the subhalo.
|
| halfmassRadius |
float |
phys.size.radius |
Mpc/h |
Radius containing half of the mass of the subhalo.
|
| vDisp |
float |
phys.veloc.dispersion |
km/sec |
The 1-D velocity dispersion of the subhalo, computed from all of the subhalo particles.
|
| vMax |
float |
phys.veloc.rotat |
km/sec |
Maximum of the circular velocity curve vCirc, where
vCirc2=G M(< r)/r
|
| vMaxRad |
float |
|
Mpc/h |
The radius at which the circular velocity maximum vMax is attained
|
| mostBoundID |
long |
meta.id.assoc |
|
The id of the most bound particle of this subhalo.
|
|
3.3.10.4 : HaloTree
| (top) (separate page) |
|
The table stores subhalos from the Millennium-II Simulation in a representation that allows efficient querying for merger histories. For a description of how merger trees were constructed for the Millennium-II Simulation, see Boylan-Kolchin et al. 2009.
| column | type | UCD | unit | description |
| haloId |
long |
meta.id;meta.main |
|
The identifier of this subhalo in the merger tree, unique within the full simulation.
See the documentation on merger trees for further
details on the structure of merger trees in the database.
|
| subhaloId |
long |
meta.id; |
|
The identifier of this subhalo based on its rank within its parent FOF halo. This column is a foreign key ("pointer")
to the entry for this subhalo in the SubHalo table.
|
| fofId |
long |
meta.id; |
|
The id of FOF group this subhalo belongs to.
This column is a foreign key ("pointer") to the entry for this FOF group in the
FOF table.
That row will have the same value for its fofIId column. |
| treeRootId |
long |
meta.id.parent |
|
The haloId of the subhalo at the root of this merger tree. This is especially useful for improving the performance
of queries that aim to retrieve descendants of known progenitors. Note that this root halo is not necessarily at z=0,
there are some trees in the database that do not extend down to the last snapshot.
See the documentation on merger trees for further
details on querying merger trees.
|
| descendantId |
long |
meta.id.assoc |
|
The haloId of the unique descendant of this subhalo in the merger tree. -1 if there is no descendant.
This is the case for all halos at z=0, and for some halos at earlier times (see treeRootId).
|
| lastProgenitorId |
long |
meta.id.assoc |
|
The last progenitor in the subhalo merger tree rooted in this subhalo.
All subhalos with haloId between haloId and lastProgenitorId from the merger tree rooted in this subhalo. |
See the documentation on merger trees for further
details on the structure of merger trees in the database.
| mainLeafId |
long |
meta.id.assoc |
|
The last progenitor along the main branch in the subhalo merger tree for this subhalo.
All subhalos with haloId between this halo's haloId and mainLeafId make up the main progenitor branch for this subhalo.
|
| firstProgenitorId |
long |
meta.id.assoc |
|
The haloId of the main progenitor of this subhalo.
|
| nextProgenitorId |
long |
meta.id.assoc |
|
The haloId of the "next progenitor" in the subhalo merger trees (the "next progenitor" of a subhalo S is the next most massive subhalo that has the same descendant as subhalo S).
|
| firstHaloInFOFgroupId |
long |
meta.id.assoc |
|
haloId of the dominant subhalo of the friend-of-friends group to which this subhalo belongs.
|
| nextHaloInFOFgroupId |
long |
meta.id.assoc |
|
Id of the next most massive halo within the same FOF group.
|
| snapNum |
int |
time |
|
The snapshot number where this subhalo was identified.
This column corresponds to the snapnum column in
the Snapshots table in the Millennium-II database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this subhalo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
| m_crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the subhalo has an overdensity 200 times the critical density of the simulation.
Note: this value is only defined for subhalos with haloId=firstHaloInFOFgroupId. |
| m_mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the subhalo has an overdensity 200 times the mean density of the simulation.
Note: this value is only defined for subhalos with haloId=firstHaloInFOFgroupId. |
| m_tophat |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the subhalo has an overdensity corresponding to the value at virialisation in the
top-hat collapse model for this cosmology.
Note: this value is only defined for subhalos with haloId=firstHaloInFOFgroupId. |
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the subhalo's position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the subhalo's position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the subhalo's position in comoving coordinates.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 20 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 20 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 20 bins
See the text on spatial indexes.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this subhalo.
|
| velX |
float |
phys.veloc |
km/sec |
The X-component of the subhalo's peculiar velocity.
|
| velY |
float |
phys.veloc |
km/sec |
The Y-component of the subhalo's peculiar velocity.
|
| velZ |
float |
phys.veloc |
km/sec |
The Z-component of the subhalo's peculiar velocity.
|
| vDisp |
float |
phys.veloc.dispersion |
km/sec |
The 1-D velocity dispersion of the subhalo, computed from all of the subhalo particles.
|
| vMax |
float |
phys.veloc.rotat |
km/sec |
Maximum of the circular velocity curve vCirc, where
vCirc2=G M(< r)/r
|
| vMaxRad |
float |
|
Mpc/h |
The radius at which the circular velocity maximum vMax is attained
|
| spinX |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The X-component of the spin of the subhalo.
|
| spinY |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Y-component of the spin of the subhalo.
|
| spinZ |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Z-component of the spin of the subhalo.
|
| mostBoundID |
long |
meta.id.assoc |
|
The id of the most bound particle of this subhalo.
|
| fileNr |
int |
meta.file;meta.id |
|
Original file number in which the subhalo was defined.
See the documentation on identifiers for its
role in defining the haloId.
|
| subhaloIndex |
int |
meta.id.assoc |
|
Index of this subhalo in the file identified by fileNr.
|
| subhaloFileId |
long |
meta.id; |
|
This column corresponds to the subhaloFileId in the SubHalo table and gives an alternative way of identifying that halo.
This is an older way of identifying that subhalo, it is better to use the subhaloId column instead.
|
| halfmassRadius |
float |
phys.size.radius |
Mpc/h |
Radius containing half of the mass of the subhalo.
|
| random |
integer |
|
|
Random number between 0 and 1000000 using java.lang.Math.random().
See the page on random sampling.
|
| treeId |
long |
meta.id.parent |
|
The unique identifier of the L-Galaxies galaxy formation "tree" to which this subhalo belongs.
See the page on the MPA trees |
|
3.3.11 : miniMilII
| (top) (separate page) |
|
The links above lead to documentation about the tables currently available from the mini-Millennium-II
Simulation database that has been publicly released through this web site.
The mini-Millennium-II Simulation is a simulation of the same volume as the Millennium-II
Simulation using the same mass and force resolution as the Millennium Run.
For further information, see Boylan-Kolchin et al. (2009).
|
3.3.11.1 : FOF
| (top) (separate page) |
|
The table stores all the friend-of-friends (FOF) groups extracted from the raw output from the mini-Millennium-II Simulation.
These FOF groups form the basis that the SUBFIND algorithm uses to detect the subhalos.
For further description, see Boylan-Kolchin et al. 2009.
| column | type | UCD | unit | description |
| fofId |
long |
meta.id; |
|
The id of this FOF group.
|
| snapNum |
int |
time |
|
The snapshot number where this FOF group was identified.
This column corresponds to the snapnum column in
the Snapshots table in the Millennium-II database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this FOF group belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this FOF group.
|
| mass |
float |
phys.mass |
1010 Msun/h |
The mass of the halo, calculated as np times the mass per particle.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of this FOF group's position in comoving coordinates (1).
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of this FOF group's position in comoving coordinates (1).
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of this FOF group's position in comoving coordinates (1).
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 20 bins (2)
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 20 bins (2)
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 20 bins (2)
See the text on spatial indexes.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this halo.
|
| m_crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the critical density of the simulation.
|
| r_crit200 |
float |
phys.radius |
Mpc/h |
The radius within which the FOF group has an overdensity 200 times the critical density of the simulation.
|
| m_mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity 200 times the mean density of the simulation.
|
| r_mean200 |
float |
phys.radius |
Mpc/h |
The radius within which the FOF group has an overdensity 200 times the mean density of the simulation.
|
| m_tophat |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the FOF group has an overdensity corresponding to the value at virialization in the
top-hat collapse model for this cosmology.
|
| r_tophat |
float |
phys.radius |
Mpc/h |
The radius within which the FOF group has an overdensity corresponding to the value at virialization in the
top-hat collapse model for this cosmology.
|
| numSubs |
integer |
|
|
Number of subhalos in this FOF halo. Note that the dominant subhalo counts as a subhalo.
|
| firstSubhaloId |
|
|
|
subhaloId of the dominant subhalo within this FOF group (-1 if numSubs=0, i.e. if there are no bound substructures in the FOF group). |
Notes:
(1) The (x, y, z) coordinates of FOF groups are determined as the minimum of the gravitational potential for the dominant subhalo.
If there is no bound subhalo associated with a FOF group, then the coordinates (x, y, z) are set to the center-of-mass coordinates (cmx, cmy, cmz)
(2) The zone index for each FOF group is based on its (x, y, z) coordinates.
|
3.3.11.2 : SubHalo
| (top) (separate page) |
|
The table stores all the subhalos identified with the SUBFIND algorithm in the friends-of-friends groups
identified within the mini-Millennium-II Simulation
of the FOF groups themselves are stored in the
FOF table.
| column | type | UCD | unit | description |
| subHaloId |
long |
meta.id; |
|
The id of this subhalo based on its rank within its parent FOF halo.
|
| fofId |
long |
meta.id; |
|
The id of FOF group this subhalo belongs to.
|
subHaloFileId |
long |
meta.id; |
|
Alternative id of this subhalo based on its rank within the SUBFIND result file.
|
| snapNum |
int |
time |
|
The snapshot number where this subhalo was identified.
This column corresponds to the snapnum column in
the Snapshots table in the Millennium-II database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this subhalo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
| mass |
real |
|
1010 Msun/h |
Mass of this subhalo, given by the product of the number of particles and the mass per particle.
|
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the position, determined by the particle with the minimum gravitational potential, in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the position, determined by the particle with the minimum gravitational potential, in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the position, determined by the particle with the minimum gravitational potential, in comoving coordinates.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 20 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 20 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 20 bins
See the text on spatial indexes.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this subhalo.
|
| velX |
float |
phys.veloc |
km/sec |
The X-component of the peculiar velocity.
|
| velY |
float |
phys.veloc |
km/sec |
The Y-component of the peculiar velocity.
|
| velZ |
float |
phys.veloc |
km/sec |
The Z-component of the peculiar velocity.
|
| cmx |
float |
|
Mpc/h |
The X-coordinate of the subhalo's center of mass, in comoving coordinates.
|
| cmy |
float |
|
Mpc/h |
The Y-coordinate of the subhalo's center of mass, in comoving coordinates.
|
| cmz |
float |
|
Mpc/h |
The Z-coordinate of the subhalo's center of mass, in comoving coordinates.
|
| spinX |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The X-component of the spin of the subhalo.
|
| spinY |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Y-component of the spin of the subhalo.
|
| spinZ |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Z-component of the spin of the subhalo.
|
| halfmassRadius |
float |
phys.size.radius |
Mpc/h |
Radius containing half of the mass of the subhalo.
|
| vDisp |
float |
phys.veloc.dispersion |
km/sec |
The 1-D velocity dispersion of the subhalo, computed from all of the subhalo particles.
|
| vMax |
float |
phys.veloc.rotat |
km/sec |
Maximum of the circular velocity curve vCirc, where
vCirc2=G M(< r)/r
|
| vMaxRad |
float |
|
Mpc/h |
The radius at which the circular velocity maximum vMax is attained
|
| mostBoundID |
long |
meta.id.assoc |
|
The id of the most bound particle of this subhalo.
|
|
3.3.11.3 : HaloTree
| (top) (separate page) |
|
The table stores subhalos from the mini-Millennium-II Simulation in a
representation that allows efficient querying for merger histories.
For a description of how merger trees were constructed for the mini-Millennium-II Simulation,
see Boylan-Kolchin et al. 2009.
| column | type | UCD | unit | description |
| haloId |
long |
meta.id;meta.main |
|
The identifier of this subhalo in the merger tree, unique within the full simulation.
See the documentation on merger trees for further
details on the structure of merger trees in the database.
|
| subhaloId |
long |
meta.id; |
|
The identifier of this subhalo based on its rank within its parent FOF halo. This column is a foreign key ("pointer")
to the entry for this subhalo in the SubHalo table.
|
| fofId |
long |
meta.id; |
|
The id of FOF group this subhalo belongs to.
This column is a foreign key ("pointer") to the entry for this FOF group in the
FOF table.
That row will have the same value for its fofIId column. |
| treeRootId |
long |
meta.id.parent |
|
The haloId of the subhalo at the root of this merger tree. This is especially useful for improving the performance
of queries that aim to retrieve descendants of known progenitors. Note that this root halo is not necessarily at z=0,
there are some trees in the database that do not extend down to the last snapshot.
See the documentation on merger trees for further
details on querying merger trees.
|
| descendantId |
long |
meta.id.assoc |
|
The haloId of the unique descendant of this subhalo in the merger tree. -1 if there is no descendant.
This is the case for all halos at z=0, and for some halos at earlier times (see treeRootId).
|
| lastProgenitorId |
long |
meta.id.assoc |
|
The last progenitor in the subhalo merger tree rooted in this subhalo.
All subhalos with haloId between haloId and lastProgenitorId from the merger tree rooted in this subhalo. |
See the documentation on merger trees for further
details on the structure of merger trees in the database.
| mainLeafId |
long |
meta.id.assoc |
|
The last progenitor along the main branch in the subhalo merger tree for this subhalo.
All subhalos with haloId between this halo's haloId and mainLeafId make up the main progenitor branch for this subhalo.
|
| firstProgenitorId |
long |
meta.id.assoc |
|
The haloId of the main progenitor of this subhalo.
|
| nextProgenitorId |
long |
meta.id.assoc |
|
The haloId of the "next progenitor" in the subhalo merger trees (the "next progenitor" of a subhalo S is the next most massive subhalo that has the same descendant as subhalo S).
|
| firstHaloInFOFgroupId |
long |
meta.id.assoc |
|
haloId of the dominant subhalo of the friend-of-friends group to which this subhalo belongs.
|
| nextHaloInFOFgroupId |
long |
meta.id.assoc |
|
Id of the next most massive halo within the same FOF group.
|
| snapNum |
int |
time |
|
The snapshot number where this subhalo was identified.
This column corresponds to the snapnum column in
the Snapshots table in the Millennium-II database.
|
| redshift |
float |
time |
|
The redshift of the snapshot to which this subhalo belongs.
|
| np |
int |
meta.number |
|
Number of simulation particles in this subhalo.
|
| m_crit200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the subhalo has an overdensity 200 times the critical density of the simulation.
Note: this value is only defined for subhalos with haloId=firstHaloInFOFgroupId. |
| m_mean200 |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the subhalo has an overdensity 200 times the mean density of the simulation.
Note: this value is only defined for subhalos with haloId=firstHaloInFOFgroupId. |
| m_tophat |
float |
phys.mass |
1010 Msun/h |
The mass within the radius where the subhalo has an overdensity corresponding to the value at virialisation in the
top-hat collapse model for this cosmology.
Note: this value is only defined for subhalos with haloId=firstHaloInFOFgroupId. |
| x |
float |
pos.cartesian.x |
Mpc/h |
The X-coordinate of the subhalo's position in comoving coordinates.
|
| y |
float |
pos.cartesian.y |
Mpc/h |
The Y-coordinate of the subhalo's position in comoving coordinates.
|
| z |
float |
pos.cartesian.z |
Mpc/h |
The Z-coordinate of the subhalo's position in comoving coordinates.
|
| ix |
integer |
pos.cartesian.x |
|
Zone index along x-direction, based on 20 bins
See the text on spatial indexes.
|
| iy |
integer |
pos.cartesian.x |
|
Zone index along y-direction, based on 20 bins
See the text on spatial indexes.
|
| iz |
integer |
pos.cartesian.x |
|
Zone index along z-direction, based on 20 bins
See the text on spatial indexes.
|
| phKey |
int |
|
|
The Peano-Hilbert index for the position of this subhalo.
|
| velX |
float |
phys.veloc |
km/sec |
The X-component of the subhalo's peculiar velocity.
|
| velY |
float |
phys.veloc |
km/sec |
The Y-component of the subhalo's peculiar velocity.
|
| velZ |
float |
phys.veloc |
km/sec |
The Z-component of the subhalo's peculiar velocity.
|
| vDisp |
float |
phys.veloc.dispersion |
km/sec |
The 1-D velocity dispersion of the subhalo, computed from all of the subhalo particles.
|
| vMax |
float |
phys.veloc.rotat |
km/sec |
Maximum of the circular velocity curve vCirc, where
vCirc2=G M(< r)/r
|
| vMaxRad |
float |
|
Mpc/h |
The radius at which the circular velocity maximum vMax is attained
|
| spinX |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The X-component of the spin of the subhalo.
|
| spinY |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Y-component of the spin of the subhalo.
|
| spinZ |
float |
phys.veloc.ang |
(Mpc/h) (km/sec) |
The Z-component of the spin of the subhalo.
|
| mostBoundID |
long |
meta.id.assoc |
|
The id of the most bound particle of this subhalo.
|
| fileNr |
int |
meta.file;meta.id |
|
Original file number in which the subhalo was defined.
See the documentation on identifiers for its
role in defining the haloId.
|
| subhaloIndex |
int |
meta.id.assoc |
|
Index of this subhalo in the file identified by fileNr.
|
| subhaloFileId |
long |
meta.id; |
|
This column corresponds to the subhaloFileId in the SubHalo table and gives an alternative way of identifying that halo.
This is an older way of identifying that subhalo, it is better to use the subhaloId column instead.
|
| halfmassRadius |
float |
phys.size.radius |
Mpc/h |
Radius containing half of the mass of the subhalo.
|
| random |
integer |
|
|
Random number between 0 and 1000000 using java.lang.Math.random().
See the page on random sampling.
|
| treeId |
long |
meta.id.parent |
|
The unique identifier of the L-Galaxies galaxy formation "tree" to which this subhalo belongs.
See the page on the MPA trees |
|
3.3.12 : Guo2010a
| (top) (separate page) |
|
This database stores the results of L-Galaxies semi-analytical galaxy
formation runs using the model described in Guo etal (2010).
The code was run on the halo trees extracted from the milli-Millennium (mMR), Millennium (MR), mini-Millennium-II (mMRII) and Millennium-II (MRII)
simulations.
|
3.3.12.1 : mMR & MR, mMRII & MRII
| (top) (separate page) |
|
The database Guo2010a contains four tables, MR, mMR, MRII and mMRII.
These all have the same columns. They store the results of running the L-Galaxies code version described in
Guo etal (2010) on the halo merger trees in, respectively, the
Millennium,
the milli-Millennium,
the Millennium-II
and the mini-Millennium-II simulations.
| column | type | UCD | unit | description |
|---|
| galaxyID | bigint | meta.id;meta.main | |
The unique identifier of this galaxy. Built from the topologically sorted merger tree as described in TBD |
| haloID | bigint | meta.id.parent | |
The haloId of the subhalo (in the appropriate halo table) containing this galaxy. |
| firstProgenitorId | bigint | meta.id.assoc | |
galaxyId of the first progenitor of this galaxy. Is galaxyId+1 iff lastProgenitorId > galaxyId, else -1 |
| nextProgenitorId | bigint | meta.id.assoc | |
galaxyId of next progenitor of this galaxy in the linked list structure used to facilitate traversing trees in code. |
| lastProgenitorId | bigint | meta.id.assoc | | The galaxyId of the last progenitor of this galaxy in the topological ordering used to assign galaxyId-s as described in TBD |
| fofCentralId | bigint | meta.id.assoc | | The galaxy id of the central galaxy of the FOF group this galaxy is in. |
| treeId | bigint | meta.id.parent | | Unique id of galaxy formation tree containing this galaxy. Note that this treeId does not identify merger trees but thelarger structures defining galaxy formation units.
The following equalities hold:
For MR and mMR: treeId = 1000000*floor(galaxyId/1000000).
For MRII and mMRII: treeId = 1000000000*floor(galaxyId/1000000000) |
| descendantId | bigint | meta.id.assoc | | galaxyId of the descendant of this galaxy in its merger tree. |
| mainLeafID | bigint | meta.id.assoc | | galaxyId of the leaf on the main branch this galaxy is part of. Obtained by following firstProgenitorId as far as it goes. |
| treeRootID | bigint | meta.id.assoc | | The galaxyId of the galaxy at the root of the merger tree this galaxy is in. Especially useful for speeding up queries for descendants for a given progenitor. See TBD for an example. |
| subHaloID | bigint | meta.id | | Id of the subhalo containing this galaxy,
as given by the column subhaloFileID in the MillenniumII..SubHalo, miniMilII..SubHalo table (for MRII and mMRII), and by the column subhaloId
in the MField.FOFSubHalo, millimil..FOFSubHalo tables (for MR and mMR).
Alternative to haloId.
|
| fofID | bigint | meta.id.assoc | | The subhaloId resp. subhaloFileId (for mMR and MR resp. mMRII and MRII, see documentation of subhaloId column in this table)
of the subhalo at the center of the FOF group containing this galaxy.
|
| phkey | int | | | The Peano-Hilbert index of the cell this galaxy is in, in the 2563 grid stored in MField...MField (for Millennium, not yet available for Millennium-II). Or, for mMR, the 83 density field in millimil..MMField |
| redshift | real | time | | The redshift corresponding to the snapnum (in MField..Snapshots for mMR and MR, MillenniumII..Snapshots for MRII and mMRII) for this galaxy. |
| type | int | src.class | | Type indicating whether galaxy is at center of FOF group (type=0), at center of subhalo that is not at center of its FOF gorup (type=1), or is a setellite that has lost its subhalo (type=2). |
| snapnum | int | time | | Snapshot index, from 0-63 for mMR and MR, 0..67 for mMRII and MRII. |
| centralMvir | real | phys.veloc.dispersion | 1010 Msun/h | The virial mass (as defined by m_crit200) of the FOF group the galaxy resides in. |
| x | real | pos.cartesian.x | Mpc/h | X-component of position of galaxy. |
| y | real | pos.cartesian.y | Mpc/h | Y-component of position of galaxy. |
| z | real | pos.cartesian.z | Mpc/h | Z-component of position of galaxy. |
| velX | real | phys.veloc | km/s | X-component of velocity of galaxy. |
| velY | real | phys.veloc | km/s | Y-component of velocity of galaxy. |
| velZ | real | phys.veloc | km/s | Z-component of velocity of galaxy. |
| np | int | meta.number | | Number of particles of the subhalo this galaxy is in. |
| mvir | real | phys.mass | 1010 Msun/h | Virial mass of the FOF group this galaxy was in when last it was a type 0 galaxy.
I.e. current mass for type 0 galaxies, "infall mass" for type 1,2 galaxies. |
| rvir | real | phys.size.radius | Mpc/h | Virial radius of the FOF group this galaxy was in when last it was a type 0 galaxy.
I.e. current Rvir for type 0 galaxies, "infall rvir" for type 1,2 galaxies |
| vvir | real | phys.veloc | km/s | Virial velocity of the subhalo the galaxy is/was the center of.
|
| vmax | real | phys.veloc.rotat | km/s | Maximum rotational velocity of the subhalo of which this galaxy is the center, or the last value for satellite galaxies.
|
| gasSpinX | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| gasSpinY | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| gasSpinZ | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| stellarSpinX | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| stellarSpinY | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| stellarSpinZ | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| infallVmax | real | phys.veloc.rotat | km/s | Maximum rotational velocity of the host halo of this galaxy at infallSnap. |
| infallSnap | int | time | | Most recent (largest) snapnum at which this galaxy's type changed from 0 to 1 or 2 |
| hotRadius | real | phys.size.radius | Mpc/h | Radius out to which hot gas extends: rvir for type 0; 0 for type 2; maximum radius out to which hot gas is not stripped for type 1. |
| oriMergeTime | real | [UCD] | 1339.77 Gyr | Estimated dyniamical friction time when the merger clock is set (in internal units of the code). |
| mergeTime | real | [UCD] | 1339.77 Gyr | Estimated remaining merging time. oriMergeTime - time since the merger clock is set. |
| coldGas | real | phys.mass | 1010 Msun /h | Mass in cold gas disk. |
| stellarMass | real | phys.mass | 1010 Msun /h | Total mass in stars in disk and bulge together. |
| bulgeMass | real | phys.mass | 1010 Msun /h | Mass of stars in bulge. |
| hotGas | real | phys.mass | 1010 Msun /h | Mass in hot gas. |
| ejectedMass | real | phys.mass | 1010 Msun /h | The ejected mass component (see de Lucia et al., 2004, MNRAS, Volume 349, 1101-1116).
|
| blackHoleMass | real | phys.mass | 1010 Msun /h | Mass of central black hole. |
| icmStellarMass | real | phys.mass | 1010 Msun /h | Mass in intra-cluster stars |
| metalsColdGas | real | phys.mass | 1010 Msun /h | Mass in metals in cold gas. |
| metalsStellarMass | real | phys.mass | 1010 Msun /h | Mass in metals in stars. |
| metalsBulgeMass | real | phys.mass | 1010 Msun /h | Mass in metals in stars in bulge. |
| metalsHotGas | real | phys.mass | 1010 Msun /h | Mass in metals in hot gas. |
| metalsEjectedMass | real | phys.mass | 1010 Msun /h | Mass in metals in the ejected mass component. |
| metalsICMStellarMass | real | phys.mass | 1010 Msun /h | Mass in metals in intra-cluster stars |
| sfr | real | phys.SFR | Msun/yr | Star formation rate |
| sfrBulge | real | phys.SFR | Msun/yr | Star formation rate in bulge. |
| xrayLum | real | em.X-Ray | log10(erg/sec) | Log10 of X-Ray luminosity in erg/sec |
| bulgeSize | real | phys.size.radius | Mpc/h | Half mass radius of bulge |
| stellarDiskRadius | real | phys.size.radius | Mpc/h | Size of the stellar disk, 3x the scale length. |
| gasDiskRadius | real | phys.size.radius | Mpc/h | Size of the gas disk, 3x the scale length. |
| disruptionOn | int | | | 0: galaxy merged onto merger center;
1: galaxy was disrupted before merging onto its descendant, matter went into ICM of merger center |
| mergeOn | int | | | 0: merger clock not set yet;
1: type 1 galaxy with baryon mass > halo mass, separate dynamical friction time calculated
2: this galaxy is type 2 and will merge into the merger center in the next snapshot
3: this galaxy is type 1 and will merge into the central galaxy of the main halo in the next snapshot |
| coolingRadius | real | phys.size.radius | Mpc/h | The radius within which the cooling time scale is shorter than the dynamical timescale
|
| u_mag | real | phot.mag;em.opt.U | | Rest frame total absolute magnitudes, SDSS u band. |
| g_mag | real | phot.mag;em.opt.B | | Rest frame total absolute magnitude, SDSS g band. |
| r_mag | real | phot.mag;em.opt.R | | Rest frame total absolute magnitude, SDSS r band. |
| i_mag | real | phot.mag;em.opt.I | | Rest frame total absolute magnitude, SDSS i band. |
| z_mag | real | phot.mag;em.opt | | Rest frame total absolute magnitude, SDSS z band. |
| uBulge | real | phot.mag;em.opt.U | | Rest frame absolute magnitude of bulge, SDSS u band. |
| gBulge | real | phot.mag;em.opt.B | | Rest frame absolute magnitude of bulge, SDSS g band. |
| rBulge | real | phot.mag;em.opt.R | | Rest frame absolute magnitude of bulge, SDSS r band. |
| iBulge | real | phot.mag;em.opt.I | | Rest frame absolute magnitude of bulge, SDSS i band. |
| zBulge | real | phot.mag;em.opt | | Rest frame absolute magnitude of bulge, SDSS z band. |
| uDust | real | phot.mag;em.opt.U | | Rest frame total absolute magnitude, SDSS u band, dust extinction included.
|
| gDust | real | phot.mag;em.opt.B | | Rest frame total absolute magnitude, SDSS g band, dust extinction included. |
| rDust | real | phot.mag;em.opt.R | | Rest frame total absolute magnitude, SDSS r band, dust extinction included. |
| iDust | real | phot.mag;em.opt.I | | Rest frame total absolute magnitude, SDSS i band, dust extinction included. |
| zDust | real | phot.mag;em.opt | | Rest frame total absolute magnitude, SDSS z band, dust extinction included. |
| massweightedAge | real | time.age | 109yr | The age of this galaxy, weighted by mass of its components. |
| uICL | real | phot.mag;em.opt.U | | Rest frame absolute magnitude of ICL, SDSS u band. |
| gICL | real | phot.mag;em.opt.B | | Rest frame absolute magnitude of ICL, SDSS i band |
| rICL | real | phot.mag;em.opt.R | | Rest frame absolute magnitude of ICL, SDSS i band |
| iICL | real | phot.mag;em.opt.I | | Rest frame absolute magnitude of ICL, SDSS i band |
| zICL | real | phot.mag;em.opt | | Rest frame absolute magnitude of ICL, SDSS i band |
|
3.3.13 : Henriques2012a
| (top) (separate page) |
|
This database stores lightcones derived from the Millennium Run galaxy catalogue in the Guo2010a database.
This link contains
a description of the "virtual observation" algorithm, as presented in
Henriques et al. (2012).
The lightcones were created using an updated version of the MoMaF code
(see Blaizot et al. (2005))
and the semi-analytic model presented in
Guo et al. (2011).
If you use the data from this dataset, please cite
Henriques et al. (2012) and
Guo et al. (2011)
as well as the relevant papers mentioned in the general
credits page,
G. Lemson & the Virgo Consortium (2006) and
V. Springel et al. (2005).
The database stores cones for galaxy catalogues created with the same physics, but using two different
stellar population synthesis algorithms, Bruzual & Charlot (2003) and Maraston (2005).
For each stellar population, the first set of cones contains: 24 pencil-beam lightcones (1.4 times 1.4 square degrees)
for different lines-of-sight with observer-frame apparent magnitudes in 40 bands; the same 24 pencil-beam lightcones
with rest-frame absolute magnitudes for SDSS and VISTA/2MASS bands; one allsky lightcone with SDSS and VISTA/2MASS
observer-frame apparent magnitudes [NB as of 2012-01-17 only a BC03 allsky map is available, an M05 version will be added soon].
All magnitudes are in the AB system.
(This link fully describes
the photometric properties available, including filter curves). All physical properties of galaxies can be obtained by
joining the lightcone tables with the Guo2010a catalog.
These catalogues still assume the WMAP 1 cosmology of the Millennium simulations. A second set will be published
soon based on the WMAP 7 cosmology, produced with the scaling algorithm of Angulo & White (2010).
No flux limits are imposed, except for the all sky maps (i<21.0). Nonetheless, due to the resolution of the dark matter
simulation used to construct the semi-analytic model
(Millennium Run, see Springel et al. (2005)),
objects with stellar mass bellow 109 Msun should not be used.
In this link, we present all
the queries used to produce the plots in
Henriques et al. (2012)
(number counts, redshift distributions, B-band luminosity function, K-band luminosity function and colour distributions)
and some other useful examples.
|
3.3.13.1 : Light Cone Construction
| (top) (separate page) |
|
The lightcones were constructed using the MoMaf code
(Blaizot et al. (2005))
with some modifications fully described in section 2.2 of
Henriques et al. (2012)
The millennium simulation has side of 500Mpc/h which is considerably smaller than, for example, the commoving
distance to z=2. In order to build a lightcone it is then necessary to periodically replicate the simulation box,
which can lead to multiple appearances of the same object. Blaizot et al. (2005) suggested applying a set of
transformations (rotations, translations and inversions) in order for these duplicates not to fall on a nearly
regular lattice. However Kitzbichler & White (2007) showed that, for lightcones of relatively small solid angle,
the central line-of-sight can be chosen in such a direction that appearances of multiple images of the same object
are minimized. We therefore use this method.
The time between stored snapshots for the Millennium Simulation varies between 100 and 380 Myr. This means that the
intrinsic properties of galaxies are not generally available at the time corresponding to their commoving distance.
Rather they must be taken from the stored snapshot which is closest to their lightcone position. Hence, galaxies
with redshift (zi+zi-1)/2<z<(zi+zi+1)/2 are assigned the physical
properties stored at zi. No interpolation in physical properties between snapshots is applied (which has
no impact in the statistical properties of galaxies).
On the other hand, the apparent luminosities and colours of galaxies depend strongly on their redshifts through the
conversion between rest- and observed-frame photometric bands and through the inverse square dependence of apparent
luminosity on distance. The final redshift of the galaxy in the lightcone is not available at the time observed-frame
luminosities are computed in the semi-analytic model. However, there will be two extreme redshifts that bracket it.
We compute apparent observed-frame luminosities (for fixed intrinsic properties) using these upper and lower limits,
and once the galaxy is placed in the lightcone, we interpolate to obtain final observed-frame quantities.
|
3.3.13.2 : Photometry
| (top) (separate page) |
|
The magnitudes in the lightcones are available for two stellar populations synthesis models: Bruzual & Charlot (2003)
and Maraston (2005). For both models the same Chabrier (2003) IMF was adopted. All magnitudes are in the AB system.
We have significantly expanded the number and wavelegth coverage of photometric bands for which fluxes are computed,
from observed-frame UV to the IRAC near-infrared. The 40 filters available are presented in the following figure and
their curves are available in this link.
Top panel: GALEX FUV and NUV, Johnson-Bessel U, B, V, Cousins Rc, Ic, VISTA Z, Y, J, H,
Ks, Johnson-Bessel K and IRAC 3.6μm, 4.5μm, 5.8μm and 8.0 μm bands;
Second panel: SDSS u, g, r, i, z bands;
Third panel: bands from HST instruments, three UV bands from the WFC3-UVIS (0.225μm, 0.275μm, 0.336μm),
seven optical bands from the ACS-WFC (0.435μm, 0.475μm, 0.606μm, 0.625μm, 0.775μm, 0.814μm,
0.850μm) and three near-infrared bands from the WFC3-IR (1.05μm, 1.25μm, 1.60μm);
Bottom panel: VIMOS U band, 2 NICMOS near-infrared bands (1.1μm and 1.6μm) and two
WFPC2 bands (0.30μm and 0.45μm).
Together with the observed-frame photometry we also provide rest-frame data for a restricted set of bands
(SDSS and VISTA/2MASS). This is aimed at making the lightcones a better tool to test observational
derivations of intrinsic galaxy properties. The wide wavelength coverage of observed- and rest-frame
photometry, together with the two stellar population synthesis models considered, can be used to check
derivations of rest-frame magnitudes from observed photometry, as well as the reliability of properties
obtained from SED fitting, such as stellar masses, ages and star-formation histories (intrinsically predicted
by the semi-analytic model).
|
3.3.13.3 : Example Queries
| (top) (separate page) |
|
To retrieve information about the galaxies one can join the lightcones with the Guo2010a..MR database
as in the following example:
select c.*, g.stellarmass, g.coldgas
from Henriques2012a.wmap1.M05_001 c
, Guo2010a..MR g
where g.galaxyid = c.galid
which gives the properties in the lightcone plus Stellar and Cold Gas Mass for all the galaxies in the lightcone.
Galaxy number counts for the B-band (Fig. 2 in henriques et al. 2012a)
select .5*(.5+floor(B/.5)) as B,
count(*) as num
from Henriques2012a.wmap1.M05_001
where B < 30.0
group by floor(B/.5)
order by 1
(divide num by 0.5*1.4*1.4 (bin*deg2) to obtain the same normalization as in henriques et al. 2012a)
Redshift distribution of galaxies for a Ks-band limited sample (observed Ks<23.3) (Fig. 3 in henriques et al. 2012a)
select .5*(.5+floor(z_geo/.5)) as z_geo,
count(*) as num
from Henriques2012a.wmap1.M05_001
where Ks < 23.3
group by floor(z_geo/.5)
order by 1
(divide num by 0.5*1.4*1.4*3600. (bin*arcmin2) to obtain the same normalization as in henriques et al. 2012a)
Reat-Frame B-Band Luminosity Function (Fig. 4 in henriques et al. 2012a)
select .5*(.5+floor(B/.5)) as B
count(*) as
from Henriques2012a.wmap1_rest.M05_001
where z_geo > 0.2 and z_geo < 0.4 and B < -15.0
group by floor(B/.5)
order by 1
(divide num by 0.5*volume to obtain the same normalization as in henriques et al. 2012a,
volume=5.86e5 Mpc3/h3 (0.2<z<0.4), volume=1.32e6 Mpc3/h3 (0.4<z<0.6),
volume=6.27e6 Mpc3/h3 (0.8<z<1.2),
volume=1.57e7 Mpc3/h3 (1.3<z2<.0), volume=5.02e5 Mpc3/h3 (2.5<z<3.5))
Reat-Frame K-Band Luminosity Function (Fig. 4 in henriques et al. 2012a)
select .5*(.5+floor(K/.5)) as K
count(*) as
from Henriques2012a.wmap1_rest.M05_001
where z_geo > 0.2 and z_geo < 0.4 and K < -15.0
group by floor(K/.5)
order by 1
(divide num by 0.5*volume to obtain the same normalization as in henriques et al. 2012a,
volume=8.32e5 Mpc3/h3 (0.25<z<0.75), volume=1.95e6 Mpc3/h3 (0.75<z<1.25),
volume=2.67e6 Mpc3/h3 (1.25<z<1.75),
volume=3.01e6 Mpc3/h3 (1.75<z<2.25), volume=3.08e6 Mpc3/h3 (2.75<z<3.25))
Rest-frame galaxy colours for a flux limited sample (observed K<23.0) (Fig. 6 in henriques et al. 2012a)
select b.U, b.V, b.J,
b.z_geo
from Henriques2012a.wmap1_rest.M05_001 a,
Henriques2012a.wmap1.M05_001 b
where b.GalID=a.GalID and a.K < 23.0
|
3.3.13.4 : Pencil Beam Tables
| (top) (separate page) |
|
All the pencil-beam lightcones stored in the Henriques2012a table have the same structure.
The difference is in the cosmology, wmap1 or wmap7 and in the stellar population synthesis models.
The cosmology is indicated by the database schema the tables reside in.
The synthesis model by the names of the tables themselves. We have the following tables:
Henriques2012a.wmap1.BC03_[001 to 024]
Henriques2012a.wmap1.M05_[001 to 024]
Each schema contains light cones for 24 different lines-of-sight (which can be used to test the effects of cosmic
variance). Total and bulge observer-frame apparent magnitudes in 40 different photometric bands are included both
corrrected for dust extinction (all in AB system). These cones were created from the galaxies in Guo2010a..MR (but
with the extended photometry). To retrieve information about the physical properties of galaxies one can join to
that table as in the following example:
select c.*, g.stellarmass, g.coldgas
from Henriques2012a.wmap1.M05_001 c
, Guo2010a..MR g
where g.galaxyid = c.galid
| name | datatype | unit | UCD | description |
|---|
| GalID | bigint | | [ucd] | Identifier of the galaxy in the Guo2010a..MR table.
Pointer to the galaxyId column in that table. |
| HaloID | bigint | | [ucd] | Identifier of the halo (in the MPHalotrees..MHalo
table) that this galaxy resides in. Pointer to the haloId column in that table. |
| cx | real | Mpc/h | [ucd] | X-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| cy | real | Mpc/h | [ucd] | Y-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| cz | real | Mpc/h | [ucd] | Z-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| ra | real | deg | [ucd] | Right ascension, i.e. longitude component of the galaxy's position on the sky.
Assumed that center of cone is at RA=0. |
| dec | real | deg | [ucd] | Declination, i.e. latitude component of the galaxy's position on the sky.
Assumed that center of cone is at Dec=0. |
| z_geo | real | | [ucd] | Redshift of the galaxy based on its position.
Peculiar velocity is not included. |
| z_app | real | | [ucd] | Apparent redshift. Including peculiar velocity. |
| dlum | real | Mpc/h | [ucd] | Luminosity distance in Mpc/h. |
| vlos | real | km/s | [ucd] | Line-of-sight velocity of the galaxy in km/s. |
| incl | real | deg | [ucd] | Inclination of the galaxy. Randomly generated and used in
the galaxy formation model to perform dust correction on the luminosities. |
| U | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel U filter (dust corrected) of the galaxy. |
| B | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel B filter (dust corrected) of the galaxy. |
| V | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel V filter (dust corrected) of the galaxy. |
| Rc | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Cousins Rc filter (dust corrected) of the galaxy. |
| Ic | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Cousins Ic filter (dust corrected) of the galaxy. |
| Z | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA Z filter (dust corrected) of the galaxy. |
| Y | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA Y filter (dust corrected) of the galaxy. |
| J | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS J filter (dust corrected) of the galaxy. |
| H | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS H filter (dust corrected) of the galaxy. |
| K | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel K filter (dust corrected) of the galaxy. |
| Ks | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS Ks filter (dust corrected) of the galaxy. |
| i1 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 3.6μm filter (dust corrected) of the galaxy. |
| i2 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 4.5μm filter (dust corrected) of the galaxy. |
| i3 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 5.8μm filter (dust corrected) of the galaxy. |
| i4 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 8.0μm filter (dust corrected) of the galaxy. |
| SDSS_u | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS u filter (dust corrected) of the galaxy. |
| SDSS_g | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS g filter (dust corrected) of the galaxy. |
| SDSS_r | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS r filter (dust corrected) of the galaxy. |
| SDSS_i | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS i filter (dust corrected) of the galaxy. |
| SDSS_z | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS z filter (dust corrected) of the galaxy. |
| U_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel U filter (dust corrected) of the bulge. |
| B_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel B filter (dust corrected) of the bulge. |
| V_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel V filter (dust corrected) of the bulge. |
| Rc_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Cousins Rc filter (dust corrected) of the bulge. |
| Ic_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Cousins Ic filter (dust corrected) of the bulge. |
| Z_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA Z filter (dust corrected) of the bulge. |
| Y_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA Y filter (dust corrected) of the bulge. |
| J_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS J filter (dust corrected) of the bulge. |
| H_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS H filter (dust corrected) of the bulge. |
| K_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the Johnson-Bessel K filter (dust corrected) of the bulge. |
| Ks_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS Ks filter (dust corrected) of the bulge. |
| i1_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 3.6μm filter (dust corrected) of the bulge. |
| i2_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 4.5μm filter (dust corrected) of the bulge. |
| i3_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 5.8μm filter (dust corrected) of the bulge. |
| i4_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the IRAC 8.0μm filter (dust corrected) of the bulge. |
| SDSS_u_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS u filter (dust corrected) of the bulge. |
| SDSS_g_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS g filter (dust corrected) of the bulge. |
| SDSS_r_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS r filter (dust corrected) of the bulge. |
| SDSS_i_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS i filter (dust corrected) of the bulge. |
| SDSS_z_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS z filter (dust corrected) of the bulge. |
| ACS435 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.435μm filter (dust corrected) of the galaxy. |
| ACS475 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.475μm filter (dust corrected) of the galaxy. |
| ACS606 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.606μm filter (dust corrected) of the galaxy. |
| ACS625 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.625μm filter (dust corrected) of the galaxy. |
| ACS775 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.775μm filter (dust corrected) of the galaxy. |
| ACS814 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.814μm filter (dust corrected) of the galaxy. |
| ACS850 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.850μm filter (dust corrected) of the galaxy. |
| GFUV | real | | [ucd] | Observer-frame apparent (AB) magnitude in the GALEX FUV filter (dust corrected) of the galaxy. |
| GNUV | real | | [ucd] | Observer-frame apparent (AB) magnitude in the GALEX NUV filter (dust corrected) of the galaxy. |
| NIC110 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the NICMOS 1.1μm filter (dust corrected) of the galaxy. |
| NIC160 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the NICMOS 1.6μm filter (dust corrected) of the galaxy. |
| VIMOSU | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VIMOS U filter (dust corrected) of the galaxy. |
| WFC105 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-IR 1.05μm filter (dust corrected) of the galaxy. |
| WFC125 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-IR 1.25μm filter (dust corrected) of the galaxy. |
| WFC160 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-IR 1.60μm filter (dust corrected) of the galaxy. |
| WFC225 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-UVIS 0.225μm filter (dust corrected) of the galaxy. |
| WFC275 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-UVIS 0.275μm filter (dust corrected) of the galaxy. |
| WFC336 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-UVIS 0.336μm filter (dust corrected) of the galaxy. |
| WFPC300 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFPC2 0.300μm filter (dust corrected) of the galaxy. |
| WFPC450 | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFPC2 0.450μm filter (dust corrected) of the galaxy. |
| ACS435_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.435μm filter (dust corrected) of the bulge. |
| ACS475_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.475μm filter (dust corrected) of the bulge. |
| ACS606_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.606μm filter (dust corrected) of the bulge. |
| ACS625_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.625μm filter (dust corrected) of the bulge. |
| ACS775_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.775μm filter (dust corrected) of the bulge. |
| ACS814_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.814μm filter (dust corrected) of the bulge. |
| ACS850_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST ACS-WFC 0.850μm filter (dust corrected) of the bulge. |
| GFUV_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the GALEX FUV filter (dust corrected) of the bulge. |
| GNUV_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the GALEX NUV filter (dust corrected) of the bulge. |
| NIC110_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the NICMOS 1.1μm filter (dust corrected) of the bulge. |
| NIC160_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the NICMOS 1.6μm filter (dust corrected) of the bulge. |
| VIMOSU_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VIMOS U filter (dust corrected) of the bulge. |
| WFC105_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-IR 1.05μm filter (dust corrected) of the bulge. |
| WFC125_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-IR 1.25μm filter (dust corrected) of the bulge. |
| WFC160_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-IR 1.60μm filter (dust corrected) of the bulge. |
| WFC225_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-UVIS 0.225μm filter (dust corrected) of the bulge. |
| WFC275_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-UVIS 0.275μm filter (dust corrected) of the bulge. |
| WFC336_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFC3-UVIS 0.336μm filter (dust corrected) of the bulge. |
| WFPC300_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFPC2 0.300μm filter (dust corrected) of the bulge. |
| WFPC450_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the HST WFPC2 0.450μm filter (dust corrected) of the bulge. |
|
3.3.13.5 : Rest Frame Pencil Beam Tables
| (top) (separate page) |
|
Rest-frame lightcones redsiding in the schema wmap1_rest. They have the same galaxies as the corresponding
observer-frame lightcones, but their magnitudes are in the absolute rest-frame and a only subset of bands is available:
the SDSS bands, the Johnson-Bessel B band and the VISTA YJHKs bands (similar to 2MASS JHKs).
These are aimed at providing a useful tool to test observational conversions between observed- and rest-frame photometry.
| name | datatype | unit | UCD | description |
|---|
| GalID | bigint | | [ucd] | Identifier of the galaxy in the Guo2010a..MR table.
Pointer to the galaxyId column in that table. |
| HaloID | bigint | | [ucd] | Identifier of the halo (in the MPHalotrees..MHalo
table) that this galaxy resides in. Pointer to the haloId column in that table. |
| cx | real | Mpc/h | [ucd] | X-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended |
| cy | real | Mpc/h | [ucd] | Y-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| cz | real | Mpc/h | [ucd] | Z-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| ra | real | deg | [ucd] | Right ascension, i.e. longitude component of the galaxy's position on the sky.
Assumed that center of cone is at RA=0. |
| dec | real | deg | [ucd] | Declination, i.e. latitude component of the galaxy's position on the sky.
Assumed that center of cone is at Dec=0. |
| z_geo | real | | [ucd] | Redshift of the galaxy based on its position.
Peculiar velocity is not included. |
| z_app | real | | [ucd] | Apparent redshift. Including peculiar velocity. |
| dlum | real | Mpc/h | [ucd] | Luminosity distance in Mpc/h. |
| vlos | real | km/s | [ucd] | Line-of-sight velocity of the galaxy in km/s. |
| incl | real | deg | [ucd] | Inclination of the galaxy. Randomly generated and used in
the galaxy formation model to perform dust correction on the luminosities. |
| SDSS_u | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS u filter (dust corrected) of the galaxy. |
| B | real | | [ucd] | Rest-frame absolute (AB) magnitude in the Johnson-Bessel B filter (dust corrected) of the galaxy. |
| SDSS_g | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS g filter (dust corrected) of the galaxy. |
| SDSS_r | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS r filter (dust corrected) of the galaxy. |
| SDSS_i | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS i filter (dust corrected) of the galaxy. |
| SDSS_z | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS z filter (dust corrected) of the galaxy. |
| Y | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA Y filter (dust corrected) of the galaxy. |
| J | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA/2MASS J filter (dust corrected) of the galaxy. |
| H | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA/2MASS H filter (dust corrected) of the galaxy. |
| Ks | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA/2MASS Ks filter (dust corrected) of the galaxy. |
| SDSS_u_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS u filter (dust corrected) of the bulge. |
| B_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the Johnson-Bessel B filter (dust corrected) of the bulge. |
| SDSS_g_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS g filter (dust corrected) of the bulge. |
| SDSS_r_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS r filter (dust corrected) of the bulge. |
| SDSS_i_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS i filter (dust corrected) of the bulge. |
| SDSS_z_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the SDSS z filter (dust corrected) of the bulge. |
| Y_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA Y filter (dust corrected) of the bulge. |
| J_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA/2MASS J filter (dust corrected) of the bulge. |
| H_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA/2MASS H filter (dust corrected) of the bulge. |
| Ks_Bulge | real | | [ucd] | Rest-frame absolute (AB) magnitude in the VISTA/2MASS Ks filter (dust corrected) of the bulge. |
|
3.3.13.6 : All Sky Map Tables
| (top) (separate page) |
|
An all sky lightcone created using the Bruzual & Charlot (2003) stellar populations
resides in the table wmap1.BC03_AllSky_001. It was constructed by replicating the Millennium simulation
box (500Mpc/h on a side) with no additional transformations applied. The catalogue is limited to an apparent observer-frame
AB magnitude of i< 21.0 and includes apparent observer-frame magnitudes for 9 filters: SDSS u, g, r, i, z and VISTA Y, J, H,
Ks. The algorithm is equivalent to the one used for the all sky map in
MPAMocks..Blaizot2006_AllSky_PT_1.
| name | datatype | unit | UCD | description |
|---|
| GalID | bigint | | [ucd] | Identifier of the galaxy in the Guo2010a..MR table.
Pointer to the galaxyId column in that table. |
| HaloID | bigint | | [ucd] | Identifier of the halo (in the MPHalotrees..MHalo
table) that this galaxy resides in. Pointer to the haloId column in that table. |
| cx | real | Mpc/h | [ucd] | X-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended |
| cy | real | Mpc/h | [ucd] | Y-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| cz | real | Mpc/h | [ucd] | Z-component of galaxy's position in 3D space.
Origin of coordinate system is at the origin of the cone. The coordinate axes are aligned with those of the simulation box
which is supposed to be periodically extended. |
| ra | real | deg | [ucd] | Right ascension, i.e. longitude component of the galaxy's position on the sky.
Assumed that center of cone is at RA=0. |
| dec | real | deg | [ucd] | Declination, i.e. latitude component of the galaxy's position on the sky.
Assumed that center of cone is at Dec=0. |
| z_geo | real | | [ucd] | Redshift of the galaxy based on its position.
Peculiar velocity is not included. |
| z_app | real | | [ucd] | Apparent redshift. Including peculiar velocity. |
| dlum | real | Mpc/h | [ucd] | Luminosity distance in Mpc/h. |
| vlos | real | km/s | [ucd] | Line-of-sight velocity of the galaxy in km/s. |
| incl | real | deg | [ucd] | Inclination of the galaxy. Randomly generated and used in
the galaxy formation algorithms to perform dust correction on the luminosities. |
| SDSS_u | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS u filter (dust corrected) of the galaxy. |
| SDSS_g | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS g filter (dust corrected) of the galaxy. |
| SDSS_r | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS r filter (dust corrected) of the galaxy. |
| SDSS_i | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS i filter (dust corrected) of the galaxy. |
| SDSS_z | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS z filter (dust corrected) of the galaxy. |
| Y | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA Y filter (dust corrected) of the galaxy. |
| J | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS J filter (dust corrected) of the galaxy. |
| H | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS H filter (dust corrected) of the galaxy. |
| Ks | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS Ks filter (dust corrected) of the galaxy. |
| SDSS_u_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS u filter (dust corrected) of the bulge. |
| SDSS_g_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS g filter (dust corrected) of the bulge. |
| SDSS_r_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS r filter (dust corrected) of the bulge. |
| SDSS_i_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS i filter (dust corrected) of the bulge. |
| SDSS_z_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the SDSS z filter (dust corrected) of the bulge. |
| Y_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA Y filter (dust corrected) of the bulge. |
| J_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS J filter (dust corrected) of the bulge. |
| H_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS H filter (dust corrected) of the bulge. |
| Ks_Bulge | real | | [ucd] | Observer-frame apparent (AB) magnitude in the VISTA/2MASS Ks filter (dust corrected) of the bulge. |
|
3.3.14 : Guo2013a
| (top) (separate page) |
|
This database stores the results of L-Galaxies semi-analytical galaxy
formation runs using the model described in Guo etal (2013).
The goal was to create galaxy catalogues for a WMAP7 cosmology.
To do so the scaling method from
Angulo \& White (2010)
was applied to the halo merger trees from the Millennium and Millennium-II simulations.
For testing the results of the scaling method, the semi-analytics was also applied to the halo merger trees
from the new Millennium-WMAP7 simulation. The halo merger trees of these simulations are stored in the
database MPAHalotrees.
|
3.3.14.1 : MR7, MRscWMAP7 & MRIIscWMAP7
| (top) (separate page) |
|
The database Guo2013a contains three tables, MR7, MRscWMAP7c and MRIIscWMAP7.
They store the results of running the L-Galaxies code version described in
Guo etal (2013)(ads) on the
halo merger stored in tables with the same name in the
MPAHaloTrees database.
The names also refer to the (scaled) simulations from which they were extracted and which are described
here.
The tables all have the same columns shown below. The many different "id"-columns implement pointers that
allow one to traverse the merging trees in different ways. For an explanation of how merger trees are represented
in these tables see this page.
| column | type | UCD | unit | description |
|---|
| galaxyID | bigint | meta.id;meta.main | |
The unique identifier of this galaxy. Built from the topologically sorted merger tree as described in TBD |
| haloID | bigint | meta.id.parent | |
The haloId of the subhalo (in the halo table with the same name in
MPAHaloTrees) containing this galaxy.
TBD add link to more detailed explanation |
| firstProgenitorId | bigint | meta.id.assoc | |
galaxyId of the first progenitor of this galaxy. Strictly galaxyId+1 iff lastProgenitorId > galaxyId, else -1.
TBD add link to more detailed explanation |
| nextProgenitorId | bigint | meta.id.assoc | |
galaxyId of next progenitor of this galaxy in the linked list structure used to facilitate traversing trees in code.
TBD add link to more detailed explanation |
| lastProgenitorId | bigint | meta.id.assoc | |
The galaxyId of the last progenitor of this galaxy in the topological ordering used to assign galaxyId-s as
described in this page. |
| fofCentralId | bigint | meta.id.assoc | | The galaxy id of the central galaxy of the FOF group this galaxy is in. |
| treeId | bigint | meta.id.parent | | Unique id of galaxy formation tree containing this galaxy. Note that this treeId does not identify merger trees but thelarger structures defining galaxy formation units.
The following equalities hold:
For MR and mMR: treeId = 1000000*floor(galaxyId/1000000).
For MRII and mMRII: treeId = 1000000000*floor(galaxyId/1000000000) |
| descendantId | bigint | meta.id.assoc | | galaxyId of the descendant of this galaxy in its merger tree. |
| mainLeafID | bigint | meta.id.assoc | | galaxyId of the leaf on the main branch this galaxy is part of. Obtained by following firstProgenitorId as far as it goes. |
| treeRootID | bigint | meta.id.assoc | | The galaxyId of the galaxy at the root of the merger tree this galaxy is in. Especially useful for speeding up queries for descendants for a given progenitor. See TBD for an example. |
| subHaloID | bigint | meta.id | | Id of the subhalo containing this galaxy,
as given by the column subhaloFileID in the MillenniumII..SubHalo, miniMilII..SubHalo table (for MRII and mMRII), and by the column subhaloId
in the MField.FOFSubHalo, millimil..FOFSubHalo tables (for MR and mMR).
Alternative to haloId.
|
| fofID | bigint | meta.id.assoc | | The subhaloId resp. subhaloFileId (for mMR and MR resp. mMRII and MRII, see documentation of subhaloId column in this table)
of the subhalo at the center of the FOF group containing this galaxy.
|
| phkey | int | | | The Peano-Hilbert index of the cell this galaxy is in, in the 2563 grid stored in MField...MField (for Millennium, not yet available for Millennium-II). Or, for mMR, the 83 density field in millimil..MMField |
| redshift | real | time | | The redshift corresponding to the snapnum (in MField..Snapshots for mMR and MR, MillenniumII..Snapshots for MRII and mMRII) for this galaxy. |
| type | int | src.class | | Type indicating whether galaxy is at center of FOF group (type=0), at center of subhalo that is not at center of its FOF gorup (type=1), or is a setellite that has lost its subhalo (type=2). |
| snapnum | int | time | |
The snapshot number where this galaxy was identified.
This column is a
foreign key to the snapnum column in the
table
in the Snapshots database
with the same name as current Guo2012a galaxies table.
I.e. Snapshots..MR7, Snapshots..MRscWMAP7 or Snapshots..MRIIscWMAP7
|
| centralMvir | real | phys.veloc.dispersion | 1010 Msun/h | The virial mass (as defined by m_crit200) of the FOF group the galaxy resides in. |
| x | real | pos.cartesian.x | Mpc/h | X-component of position of galaxy. |
| y | real | pos.cartesian.y | Mpc/h | Y-component of position of galaxy. |
| z | real | pos.cartesian.z | Mpc/h | Z-component of position of galaxy. |
| velX | real | phys.veloc | km/s | X-component of velocity of galaxy. |
| velY | real | phys.veloc | km/s | Y-component of velocity of galaxy. |
| velZ | real | phys.veloc | km/s | Z-component of velocity of galaxy. |
| np | int | meta.number | | Number of particles of the subhalo this galaxy is in. |
| mvir | real | phys.mass | 1010 Msun/h | Virial mass of the FOF group this galaxy was in when last it was a type 0 galaxy.
I.e. current mass for type 0 galaxies, "infall mass" for type 1,2 galaxies. |
| rvir | real | phys.size.radius | Mpc/h | Virial radius of the FOF group this galaxy was in when last it was a type 0 galaxy.
I.e. current Rvir for type 0 galaxies, "infall rvir" for type 1,2 galaxies |
| vvir | real | phys.veloc | km/s | Virial velocity of the subhalo the galaxy is/was the center of.
|
| vmax | real | phys.veloc.rotat | km/s | Maximum rotational velocity of the subhalo of which this galaxy is the center, or the last value for satellite galaxies.
|
| gasSpinX | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| gasSpinY | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| gasSpinZ | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the cold gas disk |
| stellarSpinX | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| stellarSpinY | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| stellarSpinZ | real | phys.veloc.ang | Mpc/h km/s | The X-component of the spin of the stellar disk |
| infallVmax | real | phys.veloc.rotat | km/s | Maximum rotational velocity of the host halo of this galaxy at infallSnap. |
| infallSnap | int | time | | Most recent (largest) snapnum at which this galaxy's type changed from 0 to 1 or 2 |
| hotRadius | real | phys.size.radius | Mpc/h | Radius out to which hot gas extends: rvir for type 0; 0 for type 2; maximum radius out to which hot gas is not stripped for type 1. |
| oriMergeTime | real | [UCD] | 1339.77 Gyr | Estimated dyniamical friction time when the merger clock is set (in internal units of the code). |
| mergeTime | real | [UCD] | 1339.77 Gyr | Estimated remaining merging time. oriMergeTime - time since the merger clock is set. |
| coldGas | real | phys.mass | 1010 Msun /h | Mass in cold gas disk. |
| stellarMass | real | phys.mass | 1010 Msun /h | Total mass in stars in disk and bulge together. |
| bulgeMass | real | phys.mass | 1010 Msun /h | Mass of stars in bulge. |
| hotGas | real | phys.mass | 1010 Msun /h | Mass in hot gas. |
| ejectedMass | real | phys.mass | 1010 Msun /h | The ejected mass component (see de Lucia et al., 2004, MNRAS, Volume 349, 1101-1116).
|
| blackHoleMass | real | phys.mass | 1010 Msun /h | Mass of central black hole. |
| icmStellarMass | real | phys.mass | 1010 Msun /h | Mass in intra-cluster stars |
| metalsColdGas | real | phys.mass | 1010 Msun /h | Mass in metals in cold gas. |
| metalsStellarMass | real | phys.mass | 1010 Msun /h | Mass in metals in stars. |
| metalsBulgeMass | real | phys.mass | 1010 Msun /h | Mass in metals in stars in bulge. |
| metalsHotGas | real | phys.mass | 1010 Msun /h | Mass in metals in hot gas. |
| metalsEjectedMass | real | phys.mass | 1010 Msun /h | Mass in metals in the ejected mass component. |
| metalsICMStellarMass | real | phys.mass | 1010 Msun /h | Mass in metals in intra-cluster stars |
| sfr | real | phys.SFR | Msun/yr | Star formation rate |
| sfrBulge | real | phys.SFR | Msun/yr | Star formation rate in bulge. |
| xrayLum | real | em.X-Ray | log10(erg/sec) | Log10 of X-Ray luminosity in erg/sec |
| bulgeSize | real | phys.size.radius | Mpc/h | Half mass radius of bulge |
| stellarDiskRadius | real | phys.size.radius | Mpc/h | Size of the stellar disk, 3x the scale length. |
| gasDiskRadius | real | phys.size.radius | Mpc/h | Size of the gas disk, 3x the scale length. |
| disruptionOn | int | | | 0: galaxy merged onto merger center;
1: galaxy was disrupted before merging onto its descendant, matter went into ICM of merger center |
| mergeOn | int | | | 0: merger clock not set yet;
1: type 1 galaxy with baryon mass > halo mass, separate dynamical friction time calculated
2: this galaxy is type 2 and will merge into the merger center in the next snapshot
3: this galaxy is type 1 and will merge into the central galaxy of the main halo in the next snapshot |
| coolingRadius | real | phys.size.radius | Mpc/h | The radius within which the cooling time scale is shorter than the dynamical timescale
|
| u_mag | real | phot.mag;em.opt.U | | Rest frame total absolute magnitudes, SDSS u band. |
| g_mag | real | phot.mag;em.opt.B | | Rest frame total absolute magnitude, SDSS g band. |
| r_mag | real | phot.mag;em.opt.R | | Rest frame total absolute magnitude, SDSS r band. |
| i_mag | real | phot.mag;em.opt.I | | Rest frame total absolute magnitude, SDSS i band. |
| z_mag | real | phot.mag;em.opt | | Rest frame total absolute magnitude, SDSS z band. |
| uBulge | real | phot.mag;em.opt.U | | Rest frame absolute magnitude of bulge, SDSS u band. |
| gBulge | real | phot.mag;em.opt.B | | Rest frame absolute magnitude of bulge, SDSS g band. |
| rBulge | real | phot.mag;em.opt.R | | Rest frame absolute magnitude of bulge, SDSS r band. |
| iBulge | real | phot.mag;em.opt.I | | Rest frame absolute magnitude of bulge, SDSS i band. |
| zBulge | real | phot.mag;em.opt | | Rest frame absolute magnitude of bulge, SDSS z band. |
| uDust | real | phot.mag;em.opt.U | | Rest frame total absolute magnitude, SDSS u band, dust extinction included.
|
| gDust | real | phot.mag;em.opt.B | | Rest frame total absolute magnitude, SDSS g band, dust extinction included. |
| rDust | real | phot.mag;em.opt.R | | Rest frame total absolute magnitude, SDSS r band, dust extinction included. |
| iDust | real | phot.mag;em.opt.I | | Rest frame total absolute magnitude, SDSS i band, dust extinction included. |
| zDust | real | phot.mag;em.opt | | Rest frame total absolute magnitude, SDSS z band, dust extinction included. |
| massweightedAge | real | time.age | 109yr | The age of this galaxy, weighted by mass of its components. |
| uICL | real | phot.mag;em.opt.U | | Rest frame absolute magnitude of ICL, SDSS u band. |
| gICL | real | phot.mag;em.opt.B | | Rest frame absolute magnitude of ICL, SDSS i band |
| rICL | real | phot.mag;em.opt.R | | Rest frame absolute magnitude of ICL, SDSS i band |
| iICL | real | phot.mag;em.opt.I | | Rest frame absolute magnitude of ICL, SDSS i band |
| zICL | real | phot.mag;em.opt | | Rest frame absolute magnitude of ICL, SDSS i band |
|
4 : Online Access
| (top) (separate page) |
|
The Millennium databases are made available online by the German Astrophysical Virtual Observatory
(GAVO).
GAVO uses an Apache Tomcat Java web server deployed on machines
at the Max-Planck Institute for extraterrestrial Physics
(MPE).
This webserver manages user accounts for the shielded part of the database and performs all the
query functions for the user.
The web server itself can be accessed through a variety of clients.
These are described in the pages accessible at the top.
|
4.1 : Web Browser Interface
| (top) (separate page) |
|
In this page we explain the use of the web interface for querying the database. This will (hopefully) not be
the main interface for long for most users, as other access methods to the databases listed in the following few
pages are more efficient. But for getting to know the databas estructure and trying out queries it will remain useful.
The web interface is reproduced below in two parts as a complete page is too large to fit on the screen in general.
The first part shows the top part, the second the part with results of queries. Each part has red boxes which are
active and from which one reaches the corresponding description.
Sessions
First a short word about sessions. Everytime a user connects for the first time to the web application
a sessioni> is started. This session holds on to information about the user and the state of the
application. The state mainly consists of the result of the last browser query (see below) and to
a history of the queries that have been executed. Since such a session puts burdens on the web server, they are
usually timed out when they have been inactive for too long. This time is of the order of 5 minutes.
After a timeout a user will still be able to execute queries but history is no longer available and
also reformatting and plotting are no longer available. When this happens the user should enter the
web site anew from a new window.
NB Sessions are preserved through cookies, so this feature should be enabled for this web site.
Screen shots: upper part
Documentation
The Documentation link in this area leads to the help page area. The Credit/Acknowledgment link
leads to a page stating the credits one should make when using the results published through these pages.
Public Databases
The tree of public databases provided links to documentation of the tables, views and other useful database objects.
One of the databases in this list, or possibly in the following list of protected databases will be labelled with
"(context)". What this means is that in queries one does not need to write the name of the database in
front of the table and possible schema name
(see the page on T-SQL
for details).
MyDB databases
This area shows when a user has an account and through this access to protected databases.
In this part of the menu we do (currently) not list the tables and other possible objects of
a database. To get access to them one should click on the database and follow links from the page that appears then.
The "(r)" or "(rw)" after a database indicates whether a user has only read, or also write permissions on the
database.
Query Area
This is the area where one enters and executes the SQL statements.
Queries should not contain any comments, which in SQL are indicated by two hypens,
"--" in front of the comment.
There are two modes of executing queries on the GAVO web sites, indicated by the two different
"Query" buttons. The first, "Query (stream)", puts the least burden on the server in that results of
the queries are returned to the web browser as soon as they arrive from the database. This in contrast
to the "Query (browser)" button, which causes the complete result to be cached on the server. The
advantage of this is that further action on these results is more easily executed, such as plotting
and reformatting (see below). The query does not have to be re-executed
when a user selects on of those. The disadvantage is the obvious memory overhead on the server.
For that reason such queries have a limit on the number of rows that the query can return as indicated
in the text above the query panel. In general the streaming queries do not have such a limit.
This web interface does not allow one to interrupt/cancel a query after it has been submitted.
For this reason both query modes have a query timeout that is rather restrictive. Queries that exceed
this time are cancelled. It is otherwise too easy to clog the server with requests, whether by accident
or on purpose.
Plans are underway to provide batch support ala CAS-Jobs
on the SDSS SkyServer. This will allow more control on the execution scheduling of queries and allow
longer queries.
The drop down in this area limits the number of rows that will be returned in browser query mode
as HTML to the client. A subsequent reformat or plot request will have access to the whole result.
To limit the number of rows the database returns can be done in
SQL itself.
Previous Queries
All queries that have been executed during the course of a given session are
stored in a history and can be retrieved in two different ways. The drop down contains them all and selecting one
will automatically put the given query in the query window. Alternatively one can click the "Show All"
button, which will open a new window containing all the queries. Refreshing that window will reload
it, but beware of the issues mention in the paragraph on sessions above.
Demo Queries
Clicking on one of the "demo query" buttons will make the corresponding query appear in the main
query window for execution. They are intended to show various features of the databases.
They are documented here.
Metadata Queries
The buttons in this area, which is only avilable on the page if the user has logged in to her/his
account, has example statements for querying the metadata of a database, or possibly even to update
the database. These are documented here.
Screen shots: query result
Whan a query in "browser" mode has beene xecuted succesfully the result will be shown as an HTML table
in the bootom of the screen. The follwoing figure shows an example screen shot of that part. It is described below.
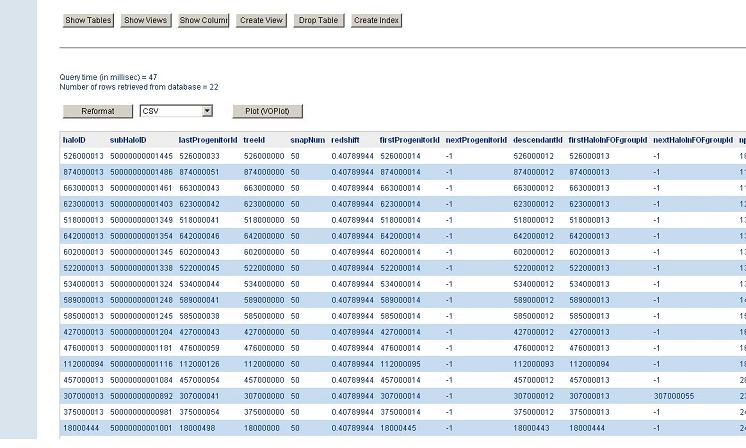
The main result is shown in the table, with column names corresponding to the SELECT part of
the sql query. At most as many rows are shown as was requested in the corresponding drop down inthe
query area.
The main functionality of this area has to do some postprocessing on the result.
In general this query mode is for demonstration/illustration purposes only, but sometimes these are useful.
Reformat
Clicking the "Reformat" button will produce the complete query result in the format
indicated by the drop down. It will do so in a separate window.
Plot (VOPlot)
The result can also be visualised using the VOPlot utility as an applet.
This function should be used with some care. VOPlot requires the format in VOTable form, which is rather
wordy and when loaded into the browser can take up more memory than the browser can handle.
So for large result sets, whether in rows or columns, one should take care.
|
4.2 : Data Formats
| (top) (separate page) |
|
The results of queries to the database can come in a number of formats.
The two main ones are the HTML table format that is produced using the "Query(browser)" button
on the query page,
and the comma-separated-values (CSV) format that is returned by default when the "Query (stream)"
button is clicked.
Other formats are available after the HTML table has been retrieved using the "Reformat"
button on the web page. The most interesting of these is the VOTable format, the others are variants of the
CSV format, using seperators different from the ",". The most important datatype though is the CSV datatype and we describe that here.
CSV
We provide comma-separated values in a particular form, with a header section that
provides metadata about the result. We will describe them based on different yypes of results.
For queries that produce a result and have no problems a typical result will look as follows.
#OK
#SQL= select top 10 *
# from mfield..snapshots
#MAXROWS UNLIMITED
#QUERYTIMEOUT 420 sec
#DATE 2009-03-31 11:40:53.853 CEST
#QUERYTIME 2 millisec
#COLUMN 1 name=snapNum JDBC_TYPE=4 JDBC_TYPENAME=int
#COLUMN 2 name=Z JDBC_TYPE=7 JDBC_TYPENAME=real
#COLUMN 3 name=redshift JDBC_TYPE=3 JDBC_TYPENAME=decimal
#COLUMN 4 name=lookbackTime JDBC_TYPE=7 JDBC_TYPENAME=real
snapNum,Z,redshift,lookbackTime
0,127.0,127.00,13.5672
1,79.997894,80.00,13.5551
2,49.99959,50.00,13.5305
3,30.000063,30.00,13.4761
4,19.91569,19.92,13.3929
5,18.243723,18.24,13.368
6,16.724525,16.72,13.3403
7,15.343074,15.34,13.3093
8,14.085914,14.09,13.2748
9,12.94078,12.94,13.2365
#OK
#OK in the first line indicates that the SQL query was accepted and executed by the database.
The actual SQL statement is repeated next, together with some configuration information(#MAXROWS and
#QUERYTIMEOUT).
The timestamp at which the query was handled is added in the line starting with
#DATE. The #QUERYTIME indicates the time between issuing the query and receiving the
first response from the database. This is not necessarily the same as the total time it
takes to handle the complete result. For simple queries with large result sets it may take much longer
than that before all results are returned.
The follow lines starting with #COLUMN that describe the columns in the result, e.g.
#COLUMN 1 name=snapNum JDBC_TYPE=4 JDBC_TYPENAME=int
The integer directly following the #COLUMN indicates the order.
then follows the name of the column. The datatype finally is represented in two different
ways. The JDBC_TYPE attribute gives an integer atht corresponds to the JDBC type in the
java.sql.Types
class in the Java Database Connection Specification. The JDBC_TYPENAME gives the name of that type
as decided by the JDBC implementation. The official mapping between the JDBC_TYPE and the JDBC type is as indicated in the following table
| BIT | -7 |
| TINYINT | -6 |
| SMALLINT | 5 |
| INTEGER | 4 |
| BIGINT | -5 |
| FLOAT | 6 |
| REAL | 7 |
| DOUBLE | 8 |
| NUMERIC | 2 |
| DECIMAL | 3 |
|
| CHAR | 1 |
| VARCHAR | 12 |
| LONGVARCHAR | -1 |
| DATE | 91 |
| TIME | 92 |
| TIMESTAMP | 93 |
| BINARY | -2 |
| VARBINARY | -3 |
| LONGVARBINARY | -4 |
| NULL | 0 |
|
| OTHER | 1111 |
| JAVA_OBJECT | 2000 |
| DISTINCT | 2001 |
| STRUCT | 2002 |
| ARRAY | 2003 |
| BLOB | 2004 |
| CLOB | 2005 |
| REF | 2006 |
| DATALINK | 70 |
| BOOLEAN | 16 |
|
The first line not starting with a # repeats the column names, separated by a comma.
Many CSV readers use this line to name the columns.
Then follow the data itself. In case a column has a string-like datatype (CHAR, VARCHAR etc), the values
are contained in double quotes ("..."). This is so that possible commas in such string values are not
interpreted as separators. In case the string value itself contains a double quote, that double quote is doubled.
I.e. " → "".
The final line reads #OK.
This indicates that the complete result is succesfully retrieved.
More importantly, if it is missing this is an indication that the result is most likely not complete.
This can have many possible casues. Some of these can be caught by the server, that then may return instead a line
starting with #ERROR (see below). But in theory other problems can occur, such as loosing the connection
somewhere between the client and the server.
Certain statements do not return a result and the CSV result is slightly different. For example
#OK NO RESULT
#SQL= select *
# into mysnapshots
# from millimil..snapshots
#MAXROWS UNLIMITED
#QUERYTIMEOUT 420 sec
#DATE 2009-03-31 13:34:48.875 CEST
#QUERYTIME 16 millisec
#UPDATE_COUNT=-1
#OK
Here the succesful execution is indicated by a #OK NO RESULT.
As there is no result there are no columns to describe. The only extra information comes in
the #UPDATECOUNT, which indicates how many rows were inserted in the database, with
-1 indicating that no rows were updated.
NOTE the -1 in the example above is incorrect !
It is a "feature" of the JDBC software that we are still using that in combination with SQLServer 2005
falsely indicates that no rows were inserted when using a SELECT .. INTO .. statement.
If instead a CREATE TABLE MyTable .. is followed by an
INSERT INTO MyTable .. rows are properly counted.
The following results show how errors are indicated.
#ERROR SQL
#SQL= select *
# from millimil..snapshot
#MAXROWS UNLIMITED
#QUERYTIMEOUT 420 sec
#DATE 2009-03-31 13:56:06.656 CEST
#SQLSTATE S0002
#SQLERRORCODE 208
#SQLEXCEPTION =Invalid object name 'millimil..snapshot'.
In most cases the error will result from incorrect SQL. This is indicated by the
#ERROR SQL on the first line.
After the #DATE there are now various lines giving some information about
the error. In particular the last line, starting with #SQLEXCEPTION replicates
the error message retrieved from the database.
Other errors will be indicated similarly. A special case is when the error is caused by a timeout.
This may happen after results have been obtained and sent to the client already.
In that case an error message will be appended after the last data row that is sent.
|
4.3 : wget
| (top) (separate page) |
|
Clicking the Query (csv) button on the web interface
with the example query in the figure on that page is equivalent in action to the following URL:
http://gavo.mpa-garching.mpg.de/Millennium?action=doQuery&SQL=select top 10 * from millimil..mmhalo.
This example returns the following result:
#OK
#SQL= select top 10 haloid,snapnum, x,y,z,np from millimil..mmhalo
#MAXROWS UNLIMITED
#QUERYTIMEOUT 420 sec
#COLUMN 1 name=haloid JDBC_TYPE=-5 JDBC_TYPENAME=bigint
#COLUMN 2 name=snapnum JDBC_TYPE=4 JDBC_TYPENAME=int
#COLUMN 3 name=x JDBC_TYPE=7 JDBC_TYPENAME=real
#COLUMN 4 name=y JDBC_TYPE=7 JDBC_TYPENAME=real
#COLUMN 5 name=z JDBC_TYPE=7 JDBC_TYPENAME=real
#COLUMN 6 name=np JDBC_TYPE=4 JDBC_TYPENAME=int
haloid,snapnum,x,y,z,np
0,63,6.5757904,13.08604,25.33813,51984
1,62,6.587909,13.099106,25.301092,51288
2,61,6.597178,13.111782,25.252974,51052
3,60,6.615912,13.121013,25.204876,51169
4,59,6.6276503,13.1303835,25.152872,50870
5,58,6.6414022,13.1400175,25.09534,50468
6,57,6.658701,13.149509,25.03174,50168
7,56,6.642237,13.170146,24.927555,50485
8,55,6.6424794,13.18374,24.83325,49888
9,54,6.6978354,13.176765,24.781622,48275
The format of this result is explained here.
What this implies is that users could conceivably avoid using the web interface and instead construct the URL
and use their favorite way of accessing the web passing in the URL. One standard way is via the command line function wget
(e.g GNU wget.
The following command will return the above result to standard out:
wget "http://gavo.mpa-garching.mpg.de/Millennium?action=doQuery&SQL=select top 10 haloid,snapnum, x,y,z,np from millimil..mmhalo"
To store the results in a file named "result.csv" use:
wget -O result.csv "http://gavo.mpa-garching.mpg.de/Millennium?action=doQuery&SQL=select top 10 haloid,snapnum, x,y,z,np from millimil..mmhalo"
When a log-in is required, like for the protected site
http://gavo.mpa-garching.mpg.de/MyMillennium,
one needs to change the command to something like:
wget --http-user=**** --http-passwd=**** "http://gavo.mpa-garching.mpg.de/MyMillennium?action=doQuery&SQL=select top 10 haloid,snapnum, x,y,z,np from millimil..mmhalo"
Session tracking
The nice feature of wget, that it can be used from within scripts, now and then causes problems as well.
Now and then the load on our web server has been very large, which could be tracked down to users sending
large numbers of relatively small queries using wget.
The problem is that the web server creates a session for every request that is posed to it, unless it
is recognised as belonging to a previous session. We use the standard way of tracking sessions using
cookies and web browsers will handle this properly.
Without extra work, wget, used as documented above does not enable this session tracking.
As sessions have a finite lifetime, sending large numbers of queries can now clog up the web server.
As of version 1.10 of wget it is possible to enforce session tracking.
The following example command shows how:
wget --http-user=**** --http-passwd=***
--cookies=on --keep-session-cookies --save-cookies=cookie.txt --load-cookies=cookie.txt -O out.csv
"http://gavo.mpa-garching.mpg.de/MyMillennium?action=doQuery&SQL=select top 10 * from mpagalaxies..delucia2006a"
The new features are the various cookie parameters.
The file name after --save-cookies and --load-cookies should be the same and may have to be fully
qualified if you run this from within an environment such as IDL. What this does is that it writes
the cookie info that comes back from the server, and reads it again upon next execution. This allows
the server to work within a single session. Please also consult your local manual on wget
(if you can find it) for more information.
Please use this pattern when querying using wget.
For other options, see the command line options of wget.
URL encoding
The fact that we are creating a URL implies we must beware for some URL encoding issues.
In particular we must beware for using characters in the SQL that are interpreted as special
characters in a URL. An example of this is the + (plus) sign,
which is interpreted as a space. So a query like
select x+y from millimil..mpahalo
will cause an error, unless encoded as
select x%2By from millimil..mpahalo
The next few pages show ways using the wget command form
within environments such as R and
ITT's IDL.
|
4.4 : Interfacing R with the Millennium Database
| (top) (separate page) |
|
R "... is a free software environment for statistical computing and graphics.
It is the open source version of the commercial statistical software package S.
See the Comprehensive R Archive Networka>
for documentation and downloads for R.
We mention R here because it allows very easy access to the Millennium database via the GAVO web application.
The following R function uses wget to execute an SQL query and load the result directly into the environment,
i.e. one does not need to write the result to file to get hold of it.
#
# This function executes the specified SQL query on a GAVO website
#
# Warning, no sophisticated error handling, caller must check result
#
gavoWebQuery <- function(url="http://gavo.mpa-garching.mpg.de/Millennium?", user="", password="", sql)
{
url<-paste(url,"SQL=",sep="")
cmd<-paste("wget --quiet --http-user=",user," --http-passwd=",password," -O - \"",url,sql,"\"",sep="")
res<-system(cmd,intern=TRUE)
if(length(res) == 0)
result = "ERROR check your web address, user or password"
else {
if(res[1] == "#OK")
result<-read.csv(textConnection(res), colClasses="character")
else
result<-res
}
result
}
The following is an example R session using the above function with a query returning the merging history of
a galaxy identified by its ID. For this public URL there is no user and password required.
sql<-"
select p.*
from millimil..mmgalaxy d
, millimil..mmgalaxy p
where d.galaxyid = 0
and p.galaxyid between d.galaxyid and d.lastprogenitorid
order by p.galaxyid
"
result<-gavoWebQuery(url=webAppUrl, sql=sql)
plot(result$x, result$snapnum)
The result of this session is visualised in the following figure:
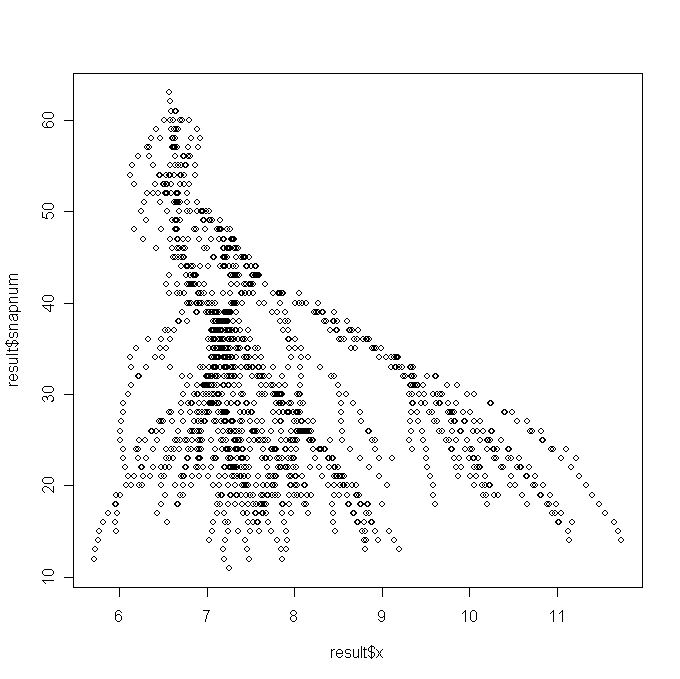
|
4.5 : Interfacing IDL with the Millennium Database
| (top) (separate page) |
Here we provide some simple IDL scripts, created by Ben Panter, to interface with the databases
using the wget method.
Help is available here.
Latest versions:
query_sql_str.pro
query_sql.pro
SQL_QUERY.zip file including help
Instructions:
This program interfaces witht the GAVO Millennium / SDSS servers to
perform SQL queries and parse the results into IDL structs.
To use, put your query in a string:
IDL> query = 'select * from agebin'
then run the search:
IDL> result = query_sql_str(query)
You'll need to login for the first query of each session, but shouldn't after that.
If you have the wrong login details and need to replace them, simply type /login as
a keyword when you call query_sql:
IDL> result = query_sql_str(query, /login)
If you're using a different database, you may need to supply the URL of a seperate server. Something like:
IDL> result = query_sql_str(query, server='http://gavo.mpa-garching.mpg.de/MyMillennium')
Note that there is no final slash on the URL!
The code automatically chooses the tag names of the structure to reflect the field names
returned by the query. If there are duplicates, it appends the number of the field to the
end of the tag name. If this is not the format you require, or if the variable formatting is
incorrect, you can supply a base struct to be replicated using the my_struct=.... keyword.
The mystruct structure must have the same number of tags as the query returns. A simpler approach is to supply column names in your query, hence
select alice.specobjid, bob.specobjid
becomes
select alice.specobjid as a_id, bob.specobjid as b_id
If you find that your query is not as long as you expected it is possible the server timed
out before completion. In this case supply a variable for the truncated keyword. This will allow
you to inspect the last completed line of the query and resubmit with that as a condition when
combined with a sort command
result = query_sql_str('select * from agebin', truncated=truncated)
The truncated variable now contains the last line recovered. If the query included a statement to sort on the first column it can be resubmitted starting at the record after that.
keywords:
- server - Change the server from the default value to something else (this can be changed permanently in sql_query.pro if desired)
- login - Force a new attempt at logging in.
- no_cookies - Do not use cookies to maintain a session on the server. For compatability with early wget versions
- my_struct - supply you own struct to avoid problems with incorrect format guessing or provide your own field names
- truncated - this allows you to read the last complete line if a query was truncated due to a time out. You may then resumbit the query using that information if your original query included a sort statement.
- quiet - suppresses any messages to the shell, both by IDL and wget.
The codes are always evolving as we trace more bugs or improve functionality.
To check for updates refer to the 'version' line in your own version
and the version here.
Caveats:
There is no concept of null in IDL. If a query returns null it will be interpreted as
0.0000. We welcome suggestions for an alternative way to do this.
If you intend to use non HTTP compliant characters in your query, you must encode them. A guide to encoding is given on wikipedia. Should this page become unavailiable, a websearch on Percent Encoding should provide a list. In particular, + should be encoded %2B and / %2F.
|
4.6 : TOPCAT Access to the Millennium Database
| (top) (separate page) |
|
An alternative to the remote access methods on the previous pages is to use Mark Taylor's
TOPCAT tool that was originally
developed for StarLink.
TOPCAT is a VO aware, interactive visualisation toolkit.
It is similar in philosophy to the VOPlot tool that is available as an applet off the main web interface.
TOPCAT is written in Java and runs as a standalone program on any machine that has a Java Run Time Environment installed.
The tool can be downloaded on the indicated links in either a full or a lite version.
The tool can read tabular files in various formats, including CSV, as long as there is at most a single header
line with column names on top. It could therefore conceivably be used on the result of a wget query, as long
as the comment lines are stripped on before reading into TOPCAT.
With a lot of help of Mark Taylor, GAVO has written a Java plug-in to the TOPCAT tool that allows users to query the
GAVO Millennium web site directly and loads the results into TOPCAT for visualisation.
Since version 3.3 of TOPCAT this plugin is part of the TOPCAT distribution.
When clicking the "Open file" button or menu item an special
button is available, that, when clicking, allows the user to write an SQL query and send it to
the appropriate web application. The button is indicated in red in the following figure.
Clicking this button opens a query dialogue:
Once the query is executed the result is automatically loaded into the tool and is available for plotting:
Nice features of TOPCAT are its 3D capabilities and that one can assign color based on a column:
|
5 : Quick start: demo queries, tutorial(s)
| (top) (separate page) |
|
Here we provide a large number of example SQL queries tailored to the Millennium databases.
These are meant as examples for learning SQL and the database schema at the same time.
The generic queries are the ones available under the demo query buttons on the main web page.
As an example of what could constitute a complete SQL session we provide queries that reproduce
the (content of the) figures in
De Lucia & Blaizot 2006.
This area of the documentation will be under continuous construction, as we plan to add here interesting
SQL solutions that allow particular questions to be answered efficiently.
We invite users to submit some of these, possibly after publication of a paper.
A tutorial on SQL and the Millennium database in the form of a Microsoft power-point presentation is available from
this link.
|
5.1 : Generic Queries
| (top) (separate page) |
|
On this page we document the demo queries available behind the corresponding buttons
on the main query page. All these demo queries address the various tables in the millimil database.
The following list gives quick links to the corresponding query.
H1
Find halos at a given redshift (snapnum) within a certain part of
the simulation volume (X,Y,Z).
select *
from millimil..MPAHalo
where snapnum=50
and np between 100 and 1000
and x between 10 and 20
and y between 10 and 20
and z between 10 and 20
|
H2
Find the whole progenitor tree, in depth-first order, of a halo identified by its haloId
select PROG.*
from millimil..MPAHalo PROG,
millimil..MPAHalo DES
where DES.haloId = 1
and PROG.haloId between DES.haloId and DES.lastprogenitorId
|
H3
Find the progenitors at a given redshift (snapnum) of all halos of mass(np)≥4000 at a later redshift (snapnum). The progenitors are limited in mass as well.
select DES.haloId as descendant_id,
DES.np as descendant_mass,
PROG.*
from millimil..MPAHalo DES,
millimil..MPAHalo PROG
where DES.snapnum = 63
and DES.np > 4000
and PROG.haloId between DES.haloId and DES.lastprogenitorId
and PROG.snapnum = 30
and PROG.np > 100
order by DES.np desc, PROG.np desc
|
H4
Find all the halos of mass ≥ 1000 that have just had a major merger, defined by having at least two progenitors of mass ≥ 0.2*descendant mass.
Note that this uses the mass of the sub-halos just prior to merging.
In general the minor partner in a merger will have been stripped of part of its mass prior tpo the actual merger,
so this mass ratio may not properly reflect the actual ratio when the merger commenced.
See paper by Bundy, Ellis & Treu (2006, ads) .
select D.haloId,
D.snapnum,
D.np as d_np,
P1.np as p1_np,
P2.np as p2_np
from millimil..MPAHalo P1,
millimil..MPAHalo P2,
millimil..MPAHalo D
where P1.SNAPNUM=P2.SNAPNUM
and P1.haloId < P2.haloId
and P1.descendantId = D.haloId
and P2.descendantId = D.haloId
and P1.np >= .2*D.np
and P2.np >= .2*D.np
and D.np > 1000
|
H5
Find the mass function of halos at z=0 using logarithmic intervals.
Note the use of the group by [expression] statement.
This groups all rows in the possible result of the SELECT .. FROM .. WHERE .. that have the same value
for the [expression] and for each group calculates an aggregate function, here the count(*).
NOTE this is not exactly equivalent to a histogram, as only bins for which there is at least one row before the binning will be returned.
I.e. when using the result of a query like this in a diagram one should beware of possibly missing bins, and not simply "connect the dots"!
select power(10, .1*(.5+floor(log10(np)/.1))) as mass,
count(*) as num
from millimil..MPAHalo
where snapnum=63
group by power(10, .1*(.5+floor(log10(np)/.1)))
order by mass
|
HF1
Find all halos residing in background overdensities between 2 and 3, at Gaussian smoothing radius 5 Mpc/h.
select h.*
from millimil..MPAHalo h,
millimil..MMField f
where f.g5 between 2 and 3
and f.snapnum=63
and f.snapnum = h.snapnum
and f.phkey = h.phkey
|
HF2
This query calculates conditional multiplicity functions
of halos in two different environments defined by different values for the
dark matter desntiy after Gaussian smoothing of 5/h Mpc.
The query consists of two nearly identical parts combined using a union. A union
simply adds the rows coming from both parts together in one result. Note that to identify from which
of these two a row in the result is returned, a special column (here called "lim") is added
which has value 0 for the first part, 1 for the second. We assigne these values in a slightly cumbersome way,
namely as 0*haloId and 0*haloid+1 respecitvley. This is due to a "feature" of
T-SQL which does not allow "group by" on literals.
The multiplicity functions themselves are determined in a way that is equivalent to the example in
H5. See there also for a note on missing bins.
select 0*haloId as lim,
power(10, .1*(.5+floor(log10(h.np)/.1))) as mass,
count(*) as num
from millimil..MMHalo h,
millimil..MMField f
where f.g5 between 3 and 5
and f.snapnum=63
and f.snapnum = h.snapnum
and f.phkey = h.phkey
group by 0*haloId, power(10, .1*(.5+floor(log10(h.np)/.1)))
union
select 0*haloId+1 as lim,
power(10, .1*(.5+floor(log10(h.np)/.1))) as mass,
count(*) as num
from millimil..MMHalo h,
millimil..MMField f
where f.g5 between .2 and .4
and f.snapnum=63
and f.snapnum = h.snapnum
and f.phkey = h.phkey
group by 0*haloId+1, power(10, .1*(.5+floor(log10(h.np)/.1)))
order by lim,mass
|
HF3
Find formation time dependency on background overdensities for halos in particular mass bin.
select zmax, avg(g5) as g5, stdev(g5) as g5err,
avg(g10) as g10, stdev(g10) as g10err,
count(*) as num
from millimil..mmfield f,
( select des.haloId, des.np, des.phkey,max(PROG.redshift) as zmax
from millimil..MPAHalo PROG,
millimil..MPAHalo DES
where DES.snapnum = 63
and PROG.haloId between DES.haloId and DES.lastprogenitorId
and prog.np >= des.np/2
and des.np between 100 and 200
and des.haloId = des.firsthaloinfofgroupid
group by des.haloId, des.np ,des.phkey
) t
where t.phkey = f.phkey
and f.snapnum=63
group by zmax
|
G1
Find galaxies at a given redshift (snapnum) within a certain part of the simulation volume (X,Y,Z)
select *
from millimil..DeLucia2006a
where snapnum=63
and mag_b between -26 and -18
and x between 10 and 20
and y between 10 and 20
and z between 10 and 20
|
G2
Find the whole progenitor tree, in depth-first order, of a galaxy identified by its galaxyId
select PROG.*
from millimil..DeLucia2006a PROG,
millimil..DeLucia2006a DES
where DES.galaxyId = 1
and PROG.galaxyId between DES.galaxyId and DES.lastprogenitorId
|
G3
Find the progenitors at a given redshift (snapnum) of all galaxies of brightness(magB) ≤ -20 at a later redshift (snapnum). The progenitors are limited in magnitude as well.
select DES.galaxyId as descendant_id,
DES.stellarMass as descendant_mass,
PROG.*
from millimil..DeLucia2006a DES,
millimil..DeLucia2006a PROG
where DES.snapnum = 63
and DES.mag_b < -20
and PROG.galaxyId between DES.galaxyId and DES.lastprogenitorId
and PROG.snapnum = 30
and PROG.mag_b < -19
order by DES.mag_b asc, PROG.mag_b asc
|
G4
Find all the galaxies of mag_b < -20 that have just had a major merger, defined by having at least two progenitors of mass ≥ 0.2*descendant mass.
select D.galaxyId,
D.snapnum,
D.mag_b as d_mag_b,
D.sfr as d_sfr,
P1.mag_b as p1_mag_b,
P2.mag_b as p2_mag_b,
D.stellarMass as d_mass,
P1.stellarMass as p1_mass,
P2.stellarMass as p2_mass
from millimil..DeLucia2006a P1,
millimil..DeLucia2006a P2,
millimil..DeLucia2006a D
where P1.SNAPNUM=P2.SNAPNUM
and P1.galaxyId< P2.galaxyId
and P1.descendantId = D.galaxyId
and P2.descendantId = D.galaxyId
and P1.stellarMass >= .2*D.stellarMass
and P2.stellarMass >= .2*D.stellarMass
and D.mag_b <-20
|
G5
Find the luminosity function of galaxies at z=0.
Note the comment for query H5 regarding missing bins.
select .2*(.5+floor(mag_b/.2)) as mag,
count(*) as num
from millimil..DeLucia2006a
where mag_b < -10
and snapnum=63
group by .2*(.5+floor(mag_b/.2))
order by mag
|
G6
Find the Tully-Fisher relation, Mag vs Vvir for galaxies with bulge/total mass ratio < 0.1.
select vVir, mag_b, mag_v, mag_i, mag_r, mag_k
from millimil..DeLucia2006a
where (bulgeMass < 0.1*stellarMass or bulgeMass is null)
and snapnum = 41
|
HG1
Find the conditional luminosity functions for galaxies in two ranges of halo masses.
Note the comment for query H5 regarding missing bins.
select 0*galaxyId as lim,
.2*(.5+floor(mag_b/.2)) as mag,
count(*) as num
from millimil..DeLucia2006a g,
millimil..MPAHalo h
where h.np between 2000 and 3000
and h.snapnum=63
and g.haloId = h.haloId
and g.mag_b < 0
group by 0*galaxyId, .2*(.5+floor(mag_b/.2))
union
select 0*galaxyId+1 as lim,
.2*(.5+floor(mag_b/.2)) as mag,
count(*) as num
from millimil..DeLucia2006a g,
millimil..MPAHalo h
where h.np between 200 and 300
and h.snapnum= 63
and g.haloId = h.haloId
and g.mag_b < 0
group by 0*galaxyId+1, .2*(.5+floor(mag_b/.2))
order by lim, mag
|
HG2
Find average galaxy properties as function of halo mass.
select pow(10, .1*(.5+floor(log(g.np)/.1)))::real as halo_np,
avg(g.stellarMass) as stars_avg,
max(g.stellarMass) as stars_max,
avg(g.bulgeMass) as bulge_avg,
max(g.bulgeMass) as bulge_max,
avg(g.mag_b-g.mag_v) as color_avg
from millimil..DeLucia2006a g
where g.snapnum= 63
and g.mag_b < 0
group by halo_np
order by halo_np
|
GF1
Find galaxy luminosity functions in overdensities at two different values.
select 0*galaxyId as lim,
.2*(.5+floor(mag_b/.2)) as mag,
count(*) as num
from millimil..DeLucia2006a g,
millimil..MMField f
where f.g5 between 3 and 5
and f.snapnum=63
and f.snapnum = g.snapnum
and f.phkey = g.phkey
and g.mag_b < 0
group by 0*galaxyId, .2*(.5+floor(mag_b/.2))
union
select 0*galaxyId+1 as lim,
.2*(.5+floor(mag_b/.2)) as mag,
count(*) as num
from millimil..DeLucia2006a g,
millimil..MMField f
where f.g5 between .2 and .4
and f.snapnum=63
and f.snapnum = g.snapnum
and f.phkey = g.phkey
and g.mag_b < 0
group by 0*galaxyId+1, .2*(.5+floor(mag_b/.2))
order by lim, mag
|
|
5.2 : De Lucia & Blaizot 2006
| (top) (separate page) |
|
The contents of this part of the documentation is UNDER CONSTRUCTION.
Please come back later.
|
5.3 : Boylan-Kolchin etal 2009
| (top) (separate page) |
|
We here present SQL queries that produce results that are equivalent to those used to produce
various figures in
Boylan-Kolchin et al 2009.
Figure 4
The figure compares conditional mass functions for subhalos as function of the mass of the FOF group they belong to.
We use the user's MyDB to store temporary results.
The first query counts subhalos grouped in mass bins that reside in FOF groups also already grouped in bins.
I.e. it calculates all conditional mass functions for all desired FOF mass ranges in one query.
We use logarithmic bins and use the number of particles multiplied by the mass per particle as estimate of the mass.
We make use of the structure we have imposed on the identifiers for sub-halos and FOF groups as described in
[TODO add link].
Note that we count subhalos that are not the central (first) subhalo.
select .5*floor(log10(f.np*6.885e-4)/.5) as mfof
, .1*floor(log10(s.np*6.885e-4)/.1) as msh
, count(*) as num
into fullmassfun_67
from millenniumii..fof f
, millenniumii..subhalo s
where f.snapnum=67
and s.subhaloid between 1000000*f.fofid+1 and (f.fofid+1)*1000000-1
group by .5*floor(log10(f.np*6.885e-4)/.5)
, .1*floor(log10(s.np*6.885e-4)/.1)
We use this table to calculate a cumulative mass function.
select f1.mfof, f1.msh, sum(f2.num) as numcum
into cummassfun_67
from fullmassfun_67 f1
, fullmassfun_67 f2
where f1.mfof=f2.mfof
and f2.msh >= f1.msh
group by f1.mfof, f1.msh
Figure 4 in the paper shows the normalised result.
The numbers in the cumulative mass function for a given mass range of the FOF groups
must be divided by the number of FOF groups in that bin.
To do so we first must calculate those bins:
select .5*floor(log10(np*6.885e-4)/.5) as mfof
, count(*) as num
into fofmassfun_nsubsgt1_67
from millenniumii..fof
where snapnum=67
and numsubs > 1
group by .5*floor(log10(np*6.885e-4)/.5)
The result finally is obtained form the following query:
select cf.mfof, cf.msh, cast(cf.numcum as real)/f.num as frac, f.num
into cummassfunnorm_67
from fofmassfun_nsubsgt1_67 f
, cummassfun_67 cf
where f.mfof=cf.mfof
|
6 : Frequently Asked Questions
| (top) (separate page) |
Here some generic questions about the web site and about relational database technology.
For questions about the databases follow the links above.
This page will be updated with new questions form users when they come in.
Web site
- What is the difference between the "Query (stream)" and "Query (browser)" buttons?
The former returns data in comma-separated-values (CSV) format and in general puts no limit on the
number of rows that can be returned. The "Query (browser)" button produces a result that
is returned as an HTML table to the web page. It stores this result also on the server so that
when the user wants to visualise the result using VOPlot or reformat the result we do not have to execute the query again.
For this reason the total size of the result is limited to a maximum number of rows.
- Why are there timeouts and why are they so short?
Our resources are limited and we want to ensure that queries do not run forever.
It is easy to write such queries by mistake and as long as users can not cancel such queries we want to
ensure that they do not have to wait overly long before the next query can be posed.
- ...
- Why do I get these weird "Bad gateway!" error messages?
Some requests produce, after some time, an error message containing text similar to the following:
Bad Gateway! The proxy server received an invalid response from an upstream server. ...
The likely cause of this is that instead of the database timing out, somewhere on the HTTP trail between
the user machine and the database an HTTP server or proxy has decided that the user session has been idle too long
and has timed out the connection. This can happen if the query sent to the database is not producing any results for
the time it takes one of these servers to time out. Many servers use relatively short time outs, such as 5 minutes.
I.e. even shorter than the database timeout we impose. This is one (more) reason why a batch queue for query processing
would be a useful thing to have.
It is sometimes possible to avoid this. One way is not to use "order by" for example. Such queries can sometimes
only produce results once the database has retrieved all rows, which may take too long. Not though that the difference
between 5 and 7 minutes is small enough that likely even without "order by" not all rows may be returned.
Relational databases
- What is a relational database?
google it
- Where can I learn more about SQL?
Google
- ...
|
6.1 : FAQ Millennium
| (top) (separate page) |
|
- Why have the ID columns such complex values?
The raw particle data for the Millennium Simulation was saved at 64 snapshots.
Each snapshot was distributed over 512 approximately equal-sized files.
At each snapshot, a friends-of-friends (FOF) groupfinder with linking length b=0.2 was run.
During post-processing, each FOF group was searched for bound substructure using the SUBFIND algorithm.
For each snapshot, there are 512 files that contain the results of SUBFIND.
Merger trees were built based on these subhalos.
The merger trees were split over 512 files, each of which contains approximately 14,000 trees.
In the design of the various tables, the structure of these files is retained in the subhalo (and FOF halo) IDs as follows:
- MPAHaloTrees..MHALO::haloId = 1012 * treeFile + 106 * (rank of tree in file) + (depth-first ordering of subhalo in tree)
- MPAGalaxies..Delucia2006a/Bertone2007a::galaxyId = 1012 * (halotreeFile) + 106 * (rank of tree in file) + (depth-first ordering of galaxy in tree)
- MField..FOF::fofID = 1012 * snapnum + 108 * fileNr + (rank in file)
- MField..FOFSubHalo::subhaloId = 1012 * snapnum + 108 * fileNr + (rank in file)
- DHaloTrees..DHalo::DHaloId = 1012 * treeFile + 108 * fileNr + (rank in file)
- DGalaxies..Bower2006a::galaxyId = 1014 * treeFile + 108 * (rank of tree in file) + (rank in file)
Note: the structure for the Millennium-II Simulation is different in the details!!!
- How do I work around timeouts?
A query times out most often because the database is asked to handle datasets that are so
large that the required disk I/O by itself exceeds the maximum allowed query time.
Very often there is a straightforward manner to work around this, at the costs of having to issue multiple queries.
Here as example how to deal with queries that will require a scan of the complete galaxies table.
Suppose a user would like to run the following query (arbitrary):
select *
from mpagalaxies..delucia2006a
where blackHoleMass > coldgas
and mag_b - mag_v between .2 and .8
For these constraints the database decides that a full scan of the delucia2006a table is required, which will time out.
An alternative is to run the following set of queries
select *
from mpagalaxies..delucia2006a
where galaxyid between :START*1e12 and (:START+:BIN)*1e12-1
and blackHoleMass > coldgas
and mag_b - mag_v between .2 and .8
where one should substitute integer values for the variables :START and :BIN.
For example with :BIN=1 and :START ranging from 0-511 one can sample the complete table in 512 separate queries,
something that can be easily coded in a script, using
wget for example for executing the query.
This works because the table is sorted on galaxyId and therefore the database can quickly ("in logarithmic time")
find the range of galaxies given by
the first constraint. As a consequence of the structure in the IDs described above this set
is about as large as the the millimil..delucia2006a table.
In general the :BIN size can easily be set to a higher value, 10 or possibly larger.
NB the -1 is required to ensure that consecutive bins are non overlapping: the BETWEEN clause is inclusive.
Why are queries using constraint on x,y,z so slow?
Queries requesting a subset of the full volume using constrints on the position often time out.
This page gives hints how to rewrite the queries using special purpose columns and associated indexes.
Can I get simulation particles?
The current database servers are not large enough to contain the full raw output of the Millennium simulaiton.
Howevere we have added the particles for the milli-Millennium simulaiton.
These are stored in the MMSnapshots database.
how do I get all particles for a FOF group?
The MMSnapshots database contains a table that links FOF groups and SubHalos to the particles they consist of.
This association is stored in the
MillimilSnapshotIDs table.
Note that not all particles are part of a FOF group, or SubHalo. And not all particles in a FOF gorup need to be
part of a subhalo. A query to get all particles for FOF groups of mass around 10000 particles would be:
select p.*
from millimil..fof fof
, mmsnapshots..millimilsnapshotids id
, mmsnapshots..millimilsnapshots p
where fof.np between 10000 and 10010
and fof.snapnum=63
and id.fofid = fof.fofid
and p.id = id.particleid
and p.snapnum=fof.snapnum
how do I get information about indexes in the DB?
In the future the index definitions will be part of the table documentation.
Until that time the following query returns all indexes for all tables in the Millennium-II database,
with the columns and the order these appear in the index. Note that this query ONLY works for the Microsoft
SQLServer database.
select o.name as table_name
, i.name as index_name
, c.name as column_name
, ic.key_ordinal as rank
from millenniumii.sys.tables o
, millenniumii.sys.indexes i
, millenniumii.sys.index_columns ic
, millenniumii.sys.columns c
where i.object_id = o.object_id
and ic.index_id = i.index_id
and ic.column_id = c.column_id
and ic.object_id = c.object_id
and c.object_id = o.object_id
order by table_name,index_name,rank
How do I find all FOF groups/sub-halos/galaxies at a given redshift?
All tables containing objects have a redshift column. BUT users should refrain from using this column in where clauses.
Instead they should use the snapnum column. The reason is that the tables are in general indexed on snpanum, and not on redshift.
The link between the two is stored in the
Snapshots table (available both in millimil and in MField).
So instead of writing
select * from mpagalaxies..delucia2006a where redhsift=0
one should use
select * from mpagalaxies..delucia2006a where snapnum=63
what is the difference between MPAHaloTrees and DhaloTrees?
The MPAHaloTrees database contains subhalo merger trees constructed according to an algorithm developed at MPA.
See this page for a description.
The DHaloTrees database contains merger trees constructed accroding to an algorithm developed in Durham,
see here.
Whereas the nodes in the MPA trees are individual SUBFIND sub-halos, the nodes in the Durham trees are "DHalo-s",
which may contain >1 subhalos.
The DSubHalo
table links the DHalo
to the SubHalo table
|
6.2 : FAQ Millennium II
| (top) (separate page) |
(also see http://www.mpa-garching.mpg.de/galform/millennium-II/data.html)
-
What is the difference between a halo and a subhalo?
There are two types of dark matter structures in the Millennium / Millennium-II databases: friends-of-friends (FOF)
halos and subhalos. The term "halo" in the documentation almost always refers to
subhalos.
While FOF halos better correspond to the standard picture of a virialized dark matter halo, subhalos are more easily
connected to galaxies. Each FOF halo may contain several subhalos
(see Springel et al. 2005 /
Boylan-Kolchin et al. 2009
for details on how FOF halos and subhalos were found in the Millennium / Millennium-II Simulations).
The merger trees in the Millennium-II database use subhalos as their fundamental unit;
as far as the merger trees are concerned, FOF halos only exist as a property of the subhalos (this is also true
for the MPAHaloTrees in the Millennium database but is not the case for the DHaloTrees).
While it is possible to construct FOF merger trees either based on the subhalo merger trees or directly from
the FOF halos, no such FOF merger trees currently exist in the Millennium-II database.
-
Why is the subhalo mass equal to zero even though it has over one million particles?
Only subhalos that are identified as FOF-dominant (those for which haloId=firstHaloInFOFgroupID) can have a
spherical overdensity mass associated with them. All non-FOF-dominant subhalos will have m_crit200, m_mean200,
and m_tophat identically equal to zero. The number of particles in the subhalo is still well-defined, however,
and this is the basis for the standard definition of a subhalo's mass.
-
There are almost no major mergers in the merger trees - what's wrong?
Mergers in the merger trees are mergers of subhalos. These subhalos may have been orbiting for several
dynamical times within a larger FOF halo and can lose substantial amounts of mass before merging. If you are
interested in the merger of FOF halos, there are several possibilities. One is to follow merging subhalos
backward in time until they reside in separate FOF halos; another is to find FOF-dominant subhalos with descendants
that reside in the same FOF halo.
-
Are there any structural differences between the Millennium and Millennium-II databases?
We have added a few new columns for the Millennium-II database that are currently not present for the Millennium database.
If these prove useful, we will update the Millennium database to include them.
The additional columns in the subhalo merger trees include the radius at which the peak circular velocity is reached
(vMaxRad), the mainLeafID (which allows easy extraction of the main progenitor branch of any subhalo),
a direct link to the host FOF halo for each subhalo via fofID, and a link to the rank of each subhalo within
its host FOF halo via subhaloId (as opposed to subhaloFileId; see below).
An important difference is the number of snapshots: 64 for Millennium (0-63), 68 for Millennium-II (0-67).
Note that for a given snapshot number, the corresponding redshift is different in the
Millennium Simulation than in the Millennium-II simulation. Please see the MField..Snapshots (Millennium)
and MIISnapshots (Millennium-II) tables for the relationship between snapshot number and redshift / expansion factor.
-
What is the nextProgenitorId?
The nextProgenitorId of subhalo S is a pointer to the next most massive subhalo that has the same descendant as subhalo S.
The nextProgenitorId pointer is NOT a pointer from a subhalo to one of its progenitors; it links subhalos that have
the same descendant. See the example
here
for a schematic view of several of the pointers in the merger trees,
including the nextProgenitorId.
-
Why are there so many different IDs? How do they help me?
The raw particle data for the Millennium-II Simulation was saved at 68
snapshots. Each snapshot is distributed over 512 approximately equal-sized
files. At each snapshot, a friends-of-friends (FOF) groupfinder with linking
length b=0.2 was run. During post-processing, each FOF group was searched for
bound substructure using the SUBFIND algorithm. For each snapshot,
there are 2048 files that contain the results of SUBFIND. Merger
trees were built based on these subhalos. The merger trees were split over 512
files, each of which contains approximately 14,000 trees.
In making the database, the structure of these files is retained in the subhalo
(and FOF halo) IDs as follows:
-
haloId = 1015 * treeFile + 109 * (rank of tree in file) + (depth-first
ordering of subhalo in tree)
-
fofID = 1010 * snapnum + 106 * fileNr + (rank in file)
-
subhaloId = 106 * fofID + (rank in FOF group)
-
subhaloFileId = 1010 * snapnum + 106 * fileNr + (rank in file)
Note: the structure for the Millennium Simulation is different!!!
Knowing this data structure can help in your queries. For example, suppose you are interested in finding all
subhalos beloning to the FOF group with a given fofID; this can be done trivially by selecting subhaloId between
106 * fofID and 106* (fofID + 1) - 1.
|
|